吴恩达Deep Learning编程作业 Course4- 卷积神经网络-第一周作业:卷积网络应用实例开发
吴恩达Deep Learning编程作业 Course4- 卷积神经网络-第一周作业:卷积网络应用实例开发
在这一个部分中,我们需要实现:
- 使用帮助函数(吴老师提供的函数,放在文章最后)和TensorFlow实现一个功能齐全的ConvNet模型。
完成这项任务后,我们就有能力:
- 针对一个分类问题,在TensorFlow中建立并训练一个卷积神经网络。
1.0 TensorFlow模型
需要使用的包:
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
import tensorflow as tf
from tensorflow.python.framework import ops
from .utils.cnn_utils import *
np.random.seed(1)
我们将使用数据集"SIGNS":
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
此数据及我们在使用TensorFlow构建神经网络的时候使用过:
数据库中主要包括6个类别,数字从0~6。

查看数据集中的一个实例:

接下来我们查看一下数据的属性信息:
X_train = X_train_orig / 255
X_test = X_test_orig / 255
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print("number of training examples = " + str(X_train.shape[0]))
print("number of test examples = " + str(X_test.shape[0]))
print("X_train shape: " + str(X_train.shape))
print("Y_train shape: " + str(Y_train.shape))
print("X_test shape: " + str(X_test.shape))
print("Y_test shape: " + str(Y_test.shape))
conv_layers = {}
运行结果:

1.1 创建占位符
TensorFlow要求我们为输入数据创建占位符,这些数据将在运行会话时被输入到模型中。
练习:实现下面的函数,为输入图像X和输出y创建占位符。目前不应该定义训练示例的数量。为此,我们可以使用“None”作为批处理大小,它将提供后面选择的灵活性。因此,X的维度为[None, n_H0, n_W0, n_C0], Y的维度为[None, n_y]。
def create_placeholders(n_H0, n_W0, n_C0, n_y):
"""
为tensorflow会话创建占位符
:param n_H0: 输入图像的高度
:param n_W0: 输入图像的宽度
:param n_C0: 输入图像的通道数
:param n_y: 分类数
:return:
X:输入数据的占位符[None, n_H0, n_W0, n_C0] ,数据类型为float
Y:输出标签的占位符,[None, n_y] ,数据类型为float
"""
X = tf.placeholder(tf.float32, [None, n_H0, n_W0, n_C0])
Y = tf.placeholder(tf.float32, [None, n_y])
return X, Y
调用:
X, Y = create_placeholders(64, 64, 3, 6)
print("X = " + str(X))
print("Y = " + str(Y))
运行结果:

1.2 初始化参数
我们将使用tf.contrib.layers初始化权值 W 1 W1 W1和 W 2 W2 W2,xavier_initializer(seed = 0)。我们不需要担心偏差变量,因为我们很快就会学习到TensorFlow函数会处理偏差。还要注意,我们只初始化conv2d函数的权重/过滤器。TensorFlow自动初始化完全连接部分的层。
练习:实现initialize_parameters ()。每组过滤器的尺寸如下所示。在TensorFlow中使用初始化参数 W W W为[1,2,3,4],我们将使用:
W = tf.get_variable("W", [1,2,3,4], initializer = ...)
代码:
def initialize_parameters():
"""
使用tensorflow初始化权重参数建立神经网络“
W1:[4, 4, 3, 8]
W2:[2, 2, 8, 16]
:return:返回参数字典 W1, W2
"""
tf.set_random_seed(1)
W1 = tf.get_variable("W1", [4, 4, 3, 8], initializer=tf.contrib.layers.xavier_initializer(seed=0))
W2 = tf.get_variable("W2", [2, 2, 8, 16], initializer=tf.contrib.layers.xavier_initializer(seed=0))
parameters = {"W1":W1,
"W2":W2
}
return parameters
调用:
tf.reset_default_graph()
with tf.Session() as sess:
parameters = initialize_parameters()
init = tf.global_variables_initializer()
sess.run(init)
print("W1 = " + str(parameters["W1"].eval()[1,1,1]))
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
运行结果:

1.3 前向传播
在TensorFlow中,有一些内置函数可以为我们执行卷积步骤。
tf.nn.conv2d(X,W1, strides = [1,s,s,1], padding = 'SAME'):给定一个输入 X X X和一组过滤器 W 1 W1 W1,这个函数对 W 1 W1 W1的过滤器在X上进行卷积。第三个输入([1,f,f,1])表示输入(m, n_H_prev, n_W_prev, n_C_prev)的每个维度的步长。tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = 'SAME'):给定一个输入A,这个函数使用大小(f, f)的窗口和大小(s, s)的步长在每个窗口上执行最大池化方法。tf.nn.relu(Z1):计算Z1的Relu激活值。tf.contrib.layers.flatten(P):给定一个输入P,此函数将会把每个样本转化成一维的向量,然后返回一个tensor变量,其维度为(batch_size,k)。tf.contrib.layers.fully_connected(F, num_outputs):给定一个扁平的输入F,它返回使用全连接层计算的输出。
练习:建立forward_propagation函数建立下面的模型: C O N V 2 D − > R E L U − > M A X P O O L − > C O N V 2 D − > R E L U − > M A X P O O L − > F L A T T E N − > F U L L Y C O N N E C T E D CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED CONV2D−>RELU−>MAXPOOL−>CONV2D−>RELU−>MAXPOOL−>FLATTEN−>FULLYCONNECTED.
我们将按照下面的步骤实现:
- Conv2D: 步长为 1, padding选为"SAME"。
- ReLU
- Max pool: 使用88的过滤器大小和88的步长,padding是"SAME"。
- Conv2D: 步长为 1, padding选为"SAME"。
- ReLU
- Max pool: 使用44的过滤器大小和44的步长,padding是"SAME"。
- 将上一层的输出一维化。
- 全连接层(FC):使用没有非线性激活函数的全连接层。这里不要调用softmax, 这将导致输出层中有6个神经元,后面再传递到softmax。 在TensorFlow中,softmax和cost函数被集中到一个函数中,在计算成本时您将调用不同的函数。
代码:
def forward_propagation(X, parameters):
"""
为下面的模型实现前向传播:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
:param X:输入的数据,维数为(input size, number of examples)
:param parameters:W1,W2
:return:Z3,最后的线性单元的输出
"""
W1 = parameters['W1']
W2 = parameters['W2']
# CONV2D: stride of 1, padding 'SAME'
Z1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1, 1], padding='SAME')
# RELU
A1 = tf.nn.relu(Z1)
# MAXPOOL: window 8x8, stride 8, padding 'SAME'
P1 = tf.nn.max_pool(A1, ksize=[1, 8, 8, 1], strides=[1, 8, 8, 1], padding='SAME')
# CONV2D: filters W2, stride 1, padding 'SAME'
Z2 = tf.nn.conv2d(P1, W2, strides=[1, 1, 1, 1], padding='SAME')
# RELU
A2 = tf.nn.relu(Z2)
# MAXPOOL: window 4x4, stride 4, padding 'SAME'
P2 = tf.nn.max_pool(A2, ksize=[1, 4, 4, 1], strides=[1, 4, 4, 1], padding='SAME')
# FLATTEN
P = tf.contrib.layers.flatten(P2)
# FULLY-CONNECTED 没有线性激活函数 (not not call softmax).
# 输出层有6个神经元. 注意: 其中一个参数应该是"activation_fn=None"
Z3 = tf.contrib.layers.fully_connected(P, 6, activation_fn=None)
return Z3
调用:
tf.reset_default_graph()
np.random.seed(1)
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(Z3, {X: np.random.randn(2, 64, 64, 3), Y: np.random.randn(2, 6)})
print("Z3 = " + str(a))
运行结果:
![]()
1.4 计算代价
实现下面的计算成本函数。我们可能会用到下面两个函数:
tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y):计算softmax熵损失。这个函数即计算softmax激活函数,也计算产生的损失tf.reduce_mean:计算所有元素平均值,使用它来计算所有样本的损失来得到总成本。
练习:使用上面的函数实现计算代价的函数:
代码:
def compute_cost(Z3, Y):
"""
计算代价
:param Z3:前向传播最后结果,维数(6, 样本数)
:param Y:真实标签,和Z3维数相同
:return:cost
"""
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y))
return cost
调用:
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(cost, {X: np.random.randn(4, 64, 64, 3), Y: np.random.randn(4, 6)})
print("cost = " + str(a))
运行结果:
![]()
1.5 实现模型
我们将合并上面实现的函数,实现整个模型,使用的数据集依然是SIGNS。
练习:实现下面的函数
步骤如下:
- 创建占位符
- 初始化参数
- 前向传播
- 计算代价
- 创建优化器
最后,您将创建一个会话并为num_epochs运行一个for循环,获取迷你批处理,然后对每个迷你批处理优化函数。
代码:
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.0025,num_epochs=100, minibatch_size=64, print_cost=True):
"""
使用TensorFlow实现三层的卷积层
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
:param X_train:训练集,维数为(None, 64, 64, 3)
:param Y_train:训练集,维数为(None, n_y = 6)
:param X_test:测试集,维数为(None, 64, 64, 3)
:param Y_test:测试集,维数为(None, n_y = 6)
:param learning_rate:学习率
:param num_epochs:迭代次数
:param minibatch_size:mini_batch的大小
:param print_cost:是否每100次打印代价
:return:
train_accuracy:训练集准确度
test_accuracy:测试集准确度
parameters:
"""
ops.reset_default_graph()
tf.set_random_seed(1)
seed = 3
m, n_H0, n_W0, n_C0 = X_train.shape
n_y = Y_train.shape[1]
costs = []
#1.创建占位符
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
#2.初始化参数
parameters = initialize_parameters()
#3.前向传播
Z3 = forward_propagation(X, parameters)
#4.计算代价
cost = compute_cost(Z3, Y)
#5.构建优化器
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
#初始化全部参数
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0
num_minibatches = int(m / minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
minibatch_X, minibatch_Y = minibatch
_, temp_cost = sess.run([optimizer, cost], feed_dict={X:minibatch_X, Y:minibatch_Y})
minibatch_cost += temp_cost / num_minibatches
if print_cost == True and epoch % 5 == 0:
print("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
predict_op = tf.argmax(Z3, 1)
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
调用:
_, _, parameters = model(X_train, Y_train, X_test, Y_test)
运行结果:
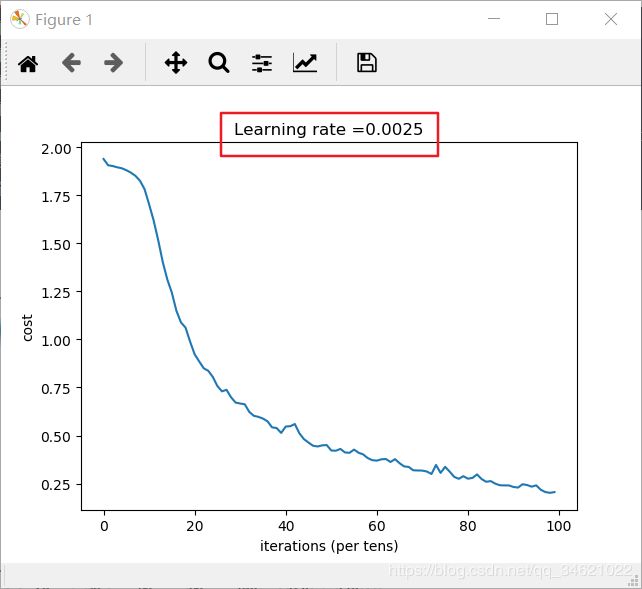
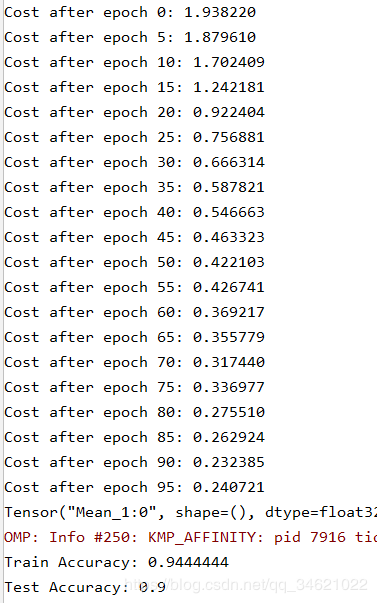
到现在我们已经实现了模型的所有部分,我们可以子集再花时间调整参数,或者加上正则化,以提高准确率。
另附吴老师鼓励大拇指一个!

