机器学习实战9-运行Tensorflow(california_housing数据集)
目录
一、创造一个图谱
1.1、管理图谱
二、TensorFlow线性回归
2.1、这里引用California housing的数据
2.2、标准方程法
2.3、实现梯度下降
2.4、autodiff
2.5、使用优化器
2.6、小批量梯度下降和placeholder占位符
三、保存模型
四、TensorBoard可视化
五、命名作用域:
模块化
共享变量
TensorFlow 是一款用于数值计算的强大的开源软件库,特别适用于大规模机器学习的微调。 它的基本原理很简单:首先在 Python 中定义要执行的计算图,然后 TensorFlow 使用该图并使用优化的 C++ 代码高效运行该图。Tensorflow 可以将图分解为多个块并在多个 CPU 或 GPU 上并行运行。
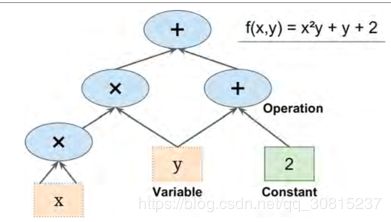

一、创造一个图谱
import tensorflow as tf
x = tf.Variable(3, name="x")
y = tf.Variable(4, name="y")
f = x*x*y + y + 2 这个代码实际上并不执行任何计算。 它只是创建一个计算图谱。 变量都没有初始化,要求值计算,需要打开一个TensorFlow会话并使用它初始化变量并求出f。TensorFlow 会话负责处理在诸如 CPU 和 GPU 之类的设备上的操作并运行它们,并且它保留所有变量值。
1、以下代码创建一个会话,初始化变量,并求出f,然后关闭会话(释放资源):
sess = tf.Session() #定义session
sess.run(x.initializer) #为已经定义的节点初始化
sess.run(y.initializer)
result = sess.run(f) #运行session
sess.close() #释放空间2、每次重复sess.run() 有点麻烦,有一个更好的方法:
with tf.Session() as sess:
x.initializer.run()
y.initializer.run()
result = f.eval()
print(result)在with块中,会话被设置为默认会话。 调用x.initializer.run()等效于调用tf.get_default_session().run(x.initial),f.eval()等效于调用tf.get_default_session().run(f)。 这使得代码更容易阅读。 此外,会话在块的末尾自动关闭。
变量初始化:
使用global_variables_initializer() 函数,而不是手动初始化每个变量。 请注意,它实际上没有立即执行初始化,而是在图谱中创建一个当程序运行时所有变量都会初始化的节点:
init = tf.global_variables_initializer()
with tf.Session() as sess:
init.run()
result = f.eval()
print(result) 在 Jupyter 内部或在 Python shell 中,与常规会话的唯一区别是,当创建InteractiveSession时,它将自动将其自身设置为默认会话,因此您不需要使用模块(但是您需要在完成后手动关闭会话):
init = tf.global_variables_initializer()
sess = tf.InteractiveSession()
init.run()
result = f.eval()
print(result)
sess.close() TensorFlow 程序通常分为两部分:第一部分构建计算图谱(这称为构造阶段),第二部分运行它(这是执行阶段)。 建设阶段通常构建一个表示 ML 模型的计算图谱,然后对其进行训练,计算。 执行阶段通常运行循环,重复地求出训练步骤(例如,每个小批次),逐渐改进模型参数。
1.1、管理图谱
TensorFlow是一个图的操作,有自动缺省的默认图和你自己定义的图,创建的任何节点都会自动添加到默认图形中,但也可以通过创建一个新的图形并暂时将其设置为一个块中的默认图形,如下所示:
>>> graph = tf.Graph()
>>> with graph.as_default():
... x2 = tf.Variable(2)
...
