验证码识别
代码运行的环境:
win10系统、pycharm2019.1、anaconda3
需要导入的包:
tensorflow、numpy、random、captcha、matplotlib、PIL等
导入包的方法:
在命令提示符中输入pip install+包名
首先我们应该先明确字符型验证码识别的流程,在一般情况下,对于字符型验证码的识别流程如下:
1.准备原始图片素材
2.图片预处理
3.图片字符切割
4.图片尺寸归一化
5.图片字符标记
6.字符图片特征提取
7.生成特征和标记对应的训练数据集
8.训练特征标记数据生成识别模型
9.使用识别模型预测新的未知图片集
10.达到根据“图片”就能返回识别正确的字符集的目标
当明确代码流程后,我们还要清楚我们需要哪种数据集。生活中,验证码可以有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的密码尝试,实际上用验证码是很多网站通行的方式。我们需要先明确我们需要的是哪种验证码,只有数字、数字加字母、文字等。验证码中字符种类不同,排列组合后验证码的张数也不同。
本文选择的是只有数字的验证码图片,每张图片内有四个字符
下面将介绍代码实现的流程
第一部分 生成验证码图片
1、导入包
from captcha.image import ImageCaptcha
import random
import sys
2、数字、大小写字母
number = [‘0’,‘1’,‘2’,‘3’,‘4’,‘5’,‘6’,‘7’,‘8’,‘9’]
alphabet =[‘a’,‘b’,‘c’,‘d’,‘e’,‘f’,‘g’,‘h’,‘i’,‘j’,‘k’,‘l’,‘m’,‘n’,‘o’,‘p’,‘q’,‘r’,‘s’,‘t’,‘u’,‘v’,‘w’,‘x’,‘y’,‘z’]
ALPHABET [‘A’,‘B’,‘C’,‘D’,‘E’,‘F’,‘G’,‘H’,‘I’,‘J’,‘K’,‘L’,‘M’,‘N’,‘O’,‘P’,‘Q’,‘R’,‘S’,‘T’,‘U’,‘V’,‘W’,‘X’,‘Y’,‘Z’]
3、随机生成验证码文本
def random_captcha_text(char_set=number+alphabet+ALPHABET,
captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append©
return captcha_text
4、生成字符对应的验证码
def gen_captcha_text_and_image():
image = ImageCaptcha()
captcha_text = random_captcha_text()
captcha_text = ‘’.join(captcha_text)
captcha = image.generate(captcha_text)
image.write(captcha_text, ‘D:/pycharm/project/text7验证码识别/images/’ + captcha_text + ‘.jpg’)
5、数量少于10000,因为重名
num = 10000 if name == ‘main’:
for i in range(num):
gen_captcha_text_and_image()
sys.stdout.write(’\r>> Creating image %d/%d’ % (i+1, num))
sys.stdout.flush()
sys.stdout.write(’\n’)
sys.stdout.flush()
print(“生成完毕”)
第二部分 生成tfrecord文件
1、导入包
import tensorflow as tf
import os
import random
import math import sys
from PIL import Image import numpy as np
2、初始化
#验证集数量
_NUM_TEST = 500
#随机种子
_RANDOM_SEED = 0
#数据集路径
DATASET_DIR = “D:/pycharm/project/text7验证码识别/images/”
#tfrecord文件存放路径
TFRECORD_DIR = “D:/pycharm/project/text7验证码识别/”
tfrecord数据文件是一种将图像数据和标签统一存储的二进制文件,能更好的利用内存,在tensorflow中快速的复制,移动,读取,存储
3、判断tfrecord文件是否存在
def _dataset_exists(dataset_dir):
for split_name in [‘train’, ‘test’]:
output_filename = os.path.join(dataset_dir,split_name + ‘.tfrecords’)
if not tf.gfile.Exists(output_filename):
return False
return True
4、获取所有验证码图片
def _get_filenames_and_classes(dataset_dir):
photo_filenames = []
for filename in os.listdir(dataset_dir):
#获取文件路径
path = os.path.join(dataset_dir, filename)
photo_filenames.append(path)
return photo_filenames
一个Example中包含Features,Features里包含Feature(这里没s)的字典,Feature里包含有一个 FloatList, 或者ByteList,或者Int64List
def int64_feature(values):
if not isinstance(values, (tuple, list)):
values = [values]
return tf.train.Feature(int64_list=tf.train.Int64List(value=values))def bytes_feature(values):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[values]))
5、将数据写入tfrecords文件
tf.train.Example(features = None),用于写入tfrecords文件,features : tf.train.Features类型的特征实例,返回example协议格式块
def image_to_tfexample(image_data, label0, label1, label2, label3):
#Abstract base class for protocol messages.
