从0到1走进 Kaggle
作者:CSDN优秀博主 专栏作家 「不会停的蜗牛」
目录:
- kaggle 是什么?
- 如何参赛?
- 解决问题一般步骤?
- 进一步:
- 如何探索数据?
- 如何构造特征?
- 提交结果
kaggle 是什么?
Kaggle 是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决。
https://www.kaggle.com/
点击导航栏的 competitions 可以看到有很多比赛,其中正式比赛,一般会有奖金或者工作机会,除了正式比赛还有一些为初学者提供的 playground,在这里可以先了解这个比赛,练习能力,再去参加正式比赛。
https://www.kaggle.com/competitions
如何参赛?
以 playground 中的这个 House Prices 预测为例,
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
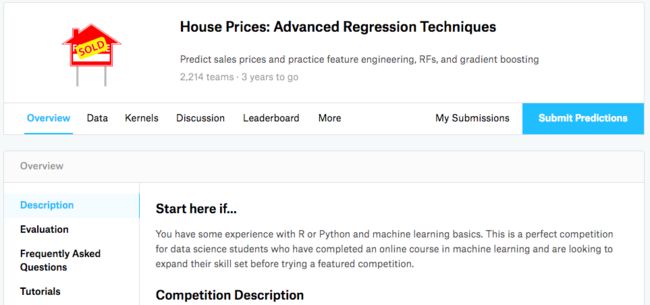
Overview: 首先在 overview 中仔细阅读问题的描述,这个比赛是让我们预测房价,它会给我们 79 个影响房价的变量,我们可以通过应用 random forest,gradient boosting 等算法,来对房价进行预测。
Data:在这里给我们提供了 train 数据集,用来训练模型;test 数据集,用来将训练好的模型应用到这上面,进行预测,这个结果也是要提交到系统进行评价的;sample_submission 就是我们最后提交的 csv 文件中,里面的列的格式需要和这里一样。
Kernels:可以看到一些参赛者分享的代码。
Discussion:参赛者们可以在这里提问,分享经验。
Leaderboard:就是参赛者的排行榜。
参加 kaggle 最简单的流程就是:
- 第一步:在 Data 里面下载三个数据集,最基本的就是上面提到的三个文件,有些比赛会有附加的数据描述文件等。
- 第二步:自己在线下分析,建模,调参,把用 test 数据集预测好的结果,按照 sample_submission 的格式输出到 csv 文件中。
- 第三步:点击蓝色按钮 ’Submit Predictions’ ,把 csv 文件拖拽进去,然后系统就会加载并检验结果,稍等片刻后就会在 Leaderboard 上显示当前结果所在的排名位置。
上传过一次结果之后,就直接加入了这场比赛。正式比赛中每个团队每天有 5 次的上传机会,然后就要等 24 小时再次传结果,playground 的是 9 次。
解决问题一般步骤?
应用算法解决 Kaggle 问题,一般会有以下几个步骤:
- 识别问题
- 探索数据
- 数据预处理
- 将 train.csv 分成 train 和 valid 数据
- 构造新的重要特征数据
- 应用算法模型
- 优化模型
- 选择提取重要特征
- 再次选择模型,进行训练
- 调参
- 重复上述过程,进一步调优
- 预测
当然上面是相对细的分步,如果简化的话,是这么几大步:
- 探索数据
- 特征工程
- 建立模型
- 调参
- 预测提交
之前写过一篇文章,《一个框架解决几乎所有机器学习问题》
http://blog.csdn.net/aliceyangxi1987/article/details/71079448
里面的重点是介绍了常用算法模型一般需要调节什么参数,即第四步。
还有这篇,《通过一个kaggle实例学习解决机器学习问题》
http://blog.csdn.net/aliceyangxi1987/article/details/71079473
主要介绍了第三步建立模型的部分,包括 ensemble 的例子。
今天这篇文章算是一个补充,在观察数据和特征构造上学习几种常用的方式。
如何探索数据?
