计算智能——混合遗传算法
目录
遗传算法
遗传算法思想
遗传算法的求解步骤
遗传算法实现TSP问题
实验数据
实验代码
实验调整参数展示
实验总结
遗传算法
遗传算法的求解步骤
步骤1:构造满足约束条件的染色体。由于遗传算法不能直接处理解空间中的解,所以必须通过编码将解表示成适当的染色体。实际问题的染色体有多种编码方式,染色体编码方式的选取应尽可能地符合问题约束,否则将影响计算效率。
步骤2:随机产生初始群体。初始群体是搜索开始时的一组染色体,其数量应适当选择。
步骤3:计算每个染色体的适应度。适应度是反映染色体优劣的唯一指标,遗传算法就是要寻找适应度最大的染色体。
步骤4:使用复制、交叉和变异算子产生子群体。这三个算子是遗传算法的基本算子, 其中复制体现了优胜劣汰的自然规律,交叉体现了有性繁殖的思想,变异体现了进化过程中的基因突变。
步骤5:若满足终止条件,则输出搜索结果;否则返回步骤3。
遗传交叉算法如下图
变异算法则是选定任意两个基因段互相交换
遗传算法实现TSP问题
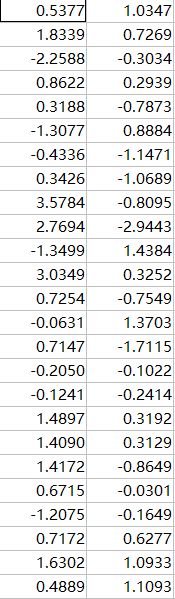
实验数据
25个城市坐标
实验代码
交叉操作函数 cross.m
%交叉操作函数 cross.m
function [A,B]=cross(A,B)
L=length(A);
if L<10
W=L;
elseif ((L/10)-floor(L/10))>=rand&&L>10
W=ceil(L/10)+8;
else
W=floor(L/10)+8;
end
%%W为需要交叉的位数
p=unidrnd(L-W+1);%随机产生一个交叉位置
%fprintf('p=%d ',p);%交叉位置
for i=1:W
x=find(A==B(1,p+i-1));
y=find(B==A(1,p+i-1));
[A(1,p+i-1),B(1,p+i-1)]=exchange(A(1,p+i-1),B(1,p+i-1));
[A(1,x),B(1,y)]=exchange(A(1,x),B(1,y));
end
end
对调函数 exchange.m
function [x,y]=exchange(x,y)
temp=x;
x=y;
y=temp;
end
适应度函数fit.m
function fitness=fit(len,m,maxlen,minlen)
fitness=len;
for i=1:length(len)
fitness(i,1)=(1-(len(i,1)-minlen)/(maxlen-minlen+0.0001)).^m;
end
变异函数 Mutation.m
function a=Mutation(A)
index1=0;index2=0;
nnper=randperm(size(A,2));
index1=nnper(1);
index2=nnper(2);
%fprintf('index1=%d ',index1);
%fprintf('index2=%d ',index2);
temp=0;
temp=A(index1);
A(index1)=A(index2);
A(index2)=temp;
a=A;
end染色体的路程代价函数 mylength.m
function len=myLength(D,p)%p是一个排列
[N,NN]=size(D);
len=D(p(1,N),p(1,1));
for i=1:(N-1)
len=len+D(p(1,i),p(1,i+1));
end
end连点画图函数 plot_route.m
function plot_route(a,R)
scatter(a(:,1),a(:,2),'rx');
hold on;
plot([a(R(1),1),a(R(length(R)),1)],[a(R(1),2),a(R(length(R)),2)]);
hold on;
for i=2:length(R)
x0=a(R(i-1),1);
y0=a(R(i-1),2);
x1=a(R(i),1);
y1=a(R(i),2);
xx=[x0,x1];
yy=[y0,y1];
plot(xx,yy);
hold on;
end
end
main函数
%main
clear;
clc;
%%%%%%%%%%%%%%%输入参数%%%%%%%%
N=25; %%城市的个数
M=100; %%种群的个数
ITER=2000; %%迭代次数
%C_old=C;
m=2; %%适应值归一化淘汰加速指数
Pc=0.8; %%交叉概率
Pmutation=0.05; %%变异概率
%%生成城市的坐标
pos=randn(N,2);
%%生成城市之间距离矩阵
D=zeros(N,N);
for i=1:N
for j=i+1:N
dis=(pos(i,1)-pos(j,1)).^2+(pos(i,2)-pos(j,2)).^2;
D(i,j)=dis^(0.5);
D(j,i)=D(i,j);
end
end
%%生成初始群体
popm=zeros(M,N);
for i=1:M
popm(i,:)=randperm(N);%随机排列,比如[2 4 5 6 1 3]
end
%%随机选择一个种群
R=popm(1,:);
figure(1);
scatter(pos(:,1),pos(:,2),'rx');%画出所有城市坐标
axis([-3 3 -3 3]);
figure(2);
plot_route(pos,R); %%画出初始种群对应各城市之间的连线
