一场pandas与SQL的巅峰大战(三)
点击上方“超哥的杂货铺”,轻松关注
本文目录如下:

在前两篇文章中,我们从多个角度,由浅入深,对比了pandas和SQL在数据处理方面常见的一些操作。
具体来讲,第一篇文章一场pandas与SQL的巅峰大战涉及到数据查看,去重计数,条件选择,合并连接,分组排序等操作。
第二篇文章一场pandas与SQL的巅峰大战(二)涉及字符串处理,窗口函数,行列转换,类型转换等操作。您可以点击往期链接进行阅读回顾。
在日常工作中,我们经常会与日期类型打交道,会在不同的日期格式之间转来转去。
本文依然沿着前两篇文章的思路,对pandas和SQL中的日期操作进行总结,其中SQL采用Hive SQL+MySQL两种方式,内容与前两篇相对独立又彼此互为补充。一起开始学习吧!
◆ ◆ ◆ ◆ ◆
数据概况
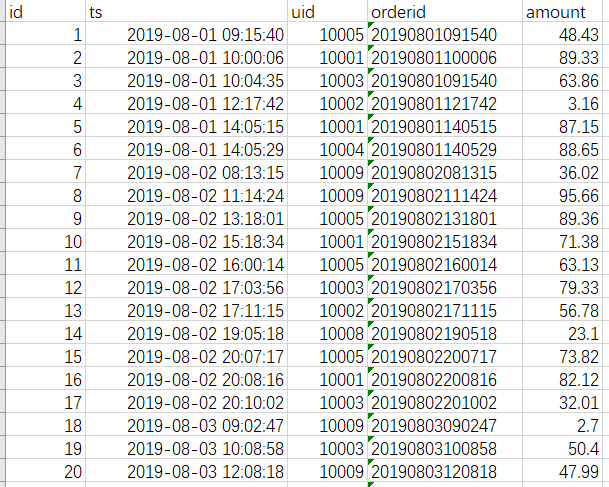
数据方面,我们依然采用前面文章的订单数据,样例如下。在正式开始学习之前,我们需要把数据加载到dataframe和数据表中。本文的数据、代码以及清晰的PDF版本可以在公众号后台回复“对比三”获取哦~
![]()
pandas加载数据
import pandas as pd
data = pd.read_excel('order.xlsx')
#data2 = pd.read_excel('order.xlsx', parse_dates=['ts'])
data.head()
data.dtypes
需要指出,pandas读取数据对于日期类型有特殊的支持。
无论是在read_csv中还是在read_excel中,都有parse_dates参数,可以把数据集中的一列或多列转成pandas中的日期格式。
上面代码中的data是使用默认的参数读取的,在data.dtypes的结果中ts列是datetime64[ns]格式,而data2是显式指定了ts为日期列,因此data2的ts类型也是datetime[ns]。
如果在使用默认方法读取时,日期列没有成功转换,就可以使用类似data2这样显式指定的方式。
![]()
MySQL加载数据
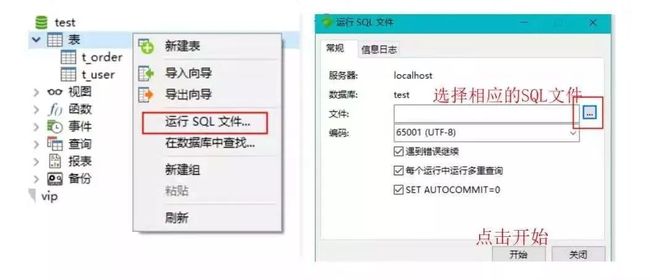
我准备了一个sql文件t_order.sql,推荐使用navicate客户端,按照上图所示方式,直接导入即可。
![]()
Hive加载数据
create table `t_order`(
`id` int,
`ts` string,
`uid` string,
`orderid` string,
`amount` float
)
row format delimited fields terminated by ','
stored as textfile;
load data local inpath 't_order.csv' overwrite into table t_order;