以 House prices 为例,探索数据常用方法有以下 6 步。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
1. 首先,在 data_description.txt 这里有对 79 个变量含义非常详细的描述
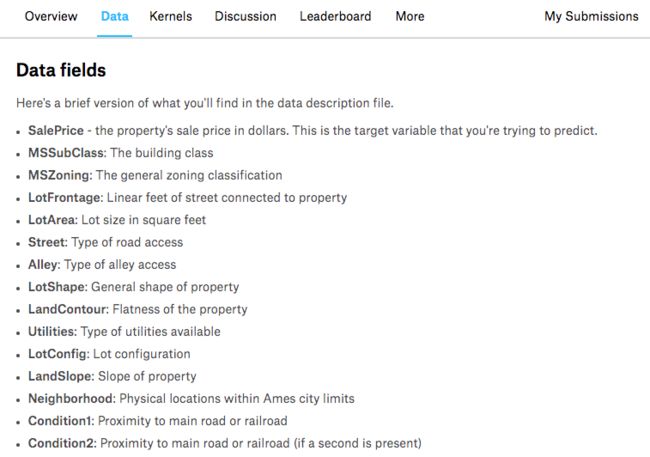
我们可以先通过阅读变量含义,根据常识猜测一下,哪些变量会对预测结果有比较重要的影响。
例如:
OverallQual: Overall material and finish quality 物料和质量应该是很重要的组成。
GrLivArea: Above grade (ground) living area square feet 面积也是明显的因素。
YearBuilt: Original construction date 时间也有影响。
2. 接着,对要预测的目标数据 y 有一个宏观的把握,这里是输出 summary,也可以用 boxplot,histogram 等形式观察
df_train['SalePrice'].describe()
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64count 就是有多少行观察记录,另外注意一下 min 并未有小于 0 的这样的不合理的数值。
3. 通过 Correlation matrix 观察哪些变量会和预测目标关系比较大,哪些变量之间会有较强的关联
#correlation matrix
corrmat = df_train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);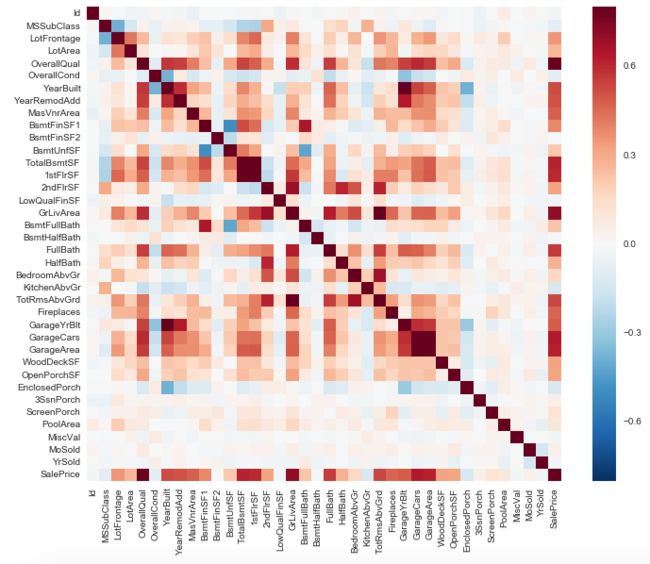
我们可以看上图的最右边一列(也可以是下面最后一行),颜色由深到浅查看,可以发现 OverallQual 和 GrLivArea 的确是对目标影响较大的因素,另外观察中间区域的几个深色块,例如 ‘TotalBsmtSF’ 和 ‘1stFlrSF’ 二者关系较强,回看它们的定义,它们所包含的信息差不多所以才有显示出强关联:
TotalBsmtSF: Total square feet of basement area
1stFlrSF: First Floor square feet
那这种时候,我们可以只取其中一个特征。