>>> x2.graph is graph
True
>>> x2.graph is tf.get_default_graph()
False 一个更方便的解决方案是通过运行tf.reset_default_graph()来重置默认图。
节点的生命周期
第二种方法可以找出公共部分,避免x被计算2次。运行结束后所有节点的值都被清空,如果没有单独保存,还需重新run一遍。
w = tf.constant(3)
x = w + 2
y = x + 5
z = x * 3
with tf.Session() as sess:
print(y.eval()) # 10
print(z.eval()) # 15
with tf.Session() as sess:
y_val, z_val = sess.run([y, z])
print(y_val) # 10
print(z_val) # 15使用sess.run()可以在同一步获取多个tensor中的值,
二、TensorFlow线性回归
2.1、这里引用California housing的数据
import numpy as np
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
m, n = housing.data.shape
#np.c_按colunm来组合array
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
XT = tf.transpose(X)
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)
with tf.Session() as sess:
theta_value = theta.eval()
print(theta_value) 在这里housing = fetch_california_housing() 执行下载任务,下载数据集,该函数官方文档:
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html
使用上述代码加载sklearn的California_housing数据集。
housing=fetch_california_housing(data_home="datasets/mldata", download_if_missing=True)
- data_home是我们指定的下载路径;
- download_if_missing=True表示如果文件存在就不再下载,如果没有cal_housing.tgz文件,就执行下载
问题:程序一直在运行,文件成功下载到目标文件夹,但是无法打印变量housing的相关信息。
我的解决办法是从网站 https://ndownloader.figshare.com/files/5976036下载cal_housing.tgz文件,放到目录下,这时执行fetch_california_housing函数时,由于函数检测到cal_housing.tgz文件已经存在,就不会再重新下载,之后就可以正常打印变量,亲测有效。
我觉得之前无法打印变量housing的相关信息,主要是下载cal_housing.tgz文件时出了错。
另一种方法(这种方法读到的数据和上面那种方法读到的数据有偏差,我也不知道为什么??):
从网站 https://ndownloader.figshare.com/files/5976036下载cal_housing.tgz文件,解压后,有两个文件:
house = pd.read_csv('f:/data/cal_housing.data', name='None')
house_data = house.iloc[:, :-1]
house_target = house.iloc[:, -1]如果不加上“name='None'”,数据的第一行会被当作列名。
使用read_csv读取数据。from:https://blog.csdn.net/qq_39088927/article/details/83312850
2.2、标准方程法
TensorFlow 操作(也简称为 ops)可以采用任意数量的输入并产生任意数量的输出。 例如,加法运算和乘法运算都需要两个输入并产生一个输出。 常量和变量不输入(它们被称为源操作)。 输入和输出是称为张量的多维数组(因此称为“tensor flow”)。 就像 NumPy 数组一样,张量具有类型和形状。 实际上,在 Python API 中,张量简单地由 NumPy ndarray表示。
张量 可以对任何形状的数组执行计算。例如,以下代码操作二维数组来对加利福尼亚房屋数据集进行线性回归(在第 2 章中介绍)。它从获取数据集开始;之后它会向所有训练实例添加一个额外的偏置输入特征(x0 = 1);之后它创建两个 TensorFlow 常量节点X和y来保存该数据和目标,并且它使用 TensorFlow 提供的一些矩阵运算来定义theta。它们不会立即执行任何计算;相反,它们会在图形中创建,在运行图形时执行它们的节点。θ对应于方程 ![]()