select * from t_order limit 20;
在hive中加载数据我们需要先建立表,然后把文本文件中的数据load到表中,结果如下图所示。
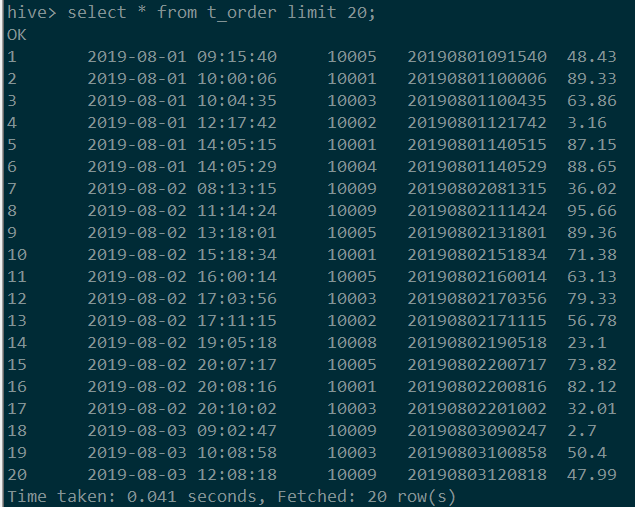
我们在MySQL和Hive中都把时间存储成字符串,这在工作中比较常见,使用起来也比较灵活和习惯,因此没有使用专门的日期类型。
开始学习
我们把日期相关的操作分为日期获取,日期转换,日期计算三类。下面开始逐一学习。
![]()
日期获取
1.获取当前日期,年月日时分秒
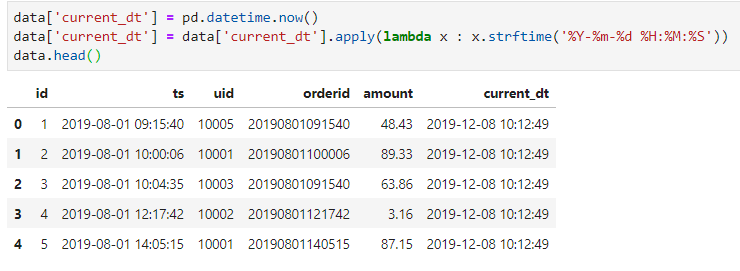
pandas中可以使用now()函数获取当前时间,但需要再进行一次格式化操作来调整显示的格式。我们在数据集上新加一列当前时间的操作如下:
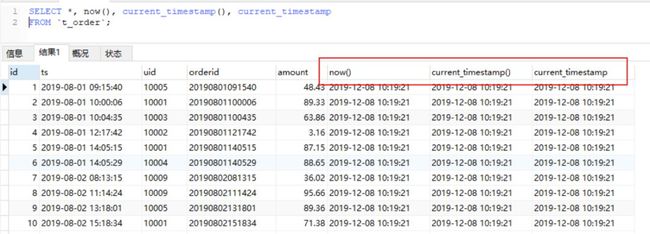
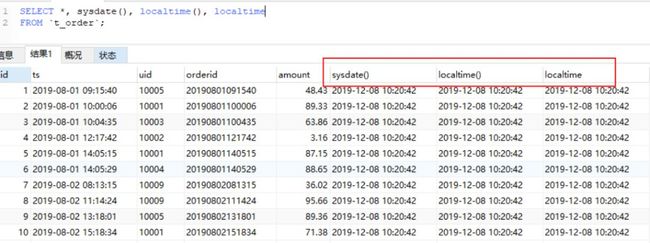
MySQL有多个函数可以获取当前时间:
now(),current_timestamp,current_timestamp(),sysdate(),localtime(),localtime,localtimestamp,localtimestamp()等。
点击图片查看大图
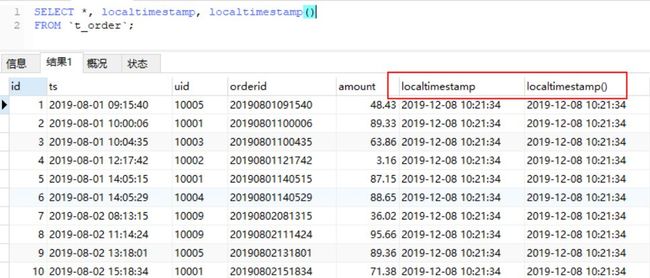
hive中获取当前时间,可以使用 current_timestamp(), current_timestamp,得到的是带有毫秒的,如果想保持和上面同样的格式,需要使用substr截取一下。如下图所示:

图中代码:
#pandas
data['current_dt'] = pd.datetime.now()
data['current_dt'] = data['current_dt'].apply(lambda x : x.strftime('%Y-%m-%d %H:%M:%S'))
data.head()
#也可以data['current_dt'] = pd.datetime.now().strftime('%Y-%m-%d %H:%M:%S')一步到位
#MySQL
SELECT *, now(),current_timestamp(),current_timestamp
FROM `t_order`;
SELECT *, sysdate(),ocaltime(),localtime
FROM `t_order`;
SELECT *, localtimestamp, localtimestamp()
FROM `t_order`;
#HiveQL
select *, substr(current_timestamp, 1, 19), substr(current_timestamp(), 1, 19)
