小瓜讲机器学习——分类算法(二)支持向量机(SVM)算法原理详解
2.支持向量机(SVM)算法原理
还以逻辑回归分类算法中图1.1的二分类问题为例,大家肯定发现了其实超平面存在很多个超平面,都能把十字点和⚪点分隔开,如下图。
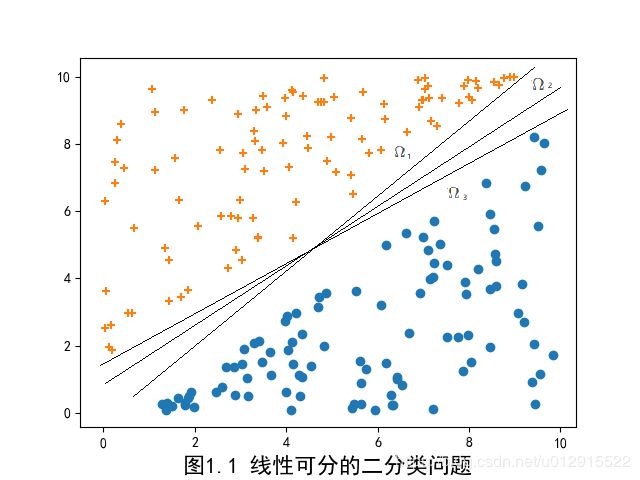
超平面 Ω 1 \Omega_1 Ω1、 Ω 2 \Omega_2 Ω2、 Ω 3 \Omega_3 Ω3…都能将图中的点分割开,那么 Ω 1 \Omega_1 Ω1、 Ω 2 \Omega_2 Ω2、 Ω 3 \Omega_3 Ω3…到底有啥不一样的呢?他们的分割的效果一样好吗?是不是存在一个分割效果最好的超平面呢?答案是肯定的,那就是支持向量机能够回答的。
2.1 感知机模型
对于上图中的二分类,我们定义十字点为正实例z=+1,⚪点为负实例z=-1,那么就是建立了某种映射,如下所示
{ 图 中 十 字 点 + ⚪ 点 } ⇒ Z = { + 1 − 1 \{图中十字点+⚪点\}\rArr Z=\begin{cases}+1\\ -1\end{cases} {图中十字点+⚪点}⇒Z={+1−1
那么如果存在一个可以分割的超平面 { Ω : ∑ ω i X i + b = 0 } \{\Omega:\sum\omega_iX_i+b=0\} {Ω:∑ωiXi+b=0},那么上述映射关系可以转化为映射函数 f ( x ) f(x) f(x)
z = f ( X i ) = s i g n ( ∑ ω i X i + b ) = { + 1 , 在 超 平 面 上 方 0 , 在 超 平 面 上 − 1 , 在 超 平 面 下 方 z=f(X_i)=sign(\sum\omega_iX_i+b)=\begin{cases}+1,&在超平面上方\\0,&在超平面上\\-1,&在超平面下方\end{cases} z=f(Xi)=sign(∑ωiXi+b)=⎩⎪⎨⎪⎧+1,0,−1,在超平面上方在超平面上在超平面下方
观察到对于每一个误分类,都有 − z ( i ) × ( ∑ ω i X i + b ) > 0 -z^{(i)}×(\sum\omega_iX_i+b)>0 −z(i)×(∑ωiXi+b)>0 (即异号),那么这个分割超平面应该使误分类的可能性最小,即
( ω i , b ) → min ( ω i , b ) J ( ω i , b ) = min ( ω i , b ) [ − ∑ i ∈ M z ( i ) × ( ∑ ω i X i + b ) ] (\omega_i,b)\to \min_ {(\omega_i,b)}J(\omega_i,b) = \min _ {(\omega_i,b)}[-\sum_{i\in M} z^{(i)}×(\sum\omega_iX_i+b)] (ωi,b)→(ωi,b)minJ(ωi,b)=(ωi,b)min[−i∈M∑z(i)×(∑ωiXi+b)]
其中M为误分类集合。
求解该极值问题,就能够确定一组 ( ω i , b ) (\omega_i,b) (ωi,b)。这种分类算法叫感知机算法。
2.2 函数间隔和几何间隔
函数间隔
对于给定的m个样本点 { ( X i ( 1 ) , z ( 1 ) ) , ( X i ( 2 ) , z ( 2 ) ) , . . . , ( X i ( m ) , z ( m ) ) } \{(X_i^{(1)},z^{(1)}),(X_i^{(2)},z^{(2)}),...,(X_i^{(m)},z^{(m)})\} {(Xi(1),z(1)),(Xi(2),z(2)),...,(Xi(m),z(m))},假设存在分割超平面 { Ω : ∑ ω i X i + b = 0 } \{\Omega:\sum\omega_iX_i+b=0\} {Ω:∑ωiXi+b=0},那么每一个样本点 ∑ ω i X i + b \sum\omega_iX_i+b ∑ωiXi+b 值不仅能够表明是在超平面上还是下(如果大于0,在上,小于0,在下),还能一定程度上表明距离超平面的远近,为了避免正负的麻烦,我们定义函数间隔为
γ ^ i = z ( k ) ( ∑ ω i X i ( k ) + b ) \hat \gamma_i = z^{(k)}(\sum\omega_iX_i^{(k)}+b) γ^i=z(k)(∑ωiXi(k)+b)