import numpy as np
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
#获得数据维度,矩阵的行列长度
m, n = housing.data.shape
#np.c_是列连接的含义,加了一个全为1的维度
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
XT = tf.transpose(X)
#使用normal equation的方法求解theta,之前线性模型中有提及
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)
#求出权重
with tf.Session() as sess:
theta_value = theta.eval()2.3、实现梯度下降
from sklearn.preprocessing import StandardScaler
## StandardScaler默认就做了方差归一化,和均值归一化,这两个归一化的目的都是为了更快的进行梯度下降
scaler=StandardScaler()
scaled_housing_data=scaler.fit_transform(housing.data)
scaled_housing_data_plus_bias=np.c_[np.ones((m,1)),scaled_housing_data]
tf.reset_default_graph()
n_epochs=1000
learning_rate=0.01
X=tf.constant(scaled_housing_data_plus_bias,dtype=tf.float32,name='X')
y=tf.constant(housing.target.reshape(-1,1),dtype=tf.float32,name='y')
## random_uniform函数创建图里一个节点包含随机数值,给定它的形状和取值范围
theta=tf.Variable(tf.random_uniform([n+1,1],-1,1),name='theta')
y_pred=tf.matmul(X,theta,name="predictions")
error=y_pred-y
mse=tf.reduce_mean(tf.square(error),name="mse")
# 梯度的公式:(y_pred - y) * xj
gradients=2/m*tf.matmul(tf.transpose(X),error)
training_op=tf.assign(theta,theta-learning_rate*gradients)
init=tf.global_variables_initializer()
with tf.Session() as sess:
init.run() #等价 sess.run(init)
for epoch in range(n_epochs):
if epoch%100==0:
print("Epoch",epoch,"MSE=",mse.eval())
training_op.eval() #等价 sess.run(training_op)
best_theta=theta.eval()
best_theta上述代码使用批量梯度下降,而不是普通方程。当使用梯度下降时,请记住,首先要对输入特征向量进行归一化,否则训练可能要慢得多。
函数声明:
1、tf.random_uniform((6, 6), minval=low,maxval=high,dtype=tf.float32)))返回6*6的矩阵,产生于low和high之间,产生的值是均匀分布的。 同理tf.random_normal生成 正态分布
Tensorflow中也通过设置randomseed来产生不同的随机序列。TF中有两种级别的random seed,一个是operation-level,一个是graph-level,都会影响随机数生成:
op-level: 在调用上述表格中的算子时,可以显式指定seed参数,若seed参数相同,则在同一张graph里,每次运行生结果相同;若不指定seed参数,则每次使用随机的seed,运行结果不同。
graph-level: 调用tf.set_random_seed来设置graph-level seed。如果设置了graph-level seed,即使不显式设置算子的seed参数,也可以在同一张graph里,每次生成相同的结果。
from:https://blog.csdn.net/cmajalis/article/details/80571463
2、tf.assign(A, new_number): 这个函数的功能主要是把A的值变为new_number;
tf.assign_add(ref,value,use_locking=None,name=None) 更新ref的值,通过增加value,即:ref = ref + value;
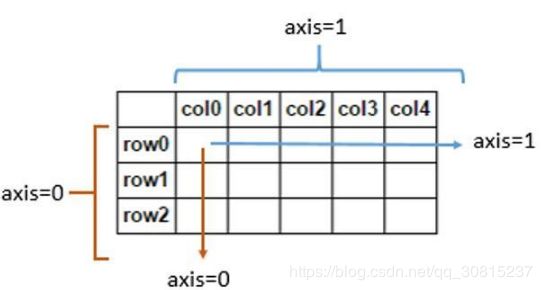