from t_order limit 20;
2.获取当前时间,年月日
pandas中似乎没有直接获取当前日期的方法,我们沿用上一小节中思路,进行格式转换得到当前日期。当然这不代表python中的其他模块不能实现,有兴趣的朋友可以自己查阅相关文档。
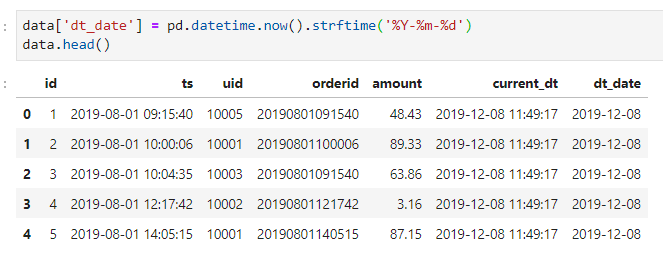
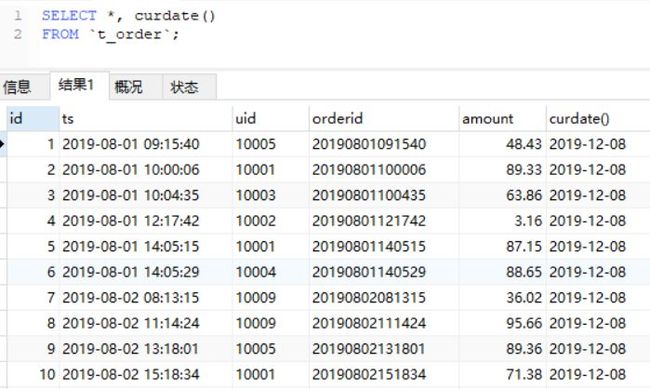
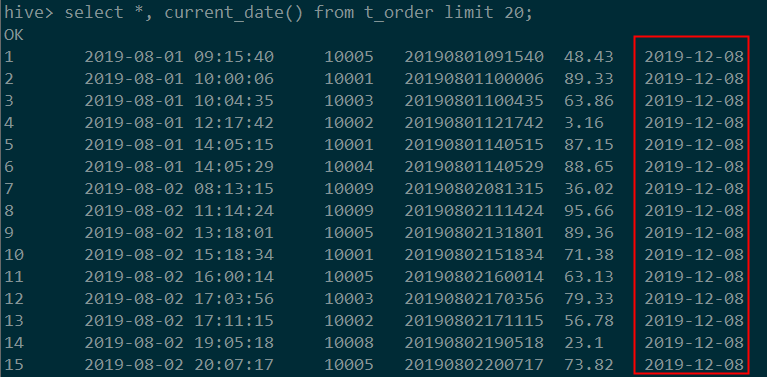
MySQL中可以直接获取当前日期,使用curdate()即可,hive中也有相对应的函数:current_date()。
图片中的代码:
#pandas
data['dt_date'] = pd.datetime.now().strftime('%Y-%m-%d')
data.head()
#MySQL
SELECT *, curdate() FROM `t_order`;
#HiveQL
select *, current_date() from t_order limit 20;
3.提取日期中的相关信息
日期中包含有年月日时分秒,我们可以用相应的函数进行分别提取。下面我们提取一下ts字段中的天,时间,年,月,日,时,分,秒信息。

在MySQL和Hive中,由于ts字段是字符串格式存储的,我们只需使用字符串截取函数即可。两者的代码是一样的,只需要注意截取的位置和长度即可,效果如下:
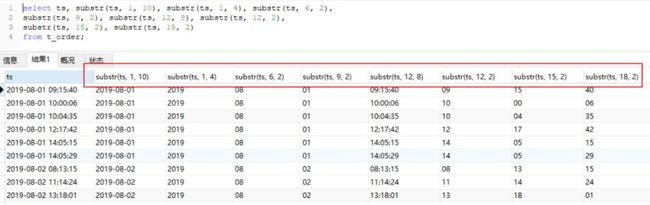
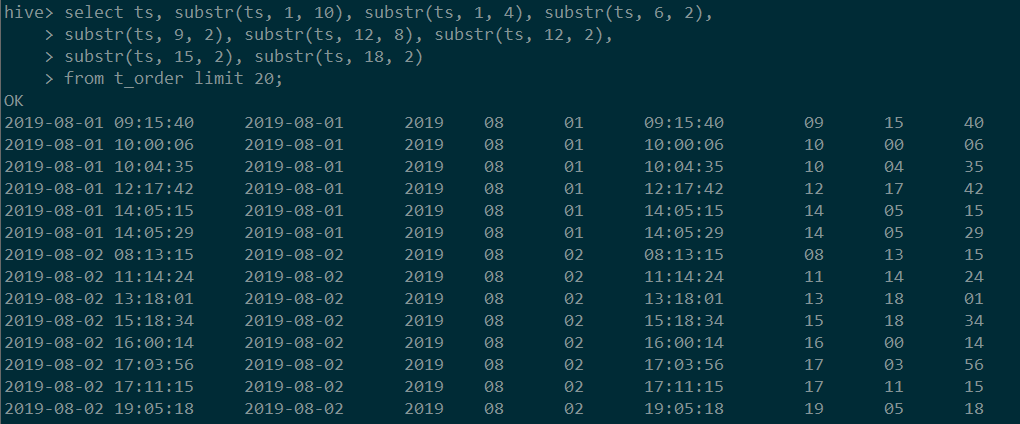
图片中代码:
#pandas
data['dt_day'] = data['ts'].dt.date#提取年月日
data['year'] = data['ts'].dt.year#提取年份
data['month'] = data['ts'].dt.month#提取月份
data['day'] = data['ts'].dt.day#提取天数
data['dt_time'] = data['ts'].dt.time#提取时间
data['hour'] = data['ts'].dt.hour#提取小时
data['minute'] = data['ts'].dt.minute#提取分钟
data['second'] = data['ts'].dt.second#提取秒
data.head()
#MySQL
select ts, substr(ts, 1, 10), substr(ts, 1, 4), substr(ts, 6, 2),
substr(ts, 9, 2), substr(ts, 12, 8), substr(ts, 12, 2),
substr(ts, 15, 2), substr(ts, 18, 2)