return tf.train.Example(features=tf.train.Features(feature={
‘image’: bytes_feature(image_data),
‘label0’: int64_feature(label0),
‘label1’: int64_feature(label1),
‘label2’: int64_feature(label2),
‘label3’: int64_feature(label3),
}))
6、把数据转为TFRecord格式
def _convert_dataset(split_name, filenames, dataset_dir):
assert split_name in [‘train’, ‘test’]
7、创建会话
将tfrecord中的数据读取出来,处理图片,把三位彩色图片转为黑白一维图片
with tf.Session() as sess:
#定义tfrecord文件的路径+名字
output_filename = os.path.join(TFRECORD_DIR,split_name + ‘.tfrecords’)
with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer:
#通过tf.python_io.TFRecordWriter class中的write方法将tfrecord文件写入到output_filename
for i,filename in enumerate(filenames):
try:
sys.stdout.write(’\r>> Converting image %d/%d’ % (i+1, len(filenames)))
sys.stdout.flush()
#读取图片
image_data = Image.open(filename)
#根据模型的结构resize
image_data = image_data.resize((224, 224))
#灰度化
image_data = np.array(image_data.convert(‘L’))
#将图片转化为bytes,图片转化成字节
image_data = image_data.tobytes()
#获取label,split(’/’)[-1]以‘/ ’为分割f符,保留最后一段
labels = filename.split(’/’)[-1][0:4]
num_labels = []
for j in range(4):
num_labels.append(int(labels[j]))
#生成protocol数据类型
example = image_to_tfexample(image_data, num_labels[0], num_labels[1], num_labels[2], num_labels[3])
tfrecord_writer.write(example.SerializeToString())#序列转化成字符串
except IOError as e:
print(‘Could not read:’,filename)
print(‘Error:’,e)
print(‘Skip it\n’)
sys.stdout.write(’\n’)
sys.stdout.flush()
8、判断tfrecord文件是否存在
if _dataset_exists(TFRECORD_DIR):
print(‘tfcecord文件已存在’) else:
#获得所有图片
photo_filenames = _get_filenames_and_classes(DATASET_DIR)
9、把数据切分为训练集和测试集,并打乱
验证集数量_NUM_TEST = 500 随机种子_RANDOM_SEED = 0
random.seed(_RANDOM_SEED)
random.shuffle(photo_filenames)
training_filenames = photo_filenames[_NUM_TEST:]
testing_filenames = photo_filenames[:_NUM_TEST]
10、数据转换
_convert_dataset(‘train’, training_filenames, DATASET_DIR)
_convert_dataset(‘test’, testing_filenames, DATASET_DIR)
print(‘生成tfcecord文件’)
第三部分 训练生成模型
轮数设置为10000轮,一个批次喂入25张图片训练,每25张图片训练一次 将25张图片全部装载大文件名队列,装载10000次,内存队列会从队列中读取图片
1、导入包
import os
import tensorflow as tf
from PIL import Image
from nets import nets_factory
import numpy as np
2、初始化
#不同字符数量
CHAR_SET_LEN = 10
#图片高度
IMAGE_HEIGHT = 60
#图片宽度
IMAGE_WIDTH = 160
#批次
BATCH_SIZE = 25
3、tfrecord文件存放路径
TFRECORD_FILE = “D:/pycharm/project/text7验证码识别/train.tfrecords”
4、初始化
placeholder()函数是在神经网络构建graph的时候在模型中的占位
x = tf.placeholder(tf.float32, [None, 224, 224])
y0 =tf.placeholder(tf.float32, [None])
y1 = tf.placeholder(tf.float32,[None])
y2 = tf.placeholder(tf.float32, [None])
y3 = tf.placeholder(tf.float32, [None])
lr = tf.Variable(0.003, dtype=tf.float32)#学习率
5、从tfrecord读出数据
获取图片数据和标签数据
def read_and_decode(filename):
