FastAI 课程学习笔记 lesson 1:宠物图片分类
文章目录
- 代码解析
- 神奇的"%"
- 导入fastAI 库
- 下载解压数据集 untar_data
- 获取帮助文档
- help()
- ?
- ??
- doc
- 设置路径
- get_image_files
- ImageDataBunch
- from_name_re
- grep命令检验正则表达式
- python re检验正则表达式
- from_name_re使用方法
- data.normalize()来进行数据归一化
- data.show_batch()显示图像
- 查看标签
- 训练
- 利用resnet框架训练模型
- 应用one-cycle-policy
- 保存模型权重
- 分析结果
- 绘制出loss最大的案例
- 混淆矩阵
- 通过微调让模型更加好
- Unfreezing
- fine-tuning
- learning rates
- 参考
代码解析
神奇的"%"
%reload_ext autoreload
%autoreload 2
%matplotlib inline
这些东西开始%是对jupyter notebook本身的特殊指令,它们不是Python代码。它们被称为“魔法”。
表示
- 如果有人在我运行这个程序时更改了底层库代码,请自动重新加载它
- 如果有人想画点什么,请在这个
jupyter notebook上画出来
导入fastAI 库
from fastai import *
from fastai.vision import *
fastai的官方文档见这里:http://docs.fast.ai/
在大多数库的标准生产代码中,有很好的理由不使用import *。
在jupyter notebook中,你希望能够快速交互地尝试一些东西,而不是不断地回到顶部,导入更多的东西。您希望能够使用大量完整的选项卡,并且非常具有实验性,因此import *非常棒。
当您在生产中构建东西时,您可以进行正常的PEP8风格的适当软件工程实践。这是一种不同的编码风格。并不是说在数据科学编程中没有规则,规则是不同的。
当你在训练模型时,最重要的是能够快速地进行交互实验。所以你会看到我们使用了很多不同的过程,风格,和你习惯的东西。但它们的存在是有原因的,随着时间的推移,你会了解它们。
另一件需要提到的事情是,fastai库是以一种非常有趣的模块化方式设计的,而且当您使用import *时,事情比您预期的要少得多。所有这些都是显式设计的,目的是让您能够快速地导入并使用它们,而不会出现任何问题。
下载解压数据集 untar_data
数据集在深度学习中发挥着重要的作用,在fastai中,通过untar_data函数来下载和解压我们所需要的数据集。比如我们需要下载fastai指定的宠物数据集,我们可以采用如下的代码来完成工作:
path = untar_data(URLs.PETS); path
获取帮助文档
在有的时候我们可能会因为某些fastai的某些函数或者其他用法困扰,我们可以通过下面几种方法来获取帮助文档
help()
通过使用下面的代码可以获取untar_data的使用说明
help(untar_data)
获取结果如下:
Help on function untar_data in module fastai.datasets:
untar_data(url:str, fname:Union[pathlib.Path, str]=None, dest:Union[pathlib.Path, str]=None)
Download `url` if doesn't exist to `fname` and un-tgz to folder `dest`
?
也可以使用如下?来获取该函数的定义和参数。这种方法可用于任何python库,使用方法如下代码所示:
?untar_data
获取结果如下:
Signature: untar_data(url:str, fname:Union[pathlib.Path, str]=None, dest:Union[pathlib.Path, str]=None, data=True, force_download=False) -> pathlib.Path
Docstring: Download `url` to `fname` if it doesn't exist, and un-tgz to folder `dest`.
File: /usr/local/lib/python3.6/dist-packages/fastai/datasets.py
Type: function
??