或者我们可以把与目标 ‘SalePrice’ 最紧密关联的 10 个变量的关联度打印出来:
#saleprice correlation matrix
k = 10 #number of variables for heatmap
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()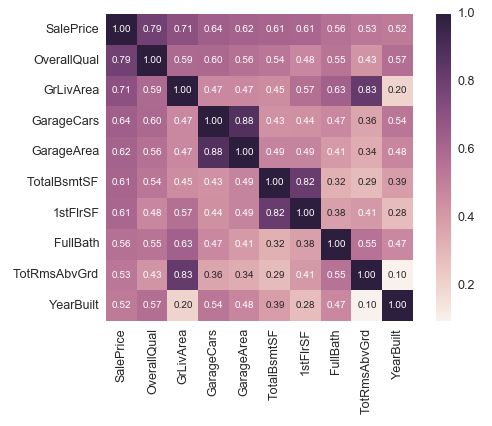
通过这些数值,我们再一一观察变量含义,判断一下是否可以把其中某些变量删除。
4. 接下来看 missing value
#missing data
total = df_train.isnull().sum().sort_values(ascending=False)
percent = (df_train.isnull().sum()/df_train.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head(20)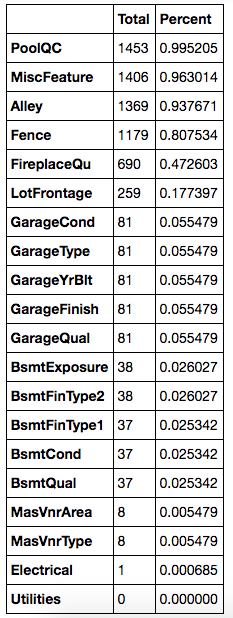
先把每个变量的 NaN 记录个数求和算出来,再把所占的比例计算一下,对于占比例太大的变量,例如超过了 15%,就看看它的含义,如果不是很重要,这种数据是可以删掉的,对于剩下的,再一个一个查看变量的含义,及比例,判断是否可以删掉,最后一个变量只有一条是 missing 的,那么就可以只删掉这一个记录。
此外,我们还可以通过补充 missing 的值,通过实际变量的含义进行补充,例如类别型变量,就可以补充成 No,数值型变量可以补充成 0,或者用平均值来填充。
#dealing with missing data
df_train = df_train.drop((missing_data[missing_data['Total'] > 1]).index,1)
df_train = df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index)5. 下面是看 outliers
我们可以先来看主要的几个变量的 outliers
#bivariate analysis saleprice/grlivarea
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));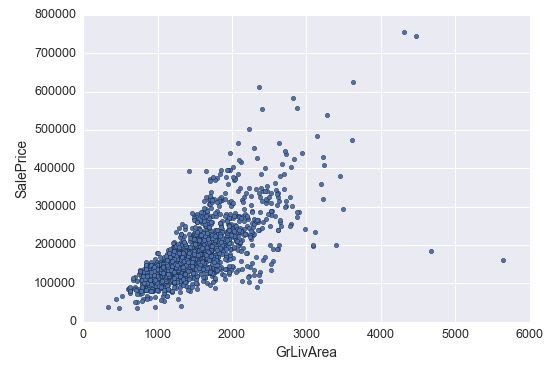