那么距离给定超平面最近的样本点就可以用最小函数间隔来等效。
γ ^ = min i = 1... m γ ^ i \hat \gamma = \min_{i=1...m} \hat \gamma_i γ^=i=1...mminγ^i
其实函数间隔可以写成如下形式
γ ^ i = z ( k ) [ ( ω 1 , . . . , ω n ) T ∙ ( X 1 ( k ) , . . . , X n ( k ) ) + b ] \hat \gamma_i = z^{(k)}[(\omega_1,...,\omega_n)^T\bullet(X_1^{(k)},...,X_n^{(k)})+b] γ^i=z(k)[(ω1,...,ωn)T∙(X1(k),...,Xn(k))+b]
( ω 1 , . . . , ω n ) T (\omega_1,...,\omega_n)^T (ω1,...,ωn)T是超平面 { Ω : ∑ ω i X i + b = 0 } \{\Omega:\sum\omega_iX_i+b=0\} {Ω:∑ωiXi+b=0}的法向量 N ⃗ \vec N N,显然 γ ^ i \hat \gamma_i γ^i就是特征向量 ( X 1 ( k ) , . . . , X n ( k ) ) (X_1^{(k)},...,X_n^{(k)}) (X1(k),...,Xn(k))在超平面法向的投影,但是由于法向量 N ⃗ \vec N N没有单位化(归一化),这样定义的函数间隔存在一个问题,如果 N ⃗ = ( ω 1 , . . . , ω n ) T \vec N=(\omega_1,...,\omega_n)^T N=(ω1,...,ωn)T等比变化,实际上超平面 { Ω : ∑ ω i X i + b = 0 } \{\Omega:\sum\omega_iX_i+b=0\} {Ω:∑ωiXi+b=0}是同一个,但是函数间隔却是变化的。
所以将法向量单位化(归一化),这样就定义了几何间隔。
几何间隔
定义几何间隔如下式
γ i = γ ^ i ∣ ∣ W ∣ ∣ = z ( k ) ( ∑ ω i X i ( k ) + b ) ∣ ∣ W ∣ ∣ \gamma_i= \frac{\hat \gamma_i}{||W||}= z^{(k)}\frac{(\sum\omega_iX_i^{(k)}+b)}{||W||} γi=∣∣W∣∣γ^i=z(k)∣∣W∣∣(∑ωiXi(k)+b)
相应的距离超平面最近的样本点与几何间隔最小等效。
γ = min i = 1... m γ i \gamma = \min_{i=1...m}\gamma_i γ=i=1...mminγi
其实不难发现,对于正确分类的样本点,几何间隔可以变换为
γ i = z ( k ) ( ∑ ω i X i ( k ) + b ) ∣ ∣ W ∣ ∣ = ∣ ∑ ω i X i ( k ) + b ∣ ∣ ∣ W ∣ ∣ \gamma_i= z^{(k)}\frac{(\sum\omega_iX_i^{(k)}+b)}{||W||}=\frac{|\sum\omega_iX_i^{(k)}+b|}{||W||} γi=z(k)∣∣W∣∣(∑ωiXi(k)+b)=∣∣W∣∣∣∑ωiXi(k)+b∣
学过解析几何的知识,不难发现这就是点到超平面的距离公式。
2.3 支持向量机模型
支持向量机模型就是找到一个超平面使得样本点到超平面的距离最大,也就是说对于m样本点来说,找一个超平面,使得最小几何间隔最大化(即m个样本点中离超平面最近的那个点到超平面的距离最大化)。
( ω i , b ) → max ( ω i , b ) γ = max ( ω i , b ) γ ^ ∣ ∣ W ∣ ∣ s . t . z ( k ) ( ∑ ω i X i ( k ) + b ) ≥ γ ^ \begin{aligned}&(\omega_i,b)\to \max_{(\omega_i,b)} \gamma=\max_{(\omega_i,b)} \frac{\hat \gamma}{||W||}\\ &\qquad\qquad s.t. \quad z^{(k)}(\sum\omega_iX_i^{(k)}+b)\ge\hat\gamma \end{aligned} (ωi,b)→(ωi,b)maxγ=(ωi,b)max∣∣W∣∣γ^s.t.z(k)(∑ωiXi(k)+b)≥γ^
