实训日记2:实现卷积神经网络对视线的回归
本次项目的业务实现流程如下:

将输入图像正则化后得到眼部图像e和头部的旋转角度h,然后通过卷积神经网络得到用户的视线角度向量g。其中g是一个2维向量,属性分别为水平方向的视角theta,竖直方向的视角phi。
本篇博客讲述的便是CNN的实现过程。
分析数据
把正则化的.mat数据文件导入matlab分析其结构如下:


left,right分别为左右眼的数据,其中gaze为视线方向,image为眼部图像,pose为头部移动向量。其维度均如图所示。
提取数据
使用scripy.io库即可使用python语言提取.mat文件中的数据,结合本次实验的文件结构,提取代码如下:
from scipy.io import loadmat
from math import *
import numpy as np
def getdata(filename):
m=loadmat(filename)
gaze=m['data'][0][0][0][0][0][0]
image=m['data'][0][0][0][0][0][1]
pose=m['data'][0][0][0][0][0][2]
gaze2=[]
for i in range(len(gaze)):
theta=asin(-gaze[i][1])
phi=atan2(-gaze[i][0],-gaze[i][2])
gaze2.append([theta,phi])
return np.array(gaze2),image,pose
这里使用到了公式
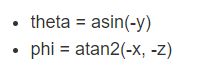
来把3维的gaze向量转化为2维向量。
构建卷积神经网络
本次实训使用的CNN有2个卷积层,分别有20,50个Filters;窗口大小为5*5,步长为1;2个池化层,使用max_pool方法,把图像的长宽均缩小为原来的1/2;全连接层的隐藏层有500个神经元,输出层是2维。有了CNN的结构,再根据之前对输入数据的分析,输入的图像大小为36*60,由此我们便可以写出CNN的代码如下(tensorflow框架):
import tensorflow as tf
import numpy as np
import readMat as rmx
THRESHOLD=0.1
gaze,image,pose=rmx.getdata('MPIIGaze\\Data\\Normalized\\p00\\day01.mat')
for idx in range(1,10):
g,i,p=rmx.getdata('MPIIGaze\\Data\\Normalized\\p0'+str(idx)+'\\day01.mat')
gaze=np.r_[gaze,g]
image=np.r_[image,i]
for idx in range(11,15):
g,i,p=rmx.getdata('MPIIGaze\\Data\\Normalized\\p'+str(idx)+'\\day01.mat')
gaze=np.r_[gaze,g]
image=np.r_[image,i]
state=np.random.get_state()
np.random.shuffle(gaze)
np.random.set_state(state)
np.random.shuffle(image)
tgaze,timage,tpose=rmx.getdata('MPIIGaze\\Data\\Normalized\\p02\\day07.mat')
image=image.reshape(-1,36,60,1)
timage=timage.reshape(-1,36,60,1)
X=tf.placeholder('float',[None,36,60,1])
Y=tf.placeholder('float',[None,2])
def init_weights(shape):
return tf.Variable(tf.random_normal(shape,stddev=0.01))
def init_bias(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
w=init_weights([5,5,1,20])
b=init_bias([20])
w2=init_weights([5,5,20,50])
b2=init_bias([50])
w3=init_weights([9*15*50,500])
b3=init_bias([500])
w_o=init_weights([500,2])
b_o=init_bias([2])
def model(X,w,w2,w3,w_o,p_keep_conv,p_keep_hidden):
l1a=tf.nn.relu(tf.nn.conv2d(X,w,strides=[1,1,1,1],padding='SAME')+b)#34*58
l1=tf.nn.max_pool(l1a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')#17*29
l1=tf.nn.dropout(l1,p_keep_conv)
l2a=tf.nn.relu(tf.nn.conv2d(l1,w2,strides=[1,1,1,1],padding='SAME')+b2)#15*27
l2=tf.nn.max_pool(l2a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')#8*14
l2=tf.reshape(l2,[-1,w3.get_shape().as_list()[0]])
l2=tf.nn.dropout(l2,p_keep_conv)
l3=tf.nn.relu(tf.matmul(l2,w3)+b3)
l3=tf.nn.dropout(l3,p_keep_hidden)
#pyx=tf.matmul(l3,w_o)+b_o
pyx=tf.matmul(l3,w_o)
return pyx
def correctRate(loss):
count=0
length=0
for lo in loss:
if abs(lo[0])这里我定义了一个阈值0.1(=9°),作为判断回归的结果是否正确的标准,当水平和竖直视角theta和phi与正确值的弧度差值均小于0.1时才认为正确。
模型测试
先截取第一天采集的所有数据作为训练集,随机选取除第一天以外的任意一名参与者的数据作为测试集,测试的几组数据结果如下:
//lhm的截图还没有发给我
可见模型对于大部分用户的视线能够有着较为准确的判定,正确率能够达到85%以上,但也存在部分用户的准确率不够高,仅能达到60%左右。
模型改进
经过本次实验,我认为模型可以改进的有如下几点:
- 优化图像正则化的方法,使得图像的特征更明显,更易被泛化
- 在输入数据中加入更多的头部位置信息及相机位置信息,使模型学习到相关的特征
- 增大训练数据集的规模,学习更多的泛化特征