Hadoop 2.7版本 集群环境搭建实例
1.知识准备
1.1 Hadoop 简介
Hadoop 是开源的、可扩展的、高可用的分布式计算框架。在多数场景下,它是处理大数据问题的利器。
它包括几个部分:① Hadoop common:支持hadoop的公共工具。
② HDFS:支持高吞吐量的分布式文件系统。
③ YARN:作业调度,集群资源管理的框架。
④ Hadoop MapReduce:基于YARN的,大规模数据并行处理的核心框架。
1.2 Hadoop 2.7.2 简介
与上一代hadoop相比,新一代的hadoop有了新的框架 ---- YARN,它取代了以前 JobTracker,TaskTracker。
引入了ResourceManager等概念。具体简介可参考:Hadoop YARN 简介
本次集群搭建针对的是 2.7.2 的版本。
1.3 基础概念简介
HDFS运行时相关的守护进程是:NameNode、SecondaryNameNode、DataNode。
NameNode:维护着文件系统树,以及文件系统树中所有的文件、文件夹的元信息。
SecondaryNameNode:对NameNode记录的元信息根据具体配置进行一个备份。
DataNode:根据NameNode的调度来存储、检索所存储的块(block)的信息,并定期与NameNode通信维护
相应的元信息。
YARN运行时相关的守护进程是:ResourceManager、NodeManager、WebAppProxy。
MapReduce 任务使用的话,可以启动 MapReduce Job History Server的进程,可供web界面查看。
注意,不能为了搭建集群而搭建集群,先搞清楚每个部分的作用,合理规划,才能真正搭建一个有用的集群。
此部分是一个简介,你可以通过google或访问hadoop官网了解具体的概念后,再进行集群搭建的操作。
2.环境准备
本次集群搭建所使用的linux系统版本是:CentOS release 6.5 (Final)。
采用三台机器(当然,你可以使用虚拟机),ip分别为 172.18.1.127,172.18.1.158,172.18.1.49
2.1 必备环境与准备工作
① JDK版本: oracle 1.6.0_20 以上,本次使用的是 1.7.0_79。
② Hadoop 软件包下载:Hadoop软件包下载
③ 查看每台机器的hostname。如需修改,请参考:linux hostname的配置方法
④ 三台机器相互之间需要配置 SSH 互信关系,
配置方法,请参考: linux ssh互信配置 - 服务器间免密码登陆
⑤ 修改/etc/hosts 文件,保证三台机器DNS互通,配置应该如下:

请保证三台机器的/etc/hosts 里有相互机器的映射关系(三台机器都应该有以上的配置信息)。
注意,实际生产配置的时候,建议使用DNS服务,此文不做讲解。
⑥ 请在三台机器上建立相同的目录,建立目录的用户与建立SSH互信关系时用的用户一致:

其中/opt/he/test-hadoop/hadoop-2.7.2 就是 HADOOP_HOME(以下会用到)。
2.2 集群规划
172.18.1.127:NameNode、SecondaryNameNode、ResourceManager (主节点)
172.18.1.158:DataNode、NodeManager (从节点)
172.18.1.49: DataNode、NodeManager (从节点)
在实际生产中,建议把NameNode 与 SecondaryNameNode 放到两台机器上去,也不建议把
NameNode 与 ResourceManager 放到一台机器上,本次只是做一个实例演示而已。
3.配置过程
登陆主节点机器(172.18.1.127),进入${HADOOP_HOME}/etc/hadoop 目录下,所有需要修改的配置文件
都在这儿了,本次集群搭建几乎按照最少配置原则(大部分采用其默认配置),如需深入配置、优化,请参见:
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/core-default.xml
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
http://hadoop.apache.org/docs/r2.7.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
3.1 core-site.xml
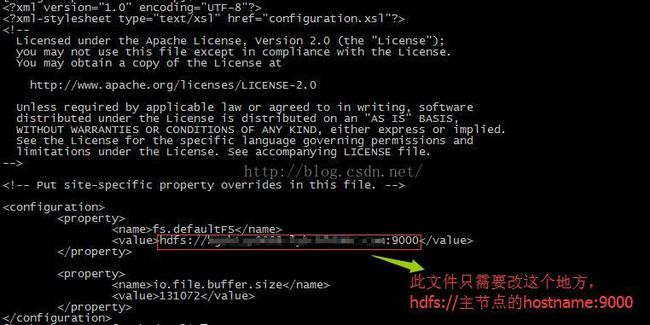
可复制版本如下:
fs.defaultFS
hdfs://你的主节点的hostname:9000
io.file.buffer.size
131072
3.2 hdfs-site.xml
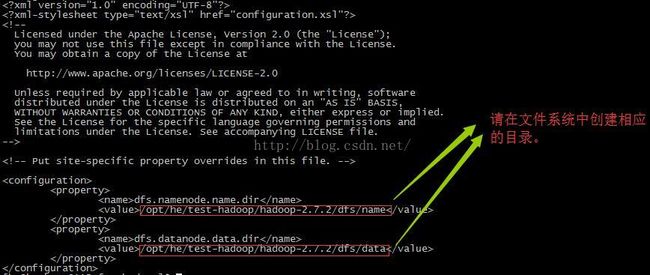
可复制的版本如下:
dfs.namenode.name.dir
/opt/he/test-hadoop/hadoop-2.7.2/dfs/name
dfs.datanode.data.dir
/opt/he/test-hadoop/hadoop-2.7.2/dfs/data
3.3 mapred-site.xml