实际上,超平面 { Ω : ∑ ω i X i + b = 0 } \{\Omega:\sum\omega_iX_i+b=0\} {Ω:∑ωiXi+b=0}与 { Ω : ∑ ω i X i + b γ ^ = 0 } \{\Omega:\frac{\sum\omega_iX_i+b}{\hat\gamma}=0\} {Ω:γ^∑ωiXi+b=0}是一样的,所以上述问题就等效为
( ω i , b ) → max ( ω i , b ) γ = max ( ω i , b ) 1 ∣ ∣ W ∣ ∣ s . t . z ( k ) ( ∑ ω i X i ( k ) + b ) ≥ 1 \begin{aligned}&(\omega_i,b)\to \max_{(\omega_i,b)} \gamma=\max_{(\omega_i,b)} \frac{1}{||W||}\\ &\qquad\qquad s.t. \quad z^{(k)}(\sum\omega_iX_i^{(k)}+b)\ge1 \end{aligned} (ωi,b)→(ωi,b)maxγ=(ωi,b)max∣∣W∣∣1s.t.z(k)(∑ωiXi(k)+b)≥1
我们不难推断 1 ∣ ∣ W ∣ ∣ \frac{1}{||W||} ∣∣W∣∣1达到最大值与 ∣ ∣ W ∣ ∣ 2 2 \frac{||W||^2}{2} 2∣∣W∣∣2达到最小值是等价的。所以最后问题等价与
( ω i , b ) → = min ( ω i , b ) ∣ ∣ W ∣ ∣ 2 2 s . t . z ( k ) ( ∑ ω i X i ( k ) + b ) ≥ 1 \begin{aligned}&(\omega_i,b)\to =\min_{(\omega_i,b)} \frac{||W||^2}{2}\\ &\qquad\qquad s.t. \quad z^{(k)}(\sum\omega_iX_i^{(k)}+b)\ge1 \end{aligned} (ωi,b)→=(ωi,b)min2∣∣W∣∣2s.t.z(k)(∑ωiXi(k)+b)≥1
这个就是线性可分的支持向量机模型。
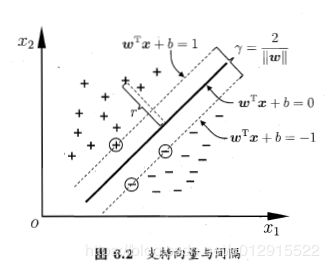
显然支持向量机模型找到的超平面一定是最靠近超平面的正实例样本点A和负实例样本点B到超平面具有相等的几何间距,并且样本点A和样本点B称为支持向量。
同时对于距离超平面最近的样本点, z ( k ) ( ∑ ω i X i ( k ) + b ) ≥ 1 z^{(k)}(\sum\omega_iX_i^{(k)}+b)\ge1 z(k)(∑ωiXi(k)+b)≥1取到等号。
即对于正实例, z ( k ) = + 1 , ∑ ω i X i ( k ) + b = 1 z^{(k)}=+1,\sum\omega_iX_i^{(k)}+b=1 z(k)=+1,∑ωiXi(k)+b=1
对于负实例, z ( k ) = − 1 , ∑ ω i X i ( k ) + b = − 1 z^{(k)}=-1,\sum\omega_iX_i^{(k)}+b=-1 z(k)=−1,∑ωiXi(k)+b=−1
2.4 支持向量机模型的对偶问题
支持向量机模型转换成约束条件下最优化问题,也就是一个求解条件极值的问题,回忆大学数学,关于求解条件极值问题有一个很好的方案——拉格朗日乘子法。
2.4.1 拉格朗日乘子法
对于一个一般性的约束最优化问题①,如下
min f ( x ) s . t . g i ( x ) ≤ 0 h i ( x ) = 0 \begin{aligned}& \min \quad f(x)\\ &s.t. \quad g_i(x)\le0\\ &\qquad h_i(x)=0\end{aligned} minf(x)s.t.gi(x)≤0hi(x)=0
这是一个典型的条件极值问题,其中约束条件有等式约束与不等式约束。
使用拉格朗日乘子法建立拉格朗日函数 L ( x , α i , λ i ) L(x, \alpha_i, \lambda_i) L(x,αi,λi),如下
L ( x , α i , λ i ) = f ( x ) + ∑ i α i g i ( x ) + ∑ i λ i h i ( x ) L(x, \alpha_i, \lambda_i)=f(x)+\sum_i\alpha_ig_i(x)+\sum_i\lambda_ih_i(x) L(x,αi,λi)=f(x)+i∑αigi(x)+i∑λihi(x)