通过??可以获取相关函数的源程序,这种方法可用于任何python库,使用方法如下代码所示:
??untar_data
获取结果如下:
Signature: untar_data(url:str, fname:Union[pathlib.Path, str]=None, dest:Union[pathlib.Path, str]=None, data=True, force_download=False) -> pathlib.Path
Source:
def untar_data(url:str, fname:PathOrStr=None, dest:PathOrStr=None, data=True, force_download=False) -> Path:
"Download `url` to `fname` if it doesn't exist, and un-tgz to folder `dest`."
dest = url2path(url, data) if dest is None else Path(dest)/url2name(url)
fname = Path(ifnone(fname, _url2tgz(url, data)))
if force_download or (fname.exists() and url in _checks and _check_file(fname) != _checks[url]):
print(f"A new version of the {'dataset' if data else 'model'} is available.")
if fname.exists(): os.remove(fname)
if dest.exists(): shutil.rmtree(dest)
if not dest.exists():
fname = download_data(url, fname=fname, data=data)
if url in _checks:
assert _check_file(fname) == _checks[url], f"Downloaded file {fname} does not match checksum expected! Remove that file from {Config().data_archive_path()} and try your code again."
tarfile.open(fname, 'r:gz').extractall(dest.parent)
return dest
File: /usr/local/lib/python3.6/dist-packages/fastai/datasets.py
Type: function
doc
通过使用doc,这种方法只适用于fastai,显示函数的定义、docstring和指向文档的链接(仅适用于导入fastai库),使用方法如下:
doc(untar_data)
但是需要注意的是,在使用doc()可能会遇到一些问题,会报如下的错误:
markdown2html() missing 1 required positional argument: 'source'
这个bug,fastai官方已经修复了,详细可参考这里
设置路径
在我们通过如下代码下载解压数据集之后,我们可以得到数据集所在的路径path
path = untar_data(URLs.PETS)
我们可以使用path.ls()来查看数据集的根目录都有哪些目录。
当我们查看到根目录的结果如下:
['annotations', 'images']
我们可以为这些目录设置路径的变量,如下代码所示:
path_anno = path/'annotations'
path_img = path/'images'
这种路径拼接方式是源于fastai集成了python中的pathlib的相关功能,关于pathlib更多内容可以查看这里
get_image_files
在fastai中,通过get_image_files能将图像文件的路径存储到列表之中
fnames = get_image_files(path_img)
fnames[:5]
结果如下:
[PosixPath('/data1/jhoward/git/course-v3/nbs/dl1/data/oxford-iiit-pet/images/american_bulldog_146.jpg'),
PosixPath('/data1/jhoward/git/course-v3/nbs/dl1/data/oxford-iiit-pet/images/german_shorthaired_137.jpg'),
PosixPath('/data1/jhoward/git/course-v3/nbs/dl1/data/oxford-iiit-pet/images/japanese_chin_139.jpg'),
PosixPath('/data1/jhoward/git/course-v3/nbs/dl1/data/oxford-iiit-pet/images/great_pyrenees_121.jpg'),
PosixPath('/data1/jhoward/git/course-v3/nbs/dl1/data/oxford-iiit-pet/images/Bombay_151.jpg')]
这是计算机视觉数据集传递的一种非常常见的方式——只有一个文件夹,里面有一大堆文件。有趣的是我们如何得到标签。在机器学习中,标签指的是我们试图预测的东西。如果我们仔细观察一下,我们可以马上看到标签实际上是文件名的一部分。我们需要以某种方式获得每个文件名的标签位列表,这将给我们标签。进行深度学习主要依赖于两个部分:
- 数据
- 标签
ImageDataBunch
在fastai中通过ImageDataBunch对象可以轻松实现图像数据训练的问题。ImageDataBunch表示构建模型所需的所有数据,还有一些工厂方法可以很容易地创建这些数据——训练集、带有图像和标签的验证集。
from_name_re
在这一节中,通过使用ImageDataBunch的from_name_re函数通过正则表达式的方式来从图像名称中提取标签——label。
通过下面的正则表达式来对图像名称进行字符串匹配:
pat = r'/([^/]+)_\d+.jpg$'
我们来对这个正则表达式进行解析下:
| 正则表达式 | 解释 |
|---|---|
| $ | 匹配字符串结尾 |
| .jpg | 表示字符串最后的的字符,这里表示文件的格式 |
| \d | 匹配数字,+表示匹配前一个字符1次或者无限次 |
| _ | 应该数字开始前的下划线 |
| () | 表示一组字符 |
| [] | 表示字符集 |
| ^/ | ^在中括号中表示取反,^/表示除了/的所有字符 |
| ( [ ^/ ] + ) | 表示除了/的任意字符串 |
| / | 表示最开始的/ |
| r | 表明字符串为原始字符串,否则\d就需要写成\\d,否则python无法解析 |
加入现在我们的图像所在路径如下所示:
/data/oxford-iiit-pet/images/german_shorthaired_105.jpg
/data/oxford-iiit-pet/images/Siamese_86.jpg
/data/oxford-iiit-pet/images/British_Shorthair_56.jpg
.....