例如 ‘GrLivArea’ 这个变量,它的右下角这几个点离主体就比较远,可以猜测一下产生这样数据的原因,但因为不能代表主体的,所以此时先删掉:
#deleting points
df_train.sort_values(by = 'GrLivArea', ascending = False)[:2]
df_train = df_train.drop(df_train[df_train['Id'] == 1299].index)
df_train = df_train.drop(df_train[df_train['Id'] == 524].index)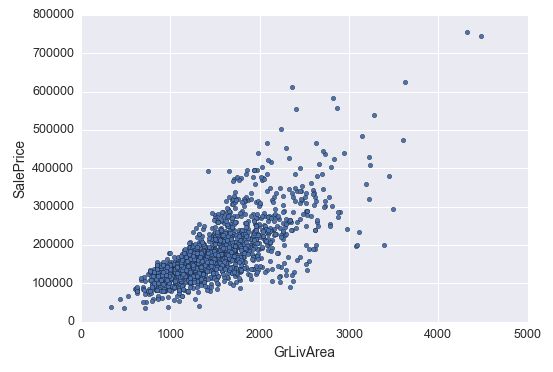
6. 很重要的一步是把不符合正态分布的变量给转化成正态分布的
因为一些统计检验方法需要数据满足正态分布的条件。
#histogram and normal probability plot
sns.distplot(df_train['SalePrice'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['SalePrice'], plot=plt)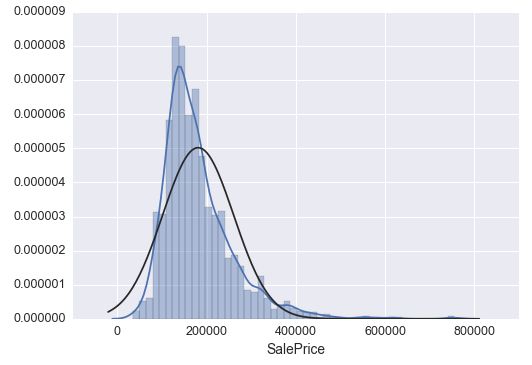
这个图里可以看到 ‘SalePrice’ 的分布是正偏度,在正偏度的情况下,用 log 取对数后可以做到转换:
#applying log transformation
df_train['SalePrice'] = np.log(df_train['SalePrice'])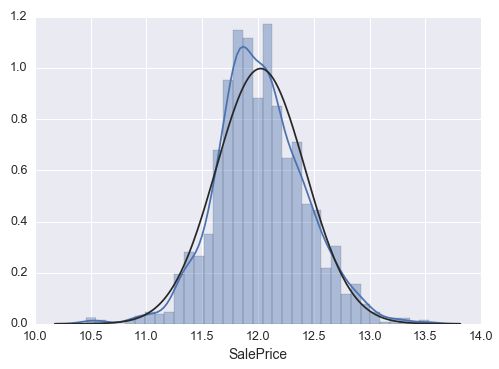
同样,我们可以把其他不符合正态分布的变量进行转化,例如 GrLivArea 和 目标值 SalePrice 在转化之前的关系图是类似锥形的:
#scatter plot
plt.scatter(df_train['GrLivArea'], df_train['SalePrice']);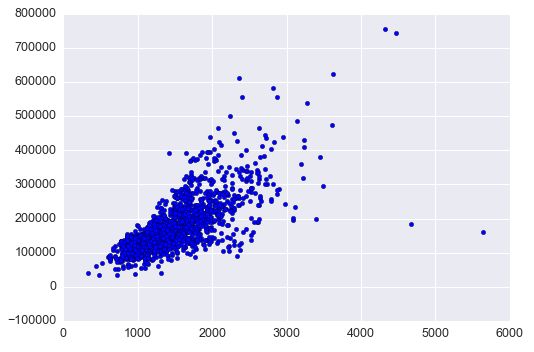
在对 GrLivArea 转换后,
#data transformation
df_train['GrLivArea'] = np.log(df_train['GrLivArea'])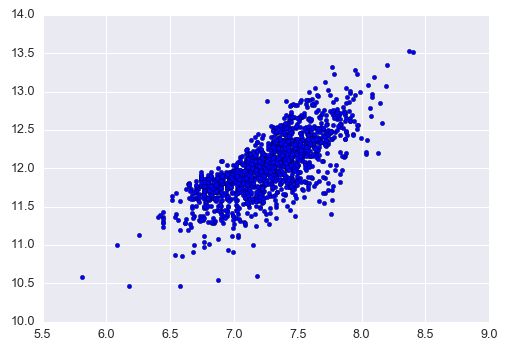
如何构造特征?