上述条件极值问题就转化成如下一般极值问题。
min L ( x , α i , λ i ) \min\quad L(x, \alpha_i, \lambda_i) minL(x,αi,λi)
对于 f ( x ) f(x) f(x)是凸函数的情况下,拉格朗日函数的一般极值问题就是让一阶导数等于零即可。但是由于存在不等式约束,拉格朗日函数的一般极值问题就比较复杂。我们将原问题转化为两部分,1.等式约束,2.不等式约束。
2.4.2 KKT条件推导
等式约束
min f ( x ) s . t . h i ( x ) = 0 \begin{aligned}& \min \quad f(x)\\ &s.t. \quad h_i(x)=0\end{aligned} minf(x)s.t.hi(x)=0
这个时候拉格朗日函数 L ^ ( x , λ i ) = f ( x ) + ∑ i λ i h i ( x ) \hat L(x, \lambda_i)=f(x)+\sum_i\lambda_ih_i(x) L^(x,λi)=f(x)+∑iλihi(x),原问题的等式约束条件下取极小值问题就转化为无约束条件下拉格朗日函数 L ^ ( x , λ i ) \hat L(x, \lambda_i) L^(x,λi)取极小值问题,即
min L ^ ( x , λ i ) \min\quad \hat L(x,\lambda_i) minL^(x,λi)
当取到极小值的时候,拉格朗日函数 L ^ ( x , λ i ) \hat L(x, \lambda_i) L^(x,λi)满足以下关系
∇ L = 0 ⇒ { ∂ L ^ ∂ x = ∂ f ( x ) ∂ x + ∑ i λ i ∂ h i ( x ) ∂ x = 0 ∂ L ^ ∂ λ i = 0 \nabla L=0\quad\Rightarrow\quad \begin{cases}\frac{\partial \hat L}{\partial x}=\frac{\partial f(x)}{\partial x}+\sum_i \lambda_i\frac{\partial h_i(x)}{\partial x}=0\\ \frac{\partial \hat L}{\partial \lambda_i}=0 \end{cases} ∇L=0⇒{∂x∂L^=∂x∂f(x)+∑iλi∂x∂hi(x)=0∂λi∂L^=0
不等式约束
利用等式约束的结果,原问题①就变成拉格朗日函数 L ^ ( x , λ i ) \hat L(x,\lambda_i) L^(x,λi)的不等式约束条件下取极小值问题,即
min L ^ ( x , λ i ) s . t . g i ( x ) ≤ 0 \begin{aligned}\min \quad \hat L(x, \lambda_i)\\ s.t. \quad g_i(x)\le0 \end{aligned} minL^(x,λi)s.t.gi(x)≤0
同样再次利用拉格朗日乘子法建立拉格朗日函数 L ( x , α i , λ i ) L(x,\alpha_i,\lambda_i) L(x,αi,λi),即有
L ( x , α i , λ i ) = L ^ ( x , λ i ) + ∑ i α i g i ( x ) = f ( x ) + ∑ i α i g i ( x ) + ∑ i λ i h i ( x ) L(x, \alpha_i, \lambda_i)=\hat L(x,\lambda_i)+\sum_i\alpha_ig_i(x)=f(x)+\sum_i\alpha_ig_i(x)+\sum_i\lambda_ih_i(x) L(x,αi,λi)=L^(x,λi)+i∑αigi(x)=f(x)+i∑αigi(x)+i∑λihi(x)
定义原问题的可行域(定义域)为 { x ∈ R n ∣ g i ( x ) ≤ 0 } \{x\in R^n|g_i(x)\le0\} {x∈Rn∣gi(x)≤0}。假设存在一个 x ∗ x^* x∗是满足可行域的极值问题的最佳解,那么存在下式