通过正则表达式‘/([^/]+)_\d+.jpg$来过滤上述的这些路径,我们最终会得到如下结果:
/german_shorthaired_105.jpg
/Siamese_86.jpg
/British_Shorthair_56.jpg
.....
grep命令检验正则表达式
我们可以通过linux的grep命令来检验这个正则表达式是否正确,假设当前我们处于/data/oxford-iiit-pet/路径下,我们可以如下命令来检验
ls | xargs readlink -f | grep -P "/([^/]+)_\d+.jpg$"
或者
ls | xargs readlink -f | grep -E "/([^/]+)_[0-9]+.jpg$"
其中ls | xargs readlink -f是为了获取图像文件的绝对路径。
关于grep -E 和 grep -P的使用区别主要在于:
grep -E使用的是扩展的正则表达式,不支持\dgrep -P使用的是Perl 的正则表达式,支持\d
关于它们的更多区别可以查看这里
python re检验正则表达式
可以通过如下的程序来检验正则表达式的作用
import re
temp_name = "/data/oxford-iiit-pet/images/german_shorthaired_105.jpg"
pat = r'/([^/]+)_\d+.jpg$'
pat = re.compile(pat)
print(pat.search(temp_name).group())
print(pat.search(temp_name).group(1))
得到的结果如下:
/german_shorthaired_105.jpg
german_shorthaired
其中,通过pat.search(temp_name).group(1)获取到图像的标签,这个通过正则表达式中的()定义分组实现。关于正则表达式的更多知识和正则表达式在python中的使用,可以参考这里。
from_name_re使用方法
from_name_re使用方法如下:
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224)
其中的参数解释如下:
| 参数 | 解释 |
|---|---|
| path_img | 含有图图像的文件夹路径 |
| fnames | 具体图像文件的路径 |
| pat | 用来提取标签的正则表达式 |
| ds_tfm | 将变换应用到图像上 |
| size | 统一设置训练的图像的大小 |
其中利用size统一设置训练的图像的大小的原因是因为这是当前深度学习技术的一个缺点,即GPU必须将完全相同的指令同时应用到一大堆东西上,以达到更快的速度。如果图像的形状和大小不同,就不能这样做,所以必须让所有的图像都具有相同的形状和大小。当前使用的形状以方形为主,当然还有一些矩形的情况。
之所以将size设置成224,一个重要的原因是因为很多经典的模型都使用size=224,通常使用这个尺寸可以解决大部分的问题。
其中get_transforms()将所有图像的size调整成224,当然get_transforms()函数可以快速的得到图像的多种变换结果,因此get_transforms()函数也经常被用在数据增强上。
什么是数据增强?
数据增强也许是在训练模型计算机视觉最重要的正则化技术,在训练模型时候不是每次都使用相同的图片,而是做一些小随机变换(旋转,缩放、翻译等…),不改变里面有什么图像(肉眼),但改变其像素值。经过数据增强训练的模型将更好地泛化。
关于在fastai中如何实现数据增强和图像变换的知识可以查看这里
ImageDataBunch.from_name_re将返回DataBunch对象。在fastai中,所有的模型对象都是DataBunch对象,DataBunch对象包含2或3个数据集——它包含您的训练数据集、验证数据集和可选的测试数集。对于每一个数据集,它包含你的图像和标签,你的文本和标签,或者你的表格数据和标签,等等。
data.normalize()来进行数据归一化
通过使用如下代码来进行,其中参数imagenet_stats是fastai通过使用在ImageNet上得到的预训练模型,然后将预训练模型的标准化必须应用于新数据(pets)。
data.normalize(imagenet_stats)
如果在训练模型时遇到问题,需要验证的一件事是是否正确地数据归一化。
对数据归一化的意义何在?