from t_order;
#HiveQL
select ts, substr(ts, 1, 10), substr(ts, 1, 4), substr(ts, 6, 2),
substr(ts, 9, 2), substr(ts, 12, 8), substr(ts, 12, 2),
substr(ts, 15, 2), substr(ts, 18, 2)
from t_order limit 20;
![]()
日期转换
1.可读日期转换为unix时间戳
在pandas中,我找到的方法是先将datetime64[ns]转换为字符串,再调用time模块来实现,代码如下:
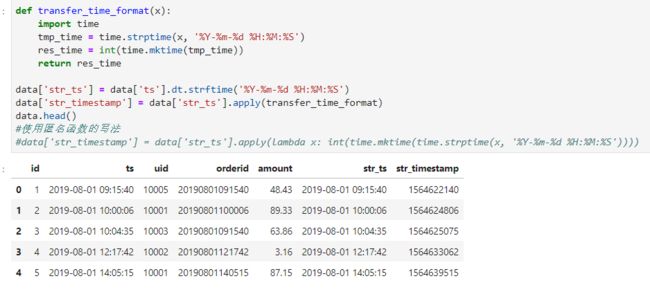
可以验证最后一列的十位数字就是ts的时间戳形式。
ps.在此之前,我尝试了另外一种借助numpy的方式,进行类型的转换,但转出来结果不正确,比期望的结果多8个小时,我写在这里,欢迎有经验的读者指正。
import numpy as np
data['ts_timestamp'] = (data.ts.astype(np.int64)/1e9).astype(np.int64)
data.head()
#得到的ts_timestamp结果
#1564650940 1564653606 1564653875等刚好比正确的结果多8个小时
MySQL和Hive中可以使用时间戳转换函数进行这项操作,其中MySQL得到的是小数形式,需要进行一下类型转换,Hive不需要。


图中代码:
#python
def transfer_time_format(x):
import time
tmp_time = time.strptime(x, '%Y-%m-%d %H:%M:%S')
res_time = int(time.mktime(tmp_time))
return res_time
data['str_ts'] = data['ts'].dt.strftime('%Y-%m-%d %H:%M:%S')
data['str_timestamp'] = data['str_ts'].apply(transfer_time_format)
data.head()
#使用匿名函数的写法
#data['str_timestamp'] = data['str_ts'].apply(lambda x: int(time.mktime(time.strptime(x, '%Y-%m-%d %H:%M:%S'))))
#MySQL
select *, cast(unix_timestamp(ts) as int)
from t_order;
#Hive
select *, unix_timestamp(ts) from t_order limit 20;
2.unix时间戳转换为可读日期
这一操作为上一小节的逆向操作。
