回文自动机算法+马拉车算法概述及习题【回文串系列问题】
M a n a c h e r Manacher Manacher 概述
一、适用问题
M a n a c h e r Manacher Manacher 算法主要解决的是给出一个字符串, O ( n ) O(n) O(n) 复杂度下求出以字符串中任意一个节点为中心所能扩展的最大距离。
二、算法解析
扩充字符串
为了统一奇偶字符串,算法首先在每两个字符(包括头尾)之间加没出现的字符(如*),这样所有字符串长度就都是奇数了,简化了问题。
- a b c d e ⟶ ∗ a ∗ b ∗ c ∗ d ∗ e ∗ abcde\longrightarrow *a*b*c*d*e* abcde⟶∗a∗b∗c∗d∗e∗
具体 d p dp dp 过程
记录 p i p_i pi 表示 i i i 能向两边推(包括 i i i)的最大距离,如果能求出 p p p 数组,那每一个回文串就都确定了。
我们假设 p [ 1 ~ i ] p[1~i] p[1~i] 已经求好了,现在要求 p [ i ] p[i] p[i]。假设之前能达到的最右边为 R R R,对应的中点为 p o s pos pos, j j j 是 i i i 的对称点。
- 第一种情况, i + p [ j ] < R i+p[j]
i+p[j]<R ,即 p [ i ] = p [ j ] p[i]=p[j] p[i]=p[j]。

- 第二种情况, i + p [ j ] ≥ R i+p[j]\geq R i+p[j]≥R,先设 p [ i ] = R − i p[i]=R-i p[i]=R−i ,然后再继续增加 p [ i ] p[i] p[i],并令 p o s = i pos=i pos=i,更新 R R R。
由于 R R R 一定是递增的,因此时间复杂度为 O ( n ) O(n) O(n),可以发现一个串本质不同的回文串最多有 n n n 个,因此只有 R R R 增加的时候才会产生本质不同的回文串。
算法特点
- M a n a c h e r Manacher Manacher 充分利用了回文的性质,从而达到线性时间。
- M a n a c h e r Manacher Manacher 右端点递增过程中产生了所有的本质不同回文串,即一个串中本质不同回文串最多只有 n n n 个。
- M a n a c h e r Manacher Manacher 算法的核心在于求出每一个节点往两边推的最远距离,所有涉及该算法的问题也都是在这个功能上做文章。
三、 M a n a c h e r Manacher Manacher 模板
void Manacher(char s1[]){
int len, tot, R = 0, pos = 0;
//对字符串加'#'号
len = strlen(s1+1);
s2[0] = '$';
s2[ln=1]='#';
for(int i = 1; i <= len; i++)
s2[++ln] = s1[i], s2[++ln] = '#';
//求p[i]数组
for(int i = 1; i <= ln; i++){
if(R >= i) p[i] = min(p[pos*2-i],R-i+1);
if(p[i] + i > R){
for(; s2[R+1] == s2[i*2-R-1] && R+1 <= ln && i*2-R-1 <= ln; R++); //小心多组数据
pos = i;
p[i] = R-i+1;
}
}
}
回文自动机概述
一、适用问题
回文自动机其实可以当作回文串问题的大杀器,主要可以解决以下问题:
- 本质不同回文串个数
- 每个本质不同回文串出现的次数
- 以某一个节点为结尾的回文串个数
- …
而且都是在 O(n) 的复杂度内解决了这些问题。但是要注意,回文自动机并不能完全替代马拉车算法,因为马拉车针对的是以一个节点为中心所能扩展的最远的距离,而回文自动机更多的是处理以一个节点为结尾的回文串数量。
二、算法解析
基础思想
与 A C AC AC自动机一样,回文自动机的构造也使⽤了 T r i e Trie Trie树的结构。
不同点在于回文自动机有两个根,一个是偶数⻓度回⽂串的根,一个是奇数⻓度回⽂串的根,简称为奇根和偶根。自动机中每个节点表⽰⼀个回⽂串,且都有⼀个 f a i l fail fail 指针,指向当前节点所表⽰的回文串的最长回文后缀(不包括其本身)。