3、tf.reduce_mean((input_tensor,axis=None)函数的作用是求平均值。第一个参数是一个集合,可以是列表、二维数组和多维数组。第二个参数指定在哪个维度上面求平均值。默认对所有的元素求平均。
当指定第二个参数的时候,指定axis=0,表示沿着‘跨行’的方向求平均。而axis=1代表跨列(across),
此外还有tf.reduce_sum(),tf.reduce_max()求和,求最大值
2.4、autodiff
TensorFlow 的自动计算梯度功能可以计算这个公式:它可以自动高效地为您计算梯度。 只需用以下面这行代码gradients = tf.gradients(mse, [theta])[0] 替换上一节中代码的 gradients = ...行。
gradients()函数使用一个op(操作符,MSE)和一个变量列表(theta),它创建一个操作符列表(每个变量一个)来计算每一个变量的梯度。 因此,梯度节点将计算 MSE 相对于theta的梯度向量。 TensorFlow 使用反向模式,这是完美的(高效和准确),当有很多输入和少量的输出,如通常在神经网络的情况。 它只需要通过 ![]() 次图遍历即可计算所有输出的偏导数。
次图遍历即可计算所有输出的偏导数。
2.5、使用优化器
TensorFlow 还提供了一些可以直接使用的优化器,包括梯度下降优化器。可以使用以下代码简单地替换以前的gradients = ...和training_op = ...行,并且一切都将正常工作:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse) 如果要使用其他类型的优化器,则只需要更改一行。 例如通过定义优化器来使用动量优化器:optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)
2.6、小批量梯度下降和placeholder占位符
要实现小批量梯度下降(Mini-batch Gradient Descent)。我们需要一种在每次迭代时用下一个小批量替换X和Y的方法。 最简单的方法是使用占位符(placeholder)节点。 它们实际上并不执行任何计算,只是输出我们在运行时输出的数据。 它们通常用于在训练期间将训练数据传递给 TensorFlow。 如果在运行时没有为占位符指定值,则会收到异常。
要创建占位符节点,必须调用placeholder()函数并指定输出张量的数据类型。 还可以指定其形状,如果指定维度为None,则表示“任何大小”。例如,以下代码创建一个占位符节点A,还有一个节点B = A + 5。当我们求出B时,我们将一个feed_dict传递给eval()方法并指定A的值。注意,A必须具有 2 级(即它必须是二维的),并且必须有三列(否则引发异常),但它可以有任意数量的行:
>>> A = tf.placeholder(tf.float32, shape=(None, 3))
>>> B = A + 5
>>> with tf.Session() as sess:
... B_val_1 = B.eval(feed_dict={A: [[1, 2, 3]]})
... B_val_2 = B.eval(feed_dict={A: [[4, 5, 6], [7, 8, 9]]})
...
>>> print(B_val_1)
[[ 6. 7. 8.]]
>>> print(B_val_2)
[[ 9. 10. 11.]
[ 12. 13. 14.]]小批量梯度:
n_epochs = 10
learning_rate = 0.01
#批次的大小
batch_size=100
n_batches=int(np.ceil(m/batch_size))
#定义占位符
X=tf.placeholder(tf.float32,shape=(None,n+1),name="X")
y=tf.placeholder(tf.float32,shape=(None,1),name="y")
theta=tf.Variable(tf.random_uniform((n+1,1),-1,1,seed=42),name="theta")
y_pred=tf.matmul(X,theta,name="predictions")
error=y_pred-y
mse=tf.reduce_mean(tf.square(error),name="MSE")
optimizer=tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
def fetch_batch(epoch,batch_index,batch_size):
np.random.seed(epoch*n_batches+batch_index)
indices=np.random.randint(m,size=batch_size)#从0到m中,随机取出100个索引
X_batch=scaled_housing_data_plus_bias[indices]
y_batch=housing.target.reshape(-1,1)[indices]