在pandas中,我们看一下如何将str_timestamp列转换为原来的ts列。这里依然采用time模块中的方法来实现。
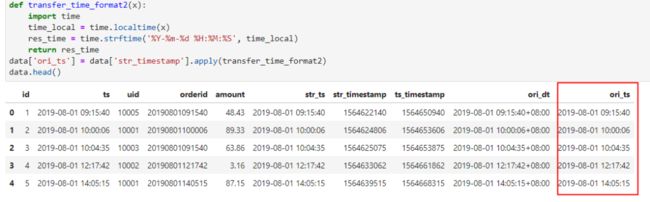
ps.你可能发现了上面代码中有一列是ori_dt,虽然看上去是正确的,但格式多少有那么点奇怪,这也是我在学习过程中看到的一个不那么正确的写法,贴出来供大家思考。
data['ori_dt'] = pd.to_datetime(data['str_timestamp'].values, unit='s', utc=True).tz_convert('Asia/Shanghai')
data.head()
#使用默认的pd.to_datetime并不能转会正确的时间,比实际时间小8个小时
#在网上看到了这种写法能把8个小时加回来,但显示的很奇怪。
回到MySQL和Hive,依然只是用一个函数就解决了。
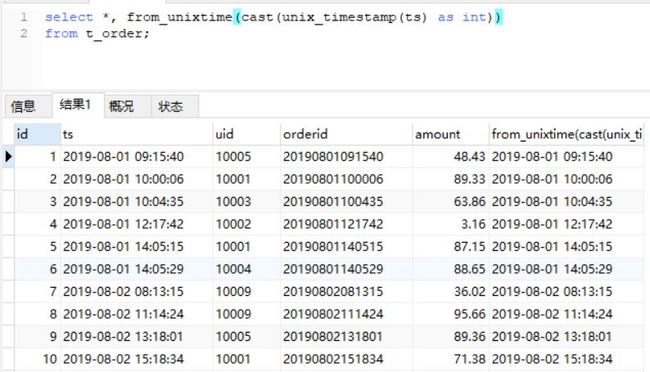
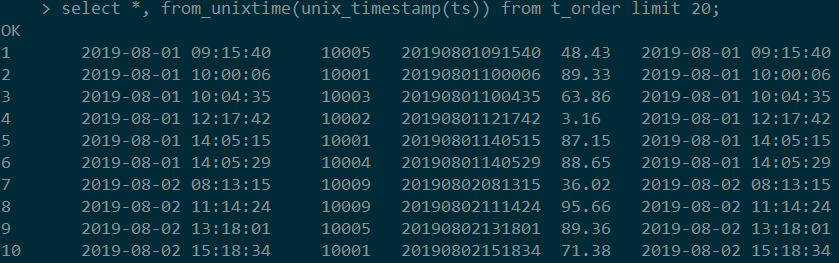
图中代码如下:
#pandas:
def transfer_time_format2(x):
import time
time_local = time.localtime(x)
res_time = time.strftime('%Y-%m-%d %H:%M:%S', time_local)
return res_time
data['ori_ts'] = data['str_timestamp'].apply(transfer_time_format2)
data.head()
#MySQL
select *, from_unixtime(cast(unix_timestamp(ts) as int))
from t_order;
#Hive
select *, from_unixtime(unix_timestamp(ts)) from t_order limit 20;
3.10位日期转8位
对于初始是ts列这样年月日时分秒的形式,我们通常需要先转换为10位年月日的格式,再把中间的横杠替换掉,就可以得到8位的日期了。
由于打算使用字符串替换,我们先要将ts转换为字符串的形式,在前面的转换中,我们生成了一列str_ts,该列的数据类型是object,相当于字符串,可以在此基础上进行这里的转换。

MySQL和Hive中也是同样的套路,截取和替换几乎是最简便的方法了。

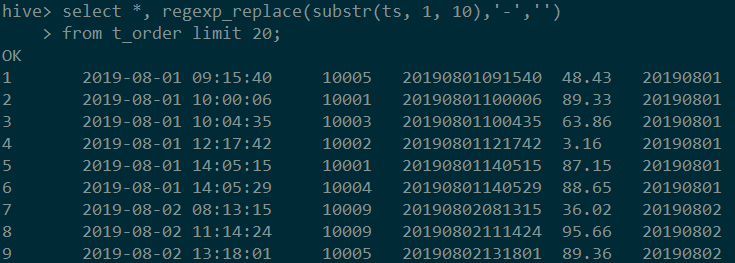
图中代码:
#pandas
data['str_ts_8'] = data['str_ts'].astype(str).str[:10].apply(lambda x: x.replace('-',''))
data.head()
#MySQL