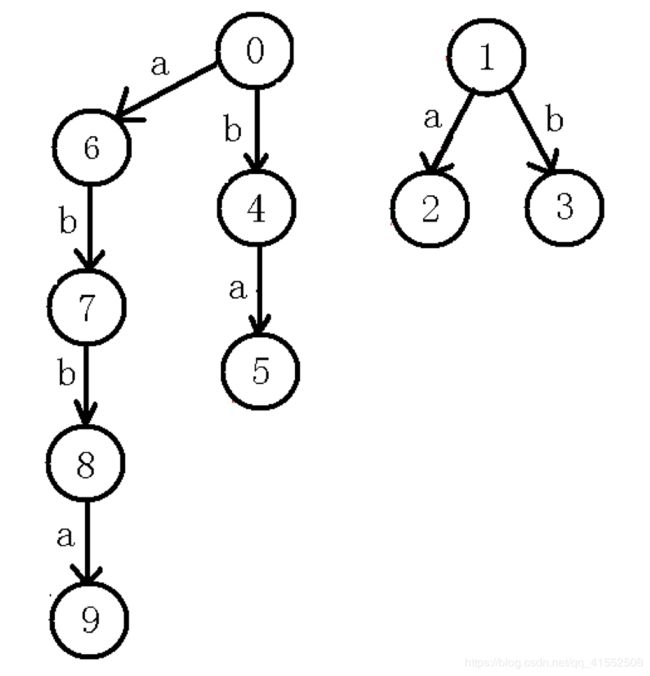
具体构建过程
首先将偶根的 f a i l fail fail 指针指向奇根,奇根的 f a i l fail fail 指针指向偶根,然后令奇根的长度为 − 1 -1 −1,偶根长度为 1 1 1。
在构建过程中,始终要记录一个 l a s t last last 指针,表示上一次插入之后所位于的回文自动机节点。然后判断插入当前节点之后是否能够形成一个新的回文串,如果不能则跳 f a i l fail fail 指针,整体逻辑与 A C AC AC自动机的构建没有太大差别。
f a i l fail fail 指针表示当前节点所代表的回文串的最长后缀回文串,此处 f a i l fail fail指针的定义与 A C AC AC自动机有一定区别,但本质目的相同,都是为了尽可能地保存之前的匹配结果。
而 f a i l fail fail 指针的构建是根据当前节点的父节点的 f a i l fail fail 节点构建而来,与 A C AC AC自动机的 f a i l fail fail 构建没有太大差别。
大致上就是这样一个构建过程,具体细节可以查看下述模板,也可以查看 o i w i k i oi_wiki oiwiki 的图解构建。
统计每个本质不同回文串的出现次数
与 A C AC AC自动机一样,每个节点所代表字符串出现的次数要加上其所有 f a i l fail fail 子孙出现的次数,因此需要倒序遍历所有节点将节点出现次数累加到其 f a i l fail fail 节点上。
三、回文自动机模板
#include 回文串系列习题
1. P1659 [国家集训队] 拉拉队排练
题意: n n n 个字符,找出其中所有的奇长度回文串,按长度降序排列,求出前 k k k 个回文串长度的乘积。 ( 1 ≤ n ≤ 1 0 6 , 1 ≤ k ≤ 1 0 12 ) (1\leq n\leq 10^6,1\leq k\leq 10^{12}) (1≤n≤106,1≤k≤1012)
思路: 模板题。直接对于所有本质不同回文串求出其个数,然后用 p a i r pair pair 存到 v e c t o r vector vector 中,再利用快速幂计算答案即可。
代码:
#include 2. P3649 [APIO2014] 回文串
题意: 给定一个长度为 n n n 的字符串 s s s,我们定义 s s s 的一个子串的存在值为这个子串在 s s s 中出现的次数乘以这个子串的长度,输出所有回文子串的最大存在值。 ( 1 ≤ n ≤ 3 ∗ 1 0 5 ) (1\leq n\leq 3*10^5) (1≤n≤3∗105)
思路: 模板题。直接求出每一个子串的出现次数,然后对于所有节点统计答案即可。(模板题贴一份代码即可)
3. P5496 回文自动机(PAM)
题意: 给定一个长度为 n n n 的字符串,求出以每个节点为结尾的回文子串个数。 ( 1 ≤ n ≤ 5 ∗ 1 0 5 ) (1\leq n\leq 5*10^5) (1≤n≤5∗105)
思路: 模板题。 P A M PAM PAM 的 i n s e r t insert insert 函数中自带以该节点为结尾的回文子串数的求解。(模板题贴一份代码即可,主要目的就是练练手)
4. P4287 [SHOI2011] 双倍回文
题意: 给定一个长度为 n n n 的字符串,询问该字符串中长度最长的双倍回文串的长度。双倍回文串指 A A T A A T AA^TAA^T AATAAT,如 a b b a a b b a abbaabba abbaabba 即是双倍回文串,而 a b a b a ababa ababa 则不是。 ( 1 ≤ n ≤ 5 ∗ 1 0 5 ) (1\leq n\leq 5*10^5) (1≤n≤5∗105)
思路: 由于只需要求最长回文串,并不要求输出个数,因此我们直接在 M a n a c h e r Manacher Manacher 的 d p dp dp 过程中求出答案即可。
首先明确一点, M a n a c h e r Manacher Manacher 右端点递增过程中,涉及到了所有的本质不同回文串,因此我们在每次右端点递增时,令当前节点为双倍回文串的中心节点,然后查询左半部分是否也为一个回文串,如果是则更新答案。