图像的像素值范围从0到255像素值,通常包含3个颜色通道(红、绿、蓝)。并且含有有些通道可能非常亮,有些可能一点也不亮,有些可能变化很大,有些可能一点也不亮。如果这些红绿蓝通道的均值都是0,标准差都是1,这将有助于训练一个深度学习模型。如果您的数据没有规范化,那么您的模型将很难很好地训练。所以,如果你在训练一个模型时遇到问题,那首先需要验证就是是否对数据进行了归一化。
data.show_batch()显示图像
查看数据并检查是否一切正常是非常重要的。
有时图像上可能有文本,或者它们可能被其他对象遮挡,或者它们中的一些可能以奇怪的方式旋转。
通过如下代码来查看图像数据:
data.show_batch(rows=3, figsize=(7,6))
显示情况如下:
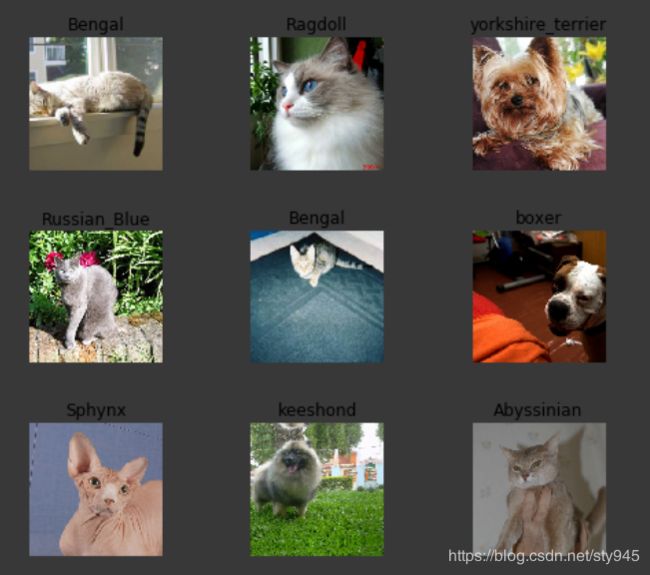
这些图像均以一种相当好的方式展示出来,它们大小显示一致,并且是默认情况下的中心裁剪也就是说它会对齐中间的位置并调整大小。
查看标签
我们要做的另一件事是看标签。所有可能的标签名都称为classes,可以通过data.classes来进行输出:
print(data.classes)
len(data.classes),data.c
得到这样的结果:
['american_bulldog', 'german_shorthaired', 'japanese_chin', 'great_pyrenees', 'Bombay', 'Bengal', 'keeshond', 'shiba_inu', 'Sphynx', 'boxer', 'english_cocker_spaniel', 'american_pit_bull_terrier', 'Birman', 'basset_hound', 'British_Shorthair', 'leonberger', 'Abyssinian', 'wheaten_terrier', 'scottish_terrier', 'Maine_Coon', 'saint_bernard', 'newfoundland', 'yorkshire_terrier', 'Persian', 'havanese', 'pug', 'miniature_pinscher', 'Russian_Blue', 'staffordshire_bull_terrier', 'beagle', 'Siamese', 'samoyed', 'chihuahua', 'Egyptian_Mau', 'Ragdoll', 'pomeranian', 'english_setter']
(37, 37)
这就是我们从文件名中使用正则表达式提取到的所有可能的标签。我们之前在之前学习过,有37种可能的类别,所以仅检查len(data.classes),它确实是37。DataBunch总是有一个名为c的属性。我们将在稍后讨论技术细节,但现在可以把它看作类的数量。对于像回归问题和多标签分类这样的问题,这并不完全准确,但现在就可以了。重要的是要知道data.c是一个非常重要的信息片段。
训练
利用resnet框架训练模型
现在我们已经可以开始训练一个模型了,在fastai中我们可以通过一个称为learner的东西来进行训练模型。
- DataBunch:是数据在
fastai中的一般概念,从这里开始,有一些它的子类用于特定的应用程序,比如ImageDataBunch - Learner: 一个通过学习相关内容来训练模型的一般概念。在此基础上,有各种子类来简化操作,特别是有一个