axis([-3 3 -3 3]);
%%初始化种群及其适应函数
fitness=zeros(M,1);
len=zeros(M,1);
for i=1:M%计算每个染色体对应的总长度
len(i,1)=myLength(D,popm(i,:));
end
maxlen=max(len);%最大回路
minlen=min(len);%最小回路
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);%找到最小值的下标,赋值为rr
R=popm(rr(1,1),:);%提取该染色体,赋值为R
for i=1:N
fprintf('%d ',R(i));%把R顺序打印出来
end
fprintf('\n');
fitness=fitness/sum(fitness);
distance_min=zeros(ITER+1,1); %%各次迭代的最小的种群的路径总长
nn=M;
iter=0;
while iter<=ITER
fprintf('迭代第%d次\n',iter);
%%选择操作
p=fitness./sum(fitness);
q=cumsum(p);%累加
for i=1:(M-1)
len_1(i,1)=myLength(D,popm(i,:));
r=rand;
tmp=find(r<=q);
popm_sel(i,:)=popm(tmp(1),:);
end
[fmax,indmax]=max(fitness);%求当代最佳个体
popm_sel(M,:)=popm(indmax,:);
%%交叉操作
nnper=randperm(M);
% A=popm_sel(nnper(1),:);
% B=popm_sel(nnper(2),:);
%%
for i=1:M*Pc*0.5
A=popm_sel(nnper(i),:);
B=popm_sel(nnper(i+1),:);
[A,B]=cross(A,B);
% popm_sel(nnper(1),:)=A;
% popm_sel(nnper(2),:)=B;
popm_sel(nnper(i),:)=A;
popm_sel(nnper(i+1),:)=B;
end
%%变异操作
for i=1:M
pick=rand;
while pick==0
pick=rand;
end
if pick<=Pmutation
popm_sel(i,:)=Mutation(popm_sel(i,:));
end
end
%%求适应度函数
NN=size(popm_sel,1);
len=zeros(NN,1);
for i=1:NN
len(i,1)=myLength(D,popm_sel(i,:));
end
maxlen=max(len);
minlen=min(len);
distance_min(iter+1,1)=minlen;
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);
fprintf('minlen=%d\n',minlen);
R=popm_sel(rr(1,1),:);
for i=1:N
fprintf('%d ',R(i));
end
fprintf('\n');
popm=[];
popm=popm_sel;
iter=iter+1;
%pause(1);
end
%end of while
figure(3)
plot_route(pos,R);
axis([-3 3 -3 3]);
figure(4)
plot(distance_min);
实验调整参数展示
1.调整M 种群的个数
1)M=50
2)M=100
3)M=200
分析:根据运行结果很清楚的看到,M=100比其他两个参数设置所得到的最短路径结果会更好。
所以当M设置的比较大时,种群个数过多,导致运算量增大,影响算法的搜索能力和运行效率
当M设置比较小时,种群个数较少,所包含的染色体信息也更少,会直接影响到算法准确性
2.调整m 适应值归一化淘汰加速指数
1)m=1
2)m=2
![]()
3)m=3
分析:从实验结果可以看出,m=2比其他两个参数设置所得到的最短路径结果会更好
适应值会影响算法对种群的选择,适应值归一化淘汰加速指数最好设置为较小
3.调整Pc 交叉概率
1)Pc=0.6
2)Pc=0.8
![]()
3)Pc=1.0
分析:从实验结果可以看出,Pc=0.8比其他参数设置所得到的最短路径结果会更好
当交叉概率较小时,染色体难以发生交配会使得较难获得较优解
交叉概率决定了进化过程种群参加交配的染色体平均数目,取值一般为0.5~0.9
4.调整Pmutation 变异概率
1)Pmutation=0.01
2)Pc=0.05
![]()
3)Pc=0.1
4)Pc=0.3
分析:从实验结果可以看出,Pmutation=0.05比其他参数设置所得到的最短路径结果会更好
当变异概率比较低,且种群较小时,几乎不会有变异的情况
当变异概率比较大时,可能难以找到较优解或者直接破坏较优解的结果
实验总结
通过多次对种群的个数、适应值归一化淘汰加速指数、交叉概率、变异概率参数的调试,可以发现:
群体规模影响算法的搜索能力和运行效率,变异概率影响群体进化的多样性等等,因此每个参数都有其合理的设置区间
最终确立了一组较好的参数:
M=100; m=2; Pc=0.8; Pmutation=0.05;
从多次的实验结果可以看出,基本上每次实验都是在500次以内函数趋近收敛,设置不同的参数会直接影响较优解的结果