select replace(substr(ts, 1, 10), '-', '')
from t_order;
#Hive
select *, regexp_replace(substr(ts, 1, 10),'-','')
from t_order limit 20;
当然,我们也有另外的解法:使用先将字符串转为unix时间戳的形式,再格式化为8位的日期。
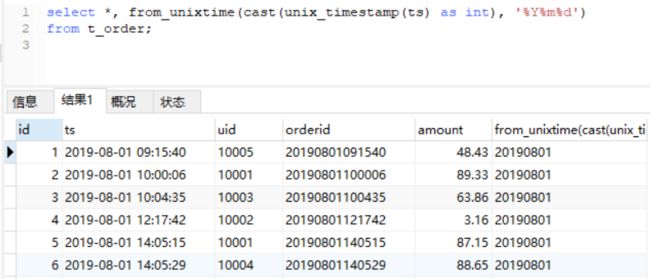
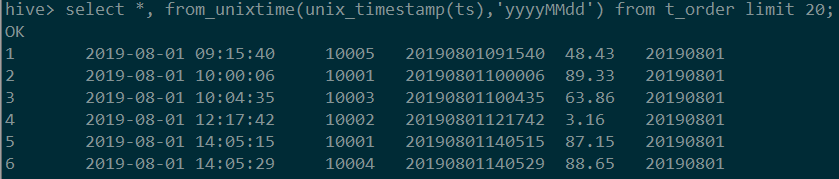
图中代码:
#MySQL
select *, from_unixtime(cast(unix_timestamp(ts) as int), '%Y%M%d')
from t_order;
#Hive
select *, from_unixtime(unix_timestamp(ts),'yyyyMMdd') from t_order limit 20;
pandas中我们也可以直接在unix时间戳的基础上进行操作,转为8位的日期。具体做法只要上面的transfer_time_format2函数即可,效果如下图所示。
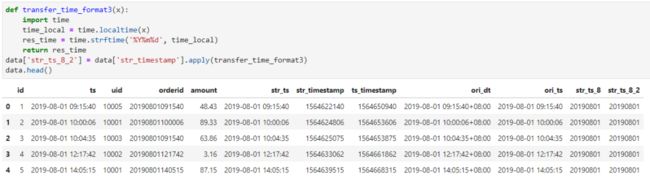
def transfer_time_format3(x):
import time
time_local = time.localtime(x)
res_time = time.strftime('%Y%m%d', time_local)#改这里的格式就好
return res_time
data['str_ts_8_2'] = data['str_timestamp'].apply(transfer_time_format3)
data.head()
4.8位日期转10位
这一操作同样为上一小节的逆向操作。
结合上一小节,实现10位转8位,我们至少有两种思路。可以进行先截取后拼接,把横线-拼接在日期之间即可。二是借助于unix时间戳进行中转。SQL中两种方法都很容易实现,在pandas我们还有另外的方式。
方法一:
pandas中的拼接也是需要转化为字符串进行。如下:

MySQL和Hive中,可以使用concat函数进行拼接:
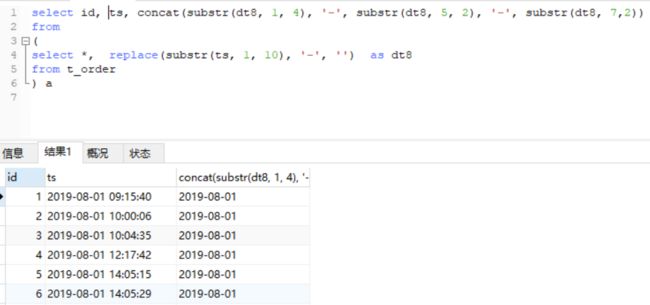

图中代码如下:
#python
data['str_ts_10'] = data['str_ts_8'].apply(lambda x : x[:4] + "-" + x[4:6] + "-" + x[6:])
data.head()
#MySQL
select id, ts, concat(substr(dt8, 1, 4), '-', substr(dt8, 5, 2), '-', substr(dt8, 7,2))
from
(