convnet learner(它可以为您创建卷积神经网络)。
learn = create_cnn(data, models.resnet34, metrics=error_rate)
create_cnn方法存在于fastai.vision.learner类中。
在fastai中,模型是由学习者训练的,create_cnn只接受很少的参数,首先是DataBunch数据对象,然后是模型resnet34,最后传递的是指标列表。
当首次调用时候会下载resnet34的预训练模型,预训练是指这个特定的模型已经为特定的任务进行了训练,当前这个预训练模型是使用Imagenet图像数据集进行训练得到的。所以我们不一定要从一个对图像一无所知的模型开始,而是从1000个类别的图像开始。
应用one-cycle-policy
简单来说,one-cycle-policy, 使用的是一种周期性学习率,从较小的学习率开始学习,缓慢提高至较高的学习率,然后再慢慢下降,周而复始,每个周期的长度略微缩短,在训练的最后部分,学习率比之前的最小值降得更低。这不仅可以加速训练,还有助于防止模型落入损失平面的陡峭区域,使模型更倾向于寻找更平坦部分的极小值,从而缓解过拟合现象。
One-Cycle-Policy 大概有三个步骤:
-
我们逐渐将学习率从 lr_max / div_factor 提高到 lr_max,同时我们逐渐减少从 mom_max 到 mom_min 的动量 (momentum)。
-
反向再做一次:我们逐渐将学习率从 lr_max 降低到 lr_max / div_factor,同时我们逐渐增加从 mom_min 到 mom_max 的动量。
-
我们进一步将学习率从 lr_max / div_factor 降低到 lr_max /(div_factor x 100),我们保持动力稳定在 mom_max。
关于one-cycle-policy的知识可以参考这里(中文,英文)
在fastai中通过如下代码实现:
learn.fit_one_cycle(4)
原型是这样的:
fit_one_cycle(learn:Learner, cyc_len:int, max_lr:Union[float, Collection[float], slice]=slice(None, 0.003, None), moms:Point=(0.95, 0.85), div_factor:float=25.0, pct_start:float=0.3, final_div:float=None, wd:float=None, callbacks:Optional[Collection[Callback]]=None, tot_epochs:int=None, start_epoch:int=None)
它接受一个整数cycle_len,该整数描述你希望希望通过完整数据集的次数,每次模型看到图片,它就会变得越来越好,这要花很多时间。但是如果你把图像显示太多次,这个模型只会单独识别某些图像。在机器学习中,这被称为过度拟合。
max_lr是最大学习速率,mom是动量,wd是重量衰减我们将在以后的课程中学习所有这些参数。
保存模型权重
这一步非常重要,因为你需要在下次运行代码时重新加载权重
learn.save('stage-1')
分析结果
观察模型的运行结果十分重要,我们已经观察了如何训练模型,现在我们观察我们的模型预测出了什么?