return X_batch,y_batch
init = tf.global_variables_initializer()
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch,y_batch=fetch_batch(epoch,batch_index,batch_size)
sess.run(training_op,feed_dict={X:X_batch,y:y_batch})
best_theta=theta.eval()三、保存模型
TensorFlow 可以轻松保存和恢复模型。 只需在构造阶段结束(创建所有变量节点之后)创建一个保存节点; 那么在执行阶段,只要你想保存模型,只要调用它的save()方法:
恢复模型同样容易:在构建阶段结束时创建一个保存器,就像之前一样,但是在执行阶段的开始,而不是使用init节点初始化变量,你可以调用restore()方法 的保存器对象。

四、TensorBoard可视化
1、调整程序,以便将图形定义和一些训练统计信息(例如,training_error(MSE))写入 TensorBoard 将读取的日志目录。 您每次运行程序时都需要使用不同的日志目录,否则 TensorBoard 将会合并来自不同运行的统计信息,这将会混乱可视化。 最简单的解决方案是在日志目录名称中包含时间戳。
2、在构建阶段结束时添加以下代码:
mse_summary = tf.summary.scalar('MSE', mse) 创建一个节点,求出 MSE 值并将其写入二进制日志字符串(称为摘要)中
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
创建一个FileWriter,用它将摘要写入日志目录中的日志文件中。 第一个参数指示日志目录的路径(在本例中为tf_logs/run-20160906091959/,相对于当前目录)。 第二个(可选)参数是想要可视化的图形。
3、最后,要在程序结束时关闭FileWriter:
file_writer.close()完整代码请参见文末链接。
下面介绍接下来如何可视化我们生成的文件:
1、运行完上面的代码,我们得到下面一个文件:

2、直接输入“cmd",如下图所示,
3、敲“回车”进入下图命令行:
4、输入“tensorboard --logdir=./ ”(等号后面绿色的 "./" 表示当前文件路径),敲回车,如下图所示:

注意:千万不要ctrl+c复制网址再到谷歌浏览器打开,因为你一按”ctrl+c“,这个Tensor Board就被退出了,你打开页面,也会得到下面:
一定要手敲网址,为方便以后打开,你可以把这个网址收藏。结果如下:
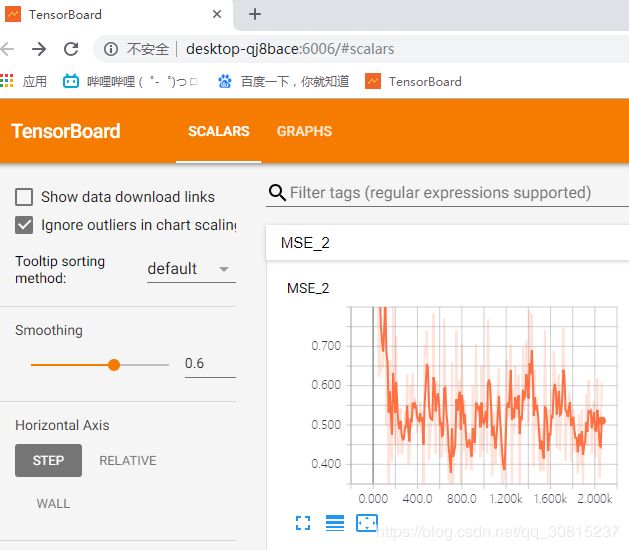

tensorboard 作为一款可视化神器,可以说是学习tensorflow时模型训练以及参数可视化的法宝。在训练过程中,主要用到了tf.summary()的各类方法,能够保存训练过程以及参数分布图并在tensorboard显示。
更多summary:https://www.cnblogs.com/lyc-seu/p/8647792.html
1、tf.summary.scalar用来显示标量信息,其格式为:
tf.summary.scalar(tags, values, collections=None, name=None)例如:tf.summary.scalar('mean', mean), 一般在画loss,accuary时会用到这个函数
2、tf.summary.FileWriter 指定一个文件用来保存图。
格式:tf.summary.FileWritter(path,sess.graph),可调用其add_summary方法将训练过程数据保存在filewriter指定的文件中
五、命名作用域:
当处理更复杂的模型(如神经网络)时,该图可以很容易地与数千个节点混淆。 为了避免这种情况,您可以创建名称作用域来对相关节点进行分组。 例如,我们修改以前的代码来定义名为loss的名称作用域内的错误和mse操作:
with tf.name_scope("loss") as scope:
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
模块化
共享变量
TensorFlow 提供比以前的解决方案稍微更清洁和更模块化的代码。首先要明白一点,这个解决方案很刁钻难懂,但是由于它在 TensorFlow 中使用了很多,所以值得我们去深入细节。 这个想法是使用get_variable()函数来创建共享变量,如果它还不存在,或者如果已经存在,则复用它。 所需的行为(创建或复用)由当前variable_scope()的属性控制。
官方文档:https://github.com/apachecn/hands-on-ml-zh/blob/master/docs/9.%E5%90%AF%E5%8A%A8%E5%B9%B6%E8%BF%90%E8%A1%8C_TensorFlow.md