变型: 当然此题也可以进行延伸,可以将查询内容改成有多少个双倍回文串。如果询问有多少个双倍回文串的话,我的想法是用回文自动机+ M a n a c h e r Manacher Manacher 算法进行解决。
首先 M a n a c h e r Manacher Manacher 求出每一个节点为中心所能扩展的最远距离。然后在根据当前字符串建立回文自动机,并且在构建时对于每个节点记录构成该节点的末尾坐标 p o s pos pos,之后再遍历回文自动机上的所有节点,利用 M a n a c h e r Manacher Manacher 计算的 p p p 数组来验证该节点所代表的回文串是否是双倍回文串即可。
代码:
#include 5. iChandu
题意: 给定一个长度为 n n n 的字符串,先可以选择该字符串中的一个节点,将其替换成 & \& & 符号,问替换之后该字符串中本质不同回文串个数。 ( 1 ≤ n ≤ 5 ∗ 1 0 5 ) (1\leq n\leq 5*10^5) (1≤n≤5∗105)
思路: 一个比较明显的考虑方式就是枚举替换的位置,然后计算该位置改变后增加的回文串数量与减少的回文串数量。
首先我们考虑增加的回文串数量,显然就是以该节点为中心所形成的回文串总数,因此我们直接用马拉车的 p p p 数组进行求解即可。
然后再来考虑减少的回文串数量。我们对于回文自动机中所有本质不同回文串的末尾出现位置记录一个 m x mx mx 和 m i mi mi,表示最远出现的位置和最早出现的位置,记该回文串长度为 l e n len len。则如果 m x − l e n + 1 ≤ m i mx-len+1\leq mi mx−len+1≤mi ,则修改位置出现在 [ m x − l e n + 1 , m i ] [mx-len+1,mi] [mx−len+1,mi] 中时,本质不同回文串数量就会减 1 1 1,因此我们维护一个差分数组, s u m [ m x − l e n + 1 ] sum[mx-len+1] sum[mx−len+1] 加 1 1 1, s u m [ m i ] sum[mi] sum[mi] 减 1 1 1,然后对于每个自动机上的节点都这样处理一遍即可。
最后再枚举替换点统计答案。
代码:
#include 6. The Problem to Slow Down You
题意: 给定两个字符串,询问满足条件的四元组个数, ( x , y , u , v ) (x,y,u,v) (x,y,u,v) 满足条件当且仅当 s [ x . . . y ] = h [ u . . . v ] s[x...y]=h[u...v] s[x...y]=h[u...v],且 s [ x . . . y ] s[x...y] s[x...y] 为回文串。 ( 1 ≤ n ≤ 1 0 5 ) (1\leq n\leq 10^5) (1≤n≤105)
思路: 建两颗回文自动机,然后从奇根和偶根分别遍历,同时遍历两棵树,如果到达相同位置则计算对答案的贡献,也算是比较裸的一道题目。
代码:
#include 7. Finding Palindromes
题意: 给出 n n n 个字符串,求解在其中 n ∗ n n*n n∗n 个拼接中,回文串的数量。 ( ∑ l e n ( i ) ≤ 2 ∗ 1 0 6 ) (\sum len(i)\leq 2*10^6) (∑len(i)≤2∗106)
思路: 考虑马拉车+字典树解决该问题。
两个串拼在一起是回文串,即 s s s 与 h h h 拼接之后为回文串,主要有两种情况。
- ∣ s ∣ ≤ ∣ h ∣ |s|\leq |h| ∣s∣≤∣h∣,则将 s s s 与 h h h 的反串进行匹配, h h h 中剩下的未匹配部分为回文串。
- ∣ h ∣ ≤ ∣ s ∣ |h|\leq |s| ∣h∣≤∣s∣,则将 s s s 与 h h h 的反串进行匹配, s s s 中剩下的未匹配部分为回文串。
分类完之后即可用马拉车算法求出回文串范围,然后用字典树进行反串匹配。
代码: 此题细节很多,非常容易写到一半进入暴躁模式…
还有就是我对拍了 55 w 55w 55w 组数据还没拍出错,但是就是过不了是为什么!暴躁!(现在过了…是空间开小了…脑子不清醒的作品…悄咪咪地放上代码…)
#include 后记
A C M ACM ACM 的旅行充满荆棘但一抬头便能看见无数束光,继续坚持,努力前行!???
本篇博客到这里就结束了,祝大家 A C AC AC 愉快,一起爱上回文串把!(๑•̀ㅂ•́)و✧