# 根据文件名生成一个队列
filename_queue = tf.train.string_input_producer([filename])
#creat a reader from file queue
reader = tf.TFRecordReader()
# reader从文件队列中读入一个序列化的样本,返回文件名和文件
_, serialized_example = reader.read(filename_queue)
#解析符号化样本,将Example协议缓冲区(protocol buffer)解析为张量
features = tf.parse_single_example(serialized_example,
features={
‘image’ : tf.FixedLenFeature([], tf.string),
‘label0’: tf.FixedLenFeature([], tf.int64),
‘label1’: tf.FixedLenFeature([], tf.int64),
‘label2’: tf.FixedLenFeature([], tf.int64),
‘label3’: tf.FixedLenFeature([], tf.int64),
})
# 获取图片数据
image = tf.decode_raw(features[‘image’], tf.uint8)
# tf.train.shuffle_batch必须确定shape
#没有经过预处理的灰度图
image = tf.reshape(image, [224, 224])
6、图片预处理
图像归一化,对于图片上的像素点,值域在0到255之间,图片如果是彩色,那么实际上会有三个通道,这里都是黑白色,所以,只有一个通道,取图片上真实像素点的值,除以255进行归一化即可
image = tf.cast(image, tf.float32) / 255.0
tf.subtract减法操作 tf.multiply将两个矩阵中对应元素各自相乘
tf.cast类型转换函数
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
7、获取图片数据和标签
label0 = tf.cast(features[‘label0’], tf.int32)
label1 = tf.cast(features[‘label1’], tf.int32)
label2 = tf.cast(features[‘label2’], tf.int32)
label3 = tf.cast(features[‘label3’], tf.int32)
return image, label0, label1, label2, label3
image, label0, label1, label2, label3 = read_and_decode(TFRECORD_FILE)
使用shuffle_batch可以随机打乱输入 next_batch挨着往下,shuffle_batch才能实现[img,label]的同步,也即特征和label的同步,不然可能输入的特征和label不匹配,比如只有这样使用,才能使img和label一一对应,每次提取一个image和对应的label,shuffle_batch返回的值就是RandomShuffleQueue.dequeue_many()的结果,Shuffle_batch构建了一个RandomShuffleQueue,并不断地把单个的[img,label],送入队列中
image_batch, label_batch0, label_batch1, label_batch2, label_batch3 =tf.train.shuffle_batch( [image, label0, label1, label2, label3], batch_size = BATCH_SIZE,capacity = 50000, min_after_dequeue=10000, num_threads=1)
8、定义网络结构
train_network_fn = nets_factory.get_network_fn(
‘alexnet_v2’,
num_classes=CHAR_SET_LEN,
weight_decay=0.0005,
is_training=True)
9、创建会话
with tf.Session() as sess:
X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1]) # inputs: a tensor of size [batch_size, height, width, channels]
# 数据输入网络得到输出值
logits0,logits1,logits2,logits3,end_points = train_network_fn(X)
# 把标签转成one_hot的形式
one_hot_labels0 = tf.one_hot(indices=tf.cast(y0, tf.int32), depth=CHAR_SET_LEN)
one_hot_labels1 = tf.one_hot(indices=tf.cast(y1, tf.int32), depth=CHAR_SET_LEN)
one_hot_labels2 = tf.one_hot(indices=tf.cast(y2, tf.int32), depth=CHAR_SET_LEN)
one_hot_labels3 = tf.one_hot(indices=tf.cast(y3, tf.int32), depth=CHAR_SET_LEN)
# 计算loss
loss0=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits0,labels=one_hot_labels0))
loss1=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits1,labels=one_hot_labels1))
loss2=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits2,labels=one_hot_labels2))