通过上面的步骤,我们大概可以筛选出一些重要的特征,除了数据集给定的变量之外,我们也可以自己建立一些新的特征。
1. 数值变类别型
例如,MoSold: Month Sold 这个变量看起来是数值型的,但其实更符合类别型的,所以要做一下转换:
"MoSold" : {1 : "Jan", 2 : "Feb", 3 : "Mar", 4 : "Apr", 5 : "May", 6 : "Jun", 7 : "Jul", 8 : "Aug", 9 : "Sep", 10 : "Oct", 11 : "Nov", 12 : "Dec"}2. 类别型加顺序
例如,Functional: Home functionality rating 这个变量,它是个 rating,那么这种数值应该是有序的,并且这种顺序是带有信息的,那我们就给转化成数字:
"Functional" : {"Sal" : 1, "Sev" : 2, "Maj2" : 3, "Maj1" : 4, "Mod": 5, "Min2" : 6, "Min1" : 7, "Typ" : 8}3. 简化类别
当然类别太多了的不好,可以进一步简化成两三个等级:
train["SimplFunctional"] = train.Functional.replace(
{1 : 1, 2 : 1, # bad
3 : 2, 4 : 2, # major
5 : 3, 6 : 3, 7 : 3, # minor
8 : 4 # typical})4. 构造多项式
另外一种常用的方式是构造多项式,一般是 2次项,3次项,开平方:
train["OverallQual-s2"] = train["OverallQual"] ** 2
train["OverallQual-s3"] = train["OverallQual"] ** 3
train["OverallQual-Sq"] = np.sqrt(train["OverallQual"])5. 加减乘除
还有通过加减乘除的数学关系构造:
OverallQual: Overall material and finish quality
OverallCond: Overall condition rating
train["OverallGrade"] = train["OverallQual"] * train["OverallCond"]6. 变为 one-hot
然后我们来把 categorical 的变量给变成 one-hot 的形式:
#convert categorical variable into dummy
df_train = pd.get_dummies(df_train)提交结果
接下来用一个最简单的线性规划,来展示一下运行步骤,
1. 引入常用包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline2. 导入数据
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
print ("Train data shape:", train.shape)
print ("Test data shape:", test.shape)
#('Train data shape:', (1460, 81))
#('Test data shape:', (1459, 80))3. 取 log 转化为正态,看 correlation,处理 outliers,missing value
此处可以对 train 数据集应用数据探索的几种方法。
#取 log 转化为正态
target = np.log(train.SalePrice)
#看 correlation
numeric_features = train.select_dtypes(include=[np.number])
numeric_features.dtypes
corr = numeric_features.corr()
print (corr['SalePrice'].sort_values(ascending=False)[:5], '\n')
print (corr['SalePrice'].sort_values(ascending=False)[-5:])
#处理 outliers
train = train[train['GarageArea'] < 1200]
#处理 missing value
data = train.select_dtypes(include=[np.number]).interpolate().dropna() 4. 转化为 one-hot 向量
这里可以用构造特征的几种方法。
train['enc_street'] = pd.get_dummies(train.Street, drop_first=True)
test['enc_street'] = pd.get_dummies(train.Street, drop_first=True)5. 模型训练,预测
用 train_test_split 将 train 数据集分为 train 和 valid 数据,
只用一个简单的 linear_model 来拟合,用 mean_squared_error 得到误差值。
y = np.log(train.SalePrice)
X = data.drop(['SalePrice', 'Id'], axis=1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=42, test_size=.33)
from sklearn import linear_model
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)
predictions = model.predict(X_test)
from sklearn.metrics import mean_squared_error
print ('RMSE is: \n', mean_squared_error(y_test, predictions))对 test.csv 应用刚才的模型进行预测,因为前面对 test 数据取了 log,这里要用 exp 变为原来的范围。
feats = test.select_dtypes(
include=[np.number]).drop(['Id'], axis=1).interpolate()
predictions = model.predict(feats)
final_predictions = np.exp(predictions)6. 提交结果
构造一个 submission 格式的 csv,将 final_predictions 作为预测值列输入进去,
输出这个 csv 后,就可以在比赛主页上的 submit 蓝色按钮上点击提交。
submission = pd.DataFrame()
submission['Id'] = test.Id
submission['SalePrice'] = final_predictions
submission.to_csv('output.csv', index=False)
#Your submission scored 0.13878初级的结果出来了,大概在50%的排位,之后可以尝试其他算法:
例如 Random Forest Regressors , Gradient Boosting,ensembling models 等,以及过拟合的分析,配合特征工程等。
这篇文章里面的代码例子,并不会带你进入前几位,只是介绍一个完整的过程,常用的方法和代码实现,至于如何让算法发挥高效作用,就看玩家怎么挖掘特征,怎么组合算法和特征,怎么调参了,因为这也是最有趣的环节,以一个轻松的方式入门,再以一个提升的心态不断进步。
参考:
https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python
https://www.kaggle.com/juliencs/a-study-on-regression-applied-to-the-ames-dataset