可复制的版本如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
从节点的hostname:10020
mapreduce.jobhistory.webapp.address
从节点的hostname:19888
3.4 yarn-site.xml

可复制的版本如下:
yarn.resourcemanager.address
主节点hostname:8032
yarn.resourcemanager.scheduler.address
主节点hostname:8033
yarn.resourcemanager.resource-tracker.address
主节点hostname:8034
yarn.resourcemanager.admin.address
主节点hostname:8035
yarn.resourcemanager.webapp.address
主节点hostname:8036
yarn.nodemanager.aux-services
mapreduce_shuffle
3.5 slaves
进入slaves这个文件,输入 172.18.1.49、172.18.1.158 两台从节点的 hostname,一行输入一个。
3.6 同步机器配置
scp -r hadoop-2.7.2 he@ip:/opt/he/test-hadoop/3.7 修改环境脚本
分别获取每台机器的 JAVA_HOME,修改每台机器 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 脚本:
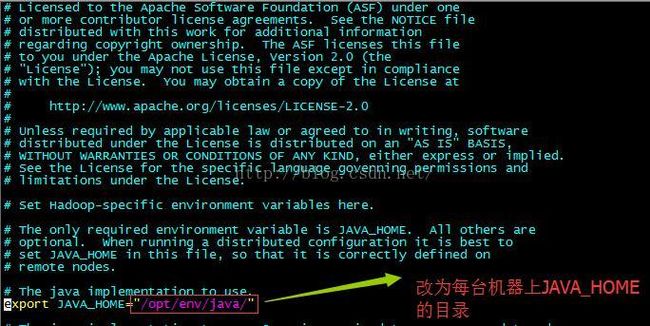
至此,所有环境配置都已经准备就绪。
4.启动集群,打开web ui
以下启动命令都在${HADOOP_HOME}目录下:
① 格式化 HDFS 文件系统:
bin/hadoop namenode -format
② 一键启动hadoop集群:
sbin/start-all.sh
对的,启动集群的基本操作就完成了。检验以下,在各台机器上,输入 jps 命令,我得到的结果如下:
主节点运行jps后显示的内容(进程号 进程名称):
27657 NameNode
28433 Jps
27882 SecondaryNameNode
28090 ResourceManager
从节点运行jps后显示的内容进程号 进程名称):
44866 Jps
43332 NodeManager
43110 DataNode
打开web ui:
http://172.18.1.127:50070/
http://172.18.1.127:8036/
如果还想启动 job history,使用命令(我是在从节点上运行的这个命令):
sbin/mr-jobhistory-daemon.sh --config /opt/he/test-hadoop/hadoop-2.7.2/etc/hadoop/ start
historyserver
打开web ui:
http://172.18.1.158:19888/
能看到web ui,能看到进程,基本就证明集群启动成功。
5.运行一个MapReduce任务
上一节说了,基本可以证明集群启动成功了,但是不运行一个demo,心里会没底。2.7.2这个版本自带了demo
包,所以我们可以运行一下试试,如果能够成功,就证明真的是没有问题的。
① 在HDFS上创建一个文件夹,如下:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/he (其中,he是我的用户名)
② 把本地系统的文件拷到 HDFS 上:
bin/hdfs dfs -put etc/hadoop input
③ 运行demo:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input
output 'dfs[a-z.]+'
④ 查看运行结果:
bin/hdfs dfs -cat output/*
如果你一路以来都配置运行正确,结果如下:
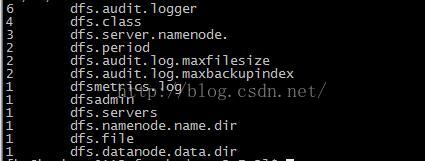
至此,集群搭建完毕,过程中有任何问题,欢迎与我沟通,我尽力与各位交流讨论。
本文内容参考如下:
【1】http://hadoop.apache.org/
注意:
如您发现本文档中有明显错误的地方,
或者您发现本文档中引用了他人的资料而未进行说明时,请联系我进行更正。
转载或使用本文档时,请作醒目说明。
必要时请联系作者,否则将追究相应的法律责任。
note:
If you find this document with any error ,
Or if you find any illegal citations , please contact me correct.
Reprint or use of this document,Please explain for striking.
Please contact the author if necessary, or they will pursue the corresponding legal responsibility.