loss3=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits3,labels=one_hot_labels3))
# 计算总的loss
total_loss = (loss0+loss1+loss2+loss3)/4.0
# 优化total_loss
optimizer=tf.train.AdamOptimizer(learning_rate=lr).minimize(total_loss)
# 计算准确率
correct_prediction0=tf.equal(tf.argmax(one_hot_labels0,1),tf.argmax(logits0,1))
accuracy0 = tf.reduce_mean(tf.cast(correct_prediction0,tf.float32))
correct_prediction1=tf.equal(tf.argmax(one_hot_labels1,1),tf.argmax(logits1,1))
accuracy1 = tf.reduce_mean(tf.cast(correct_prediction1,tf.float32))
correct_prediction2 = tf.equal(tf.argmax(one_hot_labels2,1),tf.argmax(logits2,1))
accuracy2 = tf.reduce_mean(tf.cast(correct_prediction2,tf.float32))
correct_prediction3 = tf.equal(tf.argmax(one_hot_labels3,1),tf.argmax(logits3,1))
accuracy3 = tf.reduce_mean(tf.cast(correct_prediction3,tf.float32))
# 用于保存模型
saver = tf.train.Saver()
# 初始化
sess.run(tf.global_variables_initializer())
# 创建一个协调器,管理线程
coord = tf.train.Coordinator()
# 启动QueueRunner, 此时文件名队列已经进队
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(10001):#训练10000轮
# 获取一个批次的数据和标签
b_image, b_label0, b_label1 ,b_label2 ,b_label3 = sess.run([image_batch, label_batch0, label_batch1, label_batch2,
label_batch3])
# 优化模型
sess.run(optimizer, feed_dict={x: b_image, y0:b_label0, y1: b_label1, y2: b_label2, y3: b_label3})
# 每迭代20次计算一次loss和准确率
if i % 20== 0:
# 每迭代2000次降低一次学习率
if i%2000 == 0:
sess.run(tf.assign(lr, lr/3))
acc0,acc1,acc2,acc3,loss_ = sess.run([accuracy0,accuracy1,accuracy2,accuracy3,total_loss],feed_dict={x:
b_image,
y0: b_label0,
y1: b_label1,
y2: b_label2,
y3: b_label3})
learning_rate = sess.run(lr)
print (“Iter:%d Loss:%.3f Accuracy:%.2f,%.2f,%.2f,%.2f Learning_rate:%.4f” % (i,loss_,acc0,acc1,acc2,acc3,learning_rate))
# 保存模型
# if acc0 > 0.90 and acc1 > 0.90 and acc2 > 0.90 and acc3 > 0.90:
if i==100:#如果到100轮保存模型
saver.save(sess, “D:/pycharm/project/text7验证码识别/models/crack_captcha.model”,
global_step=i)
break
# 通知其他线程关闭
coord.request_stop()
# 其他所有线程关闭之后,这一函数才能返回
coord.join(threads)
第四部分 测试
1、导入模块
import os
import tensorflow as tf
from PIL import Image from nets
import nets_factory
import numpy as np
import matplotlib.pyplot as plt
2、初始化
不同字符数量
CHAR_SET_LEN = 10
图片高度
IMAGE_HEIGHT = 60
图片宽度
IMAGE_WIDTH = 160
批次,10个样本,每次取一个样本测试
BATCH_SIZE = 1
tfrecord文件存放路径
TFRECORD_FILE = “D:/pycharm/project/text7验证码识别/test.tfrecords”
placeholder占位
x = tf.placeholder(tf.float32, [None, 224, 224])
3、从tfrecord读出数据
def read_and_decode(filename):
# 根据文件名生成一个队列
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
# 返回文件名和文件
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
‘image’ : tf.FixedLenFeature([], tf.string),
‘label0’: tf.FixedLenFeature([], tf.int64),
‘label1’: tf.FixedLenFeature([], tf.int64),