select *, replace(substr(ts, 1, 10), '-', '') as dt8
from t_order
) a
#Hive
select id, ts, concat(substr(dt8, 1, 4), '-', substr(dt8, 5, 2), '-', substr(dt8, 7,2))
from
(
select *, regexp_replace(substr(ts, 1, 10),'-','') as dt8
from t_order
) a
limit 20;
方法二,通过unix时间戳转换:
在pandas中,借助unix时间戳转换并不方便,我们可以使用datetime模块的格式化函数来实现,如下所示。
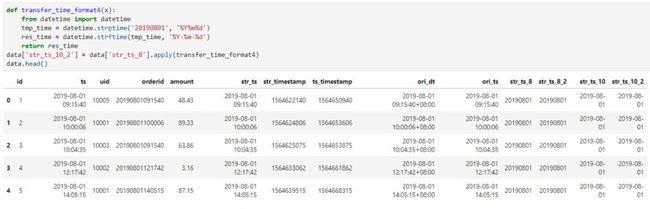
Mysql和Hive中unix_timestamp接收的参数不一样,前者必须输入为整数,后者可以为字符串。我们的目标是输入一个8位的时间字符串,输出一个10位的时间字符串。由于原始数据集中没有8位时间,我们临时构造了一个。代码如下:

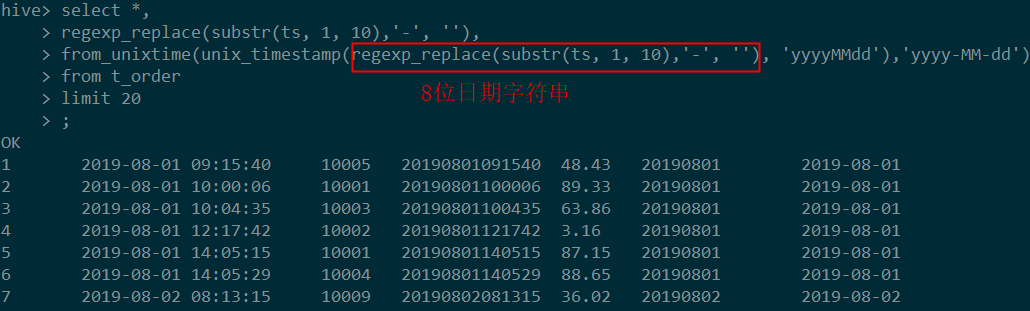
图中代码如下:
#pandas
def transfer_time_format4(x):
from datetime import datetime
tmp_time = datetime.strptime('20190801', '%Y%m%d')
res_time = datetime.strftime(tmp_time, '%Y-%m-%d')
return res_time
data['str_ts_10_2'] = data['str_ts_8'].apply(transfer_time_format4)
data.head()
#MySQL
select *,
replace(substr(ts, 1, 10),'-', ''),
from_unixtime(unix_timestamp(cast(replace(substr(ts, 1, 10),'-', '')as int)),'%Y-%m-%d')
from t_order
;
#Hive
select *,
regexp_replace(substr(ts, 1, 10),'-', ''),
from_unixtime(unix_timestamp(regexp_replace(substr(ts, 1, 10),'-', ''), 'yyyyMMdd'),'yyyy-MM-dd')
from t_order
limit 20
;
ps.关于时间Hive中的时间转换,我在之前总结Hive函数的文章的最后一部分中已经有过梳理,例子比此处更加具体,欢迎翻阅:常用Hive函数的学习和总结
![]()
日期计算
日期计算主要包括日期间隔(加减一个数变为另一个日期)和计算两个日期之间的差值。