interp = ClassificationInterpretation.from_learner(learn)
ClassificationInterpretationl类拥有用于创建混淆矩阵以及绘制分类错误的图像的方法。
切记传递学习对象,学习对象知道两件事,数据和模型。
这里的模型不仅是体系结构,而且是经过训练的带有权重的模型。
我们需要解释那个模型,我们传入ClassificationInterpretation对象的学习者
绘制出loss最大的案例
通过如下代码绘制
interp.plot_top_losses(9, figsize=(15,11))
后面将学习损失函数,但是损失函数告诉你,你的预测和实际情况相比有多好。具体来说,如果你非常有信心的预测了一类狗,你说它是哈士奇,但是实际上它是中华田园犬,你对错误的答案非常有信心,所以损失会很大,因此通过绘制最大损失,我们将绘制出对预测最自信但错误的图像。

所有的图片的题目包含4个信息,分别是:预测类型,真实类型,loss(损失),真实类型概率
混淆矩阵
interp.plot_confusion_matrix(figsize=(12, 12), dpi=60)
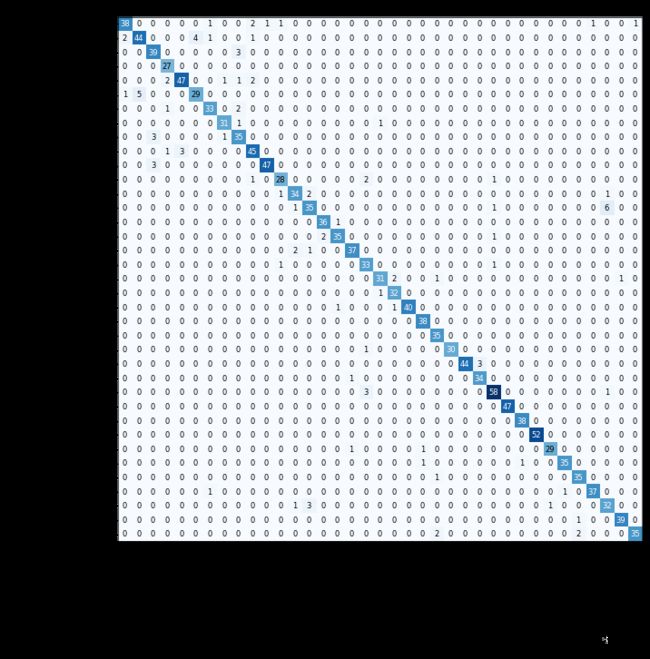
它显示了每一个实际类型的狗或猫,有多少时间模型预测的狗或猫。因为这一次非常准确,它显示了较暗的对角线,对于其他一些错误的组合使用了较亮的数字。如果你有很多类,不要使用混淆矩阵。相反,使用fastai的命名函数most_confused()。
interp.most_confused(min_val=2)
得到:
[('american_pit_bull_terrier', 'staffordshire_bull_terrier', 6),
('Egyptian_Mau', 'Bengal', 5),
('Bengal', 'Egyptian_Mau', 4),
('Birman', 'Ragdoll', 3),
('Ragdoll', 'Birman', 3),
('Russian_Blue', 'British_Shorthair', 3),
('Siamese', 'Birman', 3),
('keeshond', 'leonberger', 3),
('miniature_pinscher', 'chihuahua', 3),
('staffordshire_bull_terrier', 'american_pit_bull_terrier', 3),
('Abyssinian', 'Russian_Blue', 2),
('Bengal', 'Abyssinian', 2),
('British_Shorthair', 'Bombay', 2),
('British_Shorthair', 'Russian_Blue', 2),
('Maine_Coon', 'Ragdoll', 2),
('Sphynx', 'chihuahua', 2),
('american_bulldog', 'american_pit_bull_terrier', 2),
('beagle', 'basset_hound', 2),
('boxer', 'american_bulldog', 2),
('english_cocker_spaniel', 'english_setter', 2),
('yorkshire_terrier', 'havanese', 2),
('yorkshire_terrier', 'scottish_terrier', 2)]
通过微调让模型更加好
Unfreezing
到目前为止,我们已经拟合了4个epoch,而且运行得相当快。为什么会这样?因为我们用了一个小技巧——迁移学习
我们在架构的最后增加了少量额外的层,并且我们只训练那些层,我们保留了大部分早期的图层,这称为冻结层(freezing layers)
如果我们想构建一个模型,这和原始的再训练模型非常相似,在本例中与imageNet数据集非常相似
我们应该如何做?