_, _, parameters = model(X_train, Y_train, X_test, Y_test)
fname = "datasets/thumbs_up.jpg"
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(64, 64))
plt.imshow(my_image)
附加代码:
1.cnn_utils.py
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.python.framework import ops
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples) (m, Hi, Wi, Ci)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) (m, n_y)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[0] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation,:,:,:]
shuffled_Y = Y[permutation,:]
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:,:,:]
mini_batch_Y = shuffled_Y[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[num_complete_minibatches * mini_batch_size : m,:,:,:]
mini_batch_Y = shuffled_Y[num_complete_minibatches * mini_batch_size : m,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)].T
return Y
def forward_propagation_for_predict(X, parameters):
"""
Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
# Numpy Equivalents:
Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3
return Z3
def predict(X, parameters):
W1 = tf.convert_to_tensor(parameters["W1"])
b1 = tf.convert_to_tensor(parameters["b1"])
W2 = tf.convert_to_tensor(parameters["W2"])
b2 = tf.convert_to_tensor(parameters["b2"])
W3 = tf.convert_to_tensor(parameters["W3"])
b3 = tf.convert_to_tensor(parameters["b3"])
params = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
x = tf.placeholder("float", [12288, 1])
z3 = forward_propagation_for_predict(x, params)
p = tf.argmax(z3)
sess = tf.Session()
prediction = sess.run(p, feed_dict = {x: X})
return prediction
#def predict(X, parameters):
#
# W1 = tf.convert_to_tensor(parameters["W1"])
# b1 = tf.convert_to_tensor(parameters["b1"])
# W2 = tf.convert_to_tensor(parameters["W2"])
# b2 = tf.convert_to_tensor(parameters["b2"])
## W3 = tf.convert_to_tensor(parameters["W3"])
## b3 = tf.convert_to_tensor(parameters["b3"])
#
## params = {"W1": W1,
## "b1": b1,
## "W2": W2,
## "b2": b2,
## "W3": W3,
## "b3": b3}
#
# params = {"W1": W1,
# "b1": b1,
# "W2": W2,
# "b2": b2}
#
# x = tf.placeholder("float", [12288, 1])
#
# z3 = forward_propagation(x, params)
# p = tf.argmax(z3)
#
# with tf.Session() as sess:
# prediction = sess.run(p, feed_dict = {x: X})
#
# return prediction