1.日期间隔
pandas中对于日期间隔的计算需要借助datetime 模块。我们来看一下如何计算ts之后5天和之前3天。
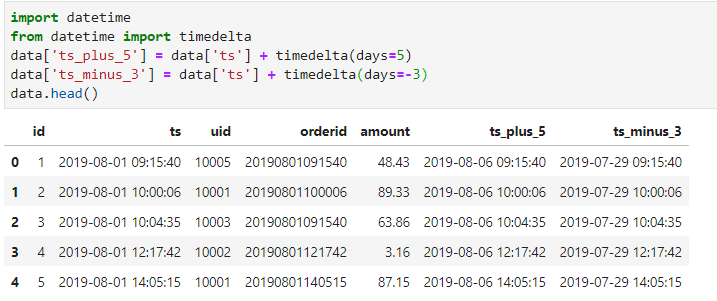
使用timedelta函数既可以实现天为单位的日期间隔,也可以按周,分钟,秒等进行计算。
在MySQL和Hive中有相应的日期间隔函数date_add,date_sub函数,但使用的格式略有差异。

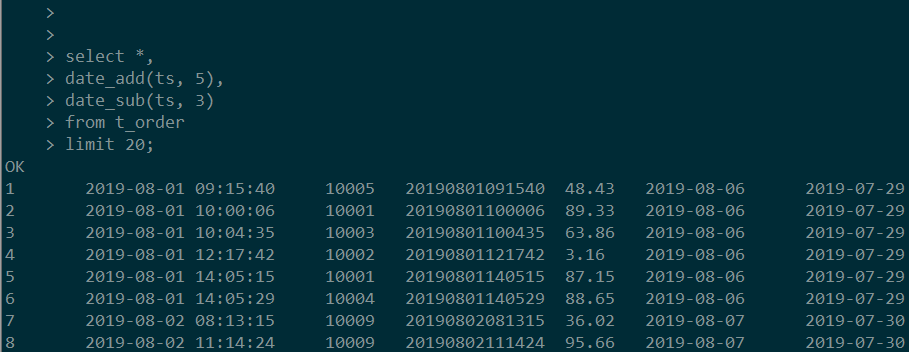
需要注意的是Hive计算的结果没有时分秒,如果需要,依然可以使用拼接的方式获得,此处略。
2.日期差
这一小节仍然是上一小节的逆操作。(怎么这么多逆操作,累不累啊......)我们来看一下如何计算两个时间的日期差。
在pandas中,如果事件类型是datetime64[ns]类型,直接作差就可以得出日期差,但是得到的数据后面还有一个"days"的单位,这其实就是上一小节提到的timedelta类型。
为了便于使用,我们使用map函数获取其days属性,得到我们想要的数值的差。如下所示:
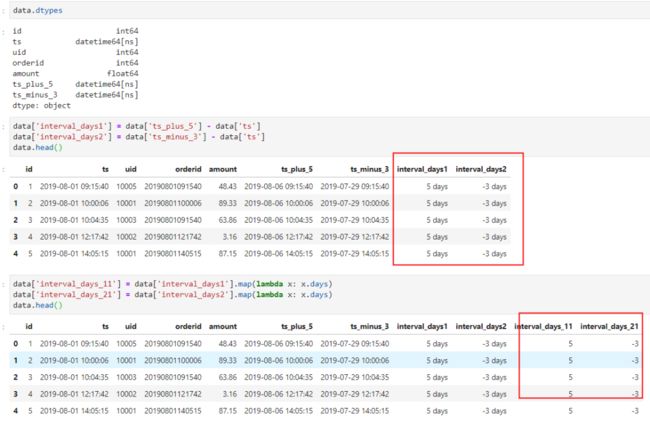
如果不是datetime格式,可以先用下面的代码进行一次转换。
#str_ts是字符串格式,转换出的dt_ts是datetime64[ns]格式
data['dt_ts'] = pd.to_datetime(data['str_ts'], format='%Y-%m-%d %H:%M:%S')
Hive和MySQL中的日期差有相应的函数datediff。但需要注意它的输入格式。
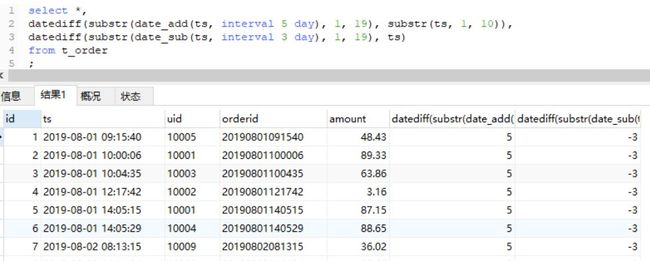

可以看到输入的形式既可以是具体到时分秒的格式,也可以是年月日格式。但是要注意Hive中输入的日期必须是10位的格式,否则得不到正确的结果,比如输入8位的,结果会是NULL,而MySQL则可以进行8位日期的计算。

◆ ◆ ◆ ◆ ◆
小结

本文涉及到的对比操作和相应的解法如上图所示。整体看起来比之前的要“乱”一些,但仔细看看并没有多少内容。
需要指出,关于日期操作,本文只是总结了一些pandas和SQL都有的部分操作,也都是比较常见的。python中和SQL本身关于日期操作还有很多其他用法,限于时间关系就省略了。
由于时间匆忙,行文不当之处还请多多包含。如果你有好的想法,欢迎一起交流学习。本文的代码和数据可以在公众号后台回复“对比三”获取,祝学习愉快!

以清净心看世界;
用欢喜心过生活。
超哥的杂货铺,你值得拥有~
添加微信hitchenghengchao进入交流群~
长按二维码关注我们
![]()
推荐阅读:
1.一场pandas与SQL的巅峰大战
2.一场pandas与SQL的巅峰大战(二)
3.常用Hive函数的学习和总结