‘label2’: tf.FixedLenFeature([], tf.int64),
‘label3’: tf.FixedLenFeature([], tf.int64),
})
# 获取图片数据
image = tf.decode_raw(features[‘image’], tf.uint8)
# 没有经过预处理的灰度图
image_raw = tf.reshape(image, [224, 224])
# tf.train.shuffle_batch必须确定shape
image = tf.reshape(image, [224, 224])
# 图片预处理
image = tf.cast(image, tf.float32) / 255.0
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
# 获取label
label0 = tf.cast(features[‘label0’], tf.int32)
label1 = tf.cast(features[‘label1’], tf.int32)
label2 = tf.cast(features[‘label2’], tf.int32)
label3 = tf.cast(features[‘label3’], tf.int32)
return image, image_raw, label0, label1, label2, label3
4、获取图片数据和标签
image, image_raw, label0, label1, label2, label3 =
read_and_decode(TFRECORD_FILE)
5、使用shuffle_batch可以随机打乱
image_batch, image_raw_batch, label_batch0, label_batch1,
label_batch2, label_batch3 = tf.train.shuffle_batch(
[image, image_raw, label0, label1, label2, label3], batch_size = BATCH_SIZE,
capacity = 50000, min_after_dequeue=10000, num_threads=1)
6、定义网络结构
train_network_fn = nets_factory.get_network_fn(
‘alexnet_v2’,
num_classes=CHAR_SET_LEN,
weight_decay=0.0005,
is_training=False)
7、创建会话
with tf.Session() as sess:
# inputs: a tensor of size [batch_size, height, width, channels通道数]
X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])
# 数据输入网络得到输出值
logits0,logits1,logits2,logits3,end_points = train_network_fn(X)
# 预测值
predict0 = tf.reshape(logits0, [-1, CHAR_SET_LEN])
predict0 = tf.argmax(predict0, 1)
predict1 = tf.reshape(logits1, [-1, CHAR_SET_LEN])
predict1 = tf.argmax(predict1, 1)
predict2 = tf.reshape(logits2, [-1, CHAR_SET_LEN])
predict2 = tf.argmax(predict2, 1)
predict3 = tf.reshape(logits3, [-1, CHAR_SET_LEN])
predict3 = tf.argmax(predict3, 1)
# 初始化
sess.run(tf.global_variables_initializer())
# 载入训练好的模型
saver = tf.train.Saver()
saver.restore(sess,‘D:/pycharm/project/text7验证码识别/models/crack_captcha.model-100’)
# 创建一个协调器,管理线程
coord = tf.train.Coordinator()
# 启动QueueRunner, 此时文件名队列已经进队
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(10):
# 获取一个批次的数据和标签
b_image, b_image_raw, b_label0, b_label1 ,b_label2 ,b_label3 = sess.run([image_batch,
image_raw_batch,
label_batch0,
label_batch1,
label_batch2,
label_batch3])
# 显示图片
#img=Image.fromarray(b_image_raw[0],‘L’)
#plt.imshow(img)
#plt.axis(‘off’)
#plt.show()
# 打印标签
print(‘label:’,b_label0, b_label1 ,b_label2 ,b_label3)
# 预测
label0,label1,label2,label3 = sess.run([predict0,predict1,predict2,predict3], feed_dict={x:
b_image})
# 打印预测值
print(‘predict:’,label0,label1,label2,label3)
# 通知其他线程关闭
coord.request_stop()
# 其他所有线程关闭之后,这一函数才能返回
coord.join(threads)
最后下面介绍一下alexnet网络结构
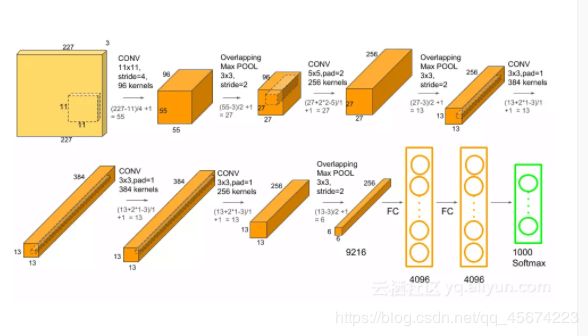
未经处理的图片是RGB格式16060的图片,经过灰度化处理后图片变成黑白一维224224图片。网络有5层卷积3层池化、3层全连接