返回并且重新训练模型,所以这就是为什么我们总是采用两级训练过程:
- 当我们在
create_cnn函数中调用fit或者fit_one_cycle,它会很好地调整这些额外的层在最后,并运行得非常快。 - 它基本上不会过拟合,但是为了得到更好的模型,我们还是调用为好
learn.unfreeze()
learn.fit_one_cycle(1)
unfreeze()表明解放所有的参数,重新训练整个模型,然后我们再一次调用fit_one_cycle(),但是我们得到的错误率非常糟糕,为什么会这样?
为了弄清楚这个问题需要理解卷积神经网络背后发生了什么。
图像有Red、Green、Blue三种颜色,数字范围从0到255。这些值在第一层进入简单的计算,然后它的输出进入第二层的计算,其结果进入第三层,以此类推。这些层可以达到神经网络的1000层。
-
第1层
我们可以把这些具体的系数/参数画成图来形象化。
可能会有几十个这样的过滤器,但是我们会看看随机的9个过滤器。
下面是9个实际系数或参数的例子

它们对相邻的一组像素进行操作。
第一行的第一列和第二列找出在任何方向上是否有一条对角线。
第三列显示它找到了从黄色到蓝色的梯度反之亦然,在这些方向上也有从粉色到绿色的梯度等等。
这是一个非常简单的卷积它可以找到一些小的直线。
这是Imagenet预训练卷积神经网络的第一层。 -
第2层
获取这些过滤器的结果并执行第2层计算
如果你看左下角最右边的图像,如果你看窗口的角,或者在第三列第二行图像中它发现了右边的曲线或者第二列第二行它学会了寻找小圆圈。
如果在图层1中我们可以找到一条直线,通过图层2我们可以找到形状。

如果你在实际的照片中看到这9张图片,它激活了这些过滤器。
这个过滤器/数学函数很擅长找到窗口角之类的。 -
第3层
可以找到线和形状的组合。
我们可以找到重复的二维物体或连接在一起的线的模式
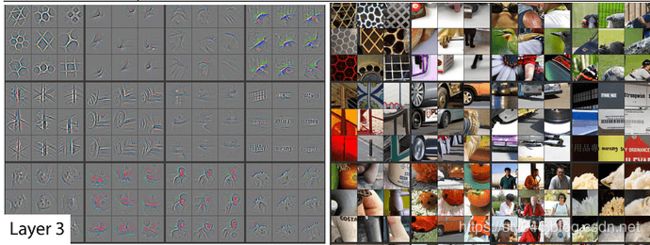
它在右下角找到了毛茸茸的东西的边缘。
还有左上角的几何图案。
此外,我们还可以看到下面重复粘贴的文本有时窗口也激活了这些过滤器。

-
第4层
从第三层中取出所有的东西,把它们组合在一起,发现了狗的脸或鸟的腿。

-
第5层
它可以发现鸟类/蜥蜴的眼球,或者特定品种的狗的脸。
到34层的时候,它就会学会准确地想象出一种带有细节的猫或狗。
这就是它的工作原理。
现在我们在微调(fine-tuning)我们说让我们改变所有这些。我们会让他们留在原地,但让我们看看是否能让他们变得更好。
所以,如果我们能把第1层的功能做得更好,这是非常不可能的。相对于最初训练的Imagenet数据,对于狗或猫的品种或任何类型的图像,对角线的定义不太可能发生变化。
但最后一层是第5层。我们想要在我们的数据集中改变狗的脸。
因此,直观地,你可以理解卷积神经网络的不同层代表不同层次的语义复杂性。
这就是为什么我们对这个网络进行微调的尝试没有像我们预期的那样奏效。
默认情况下,它以相同的速度训练所有层。所以它更新那些看起来像对角线或圆圈的东西就像它更新那些有特定的狗或猫品种的特定细节的东西一样。所以我们必须改变这一点。
要改变这一点,我们需要回到以前的状态。我们刚刚打破了这个模型。