∇ L = 0 ⇒ { ∂ L ∂ x = ∂ L ^ ( x ∗ ) ∂ x + ∑ α i ∂ g i ( x ∗ ) ∂ x = ∂ f ( x ∗ ) ∂ x + ∑ λ i ∂ h i ( x ∗ ) ∂ x + ∑ α i ∂ g i ( x ∗ ) ∂ x = 0 ∂ L ^ ∂ λ i = 0 \nabla L=0\quad\Rightarrow\quad \begin{cases}\frac{\partial L}{\partial x}=\frac{\partial \hat L(x^*)}{\partial x}+\sum\alpha_i\frac{\partial g_i(x^*)}{\partial x}=\frac{\partial f(x^*)}{\partial x}+\sum\lambda_i\frac{\partial h_i(x^*)}{\partial x}+\sum\alpha_i\frac{\partial g_i(x^*)}{\partial x}=0\\ \frac{\partial \hat L}{\partial \lambda_i}=0 \end{cases} ∇L=0⇒{∂x∂L=∂x∂L^(x∗)+∑αi∂x∂gi(x∗)=∂x∂f(x∗)+∑λi∂x∂hi(x∗)+∑αi∂x∂gi(x∗)=0∂λi∂L^=0
我们讨论 x ∗ x^* x∗,那么实际上只存在两种情况,即
-
如果 x ∗ x^* x∗在可行域内,即有 g i ( x ) < 0 g_i(x)\lt 0 gi(x)<0,由于 L ^ ( x , λ i ) \hat L(x, \lambda_i) L^(x,λi)是凸函数,那么显然 x ∗ x^* x∗就是全局极小值, g i ( x ) < 0 g_i(x)\lt 0 gi(x)<0实际上是冗余条件,必然可以满足,可知 α i = 0 \alpha_i=0 αi=0。
-
如果 x ∗ x^* x∗在可行域边界,即有 g i ( x ) = 0 g_i(x)=0 gi(x)=0,由于 L ^ ( x , λ i ) \hat L(x, \lambda_i) L^(x,λi)是凸函数,如果 x ∗ x^* x∗不是全局极小值,那么一定有 L ^ ( x , λ i ) \hat L(x, \lambda_i) L^(x,λi)梯度方向( ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi))指向可行域(即 L ^ ( x , λ i ) \hat L(x, \lambda_i) L^(x,λi)朝向可行域内部是增函数),由于 g i ( x ) g_i(x) gi(x)的梯度是指向可行域以外(因为可行域内是 g i ( x ) < 0 g_i(x)\lt0 gi(x)<0,可行域以外是 g i ( x ) > 0 g_i(x)\gt0 gi(x)>0,那么在边界上指向可行域以外 g i ( x ) g_i(x) gi(x)是增函数),如图所示。
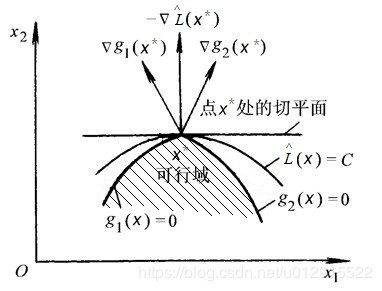
那么现在讨论梯度方向 ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi)与 ∂ g i ( x ) ∂ x \frac{\partial g_i(x)}{\partial x} ∂x∂gi(x)之间的关系,实际上可以得出梯度方向 ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi)一定在 ∂ g i ( x ) ∂ x \frac{\partial g_i(x)}{\partial x} ∂x∂gi(x)组成的锥体内,否则,假设在锥体外,如下图所示, ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi)不在锥体内,假设 ∂ g i ( x ) ∂ x \frac{\partial g_i(x)}{\partial x} ∂x∂gi(x)都在 ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi)左侧,黑色斜剖面线是 g 2 ( x ) ≤ 0 g_2(x)\le0 g2(x)≤0,绿色斜剖面线是 g 1 ( x ) ≤ 0 g_1(x)\le0 g1(x)≤0,红色部分即为不等式约束条件下的可行域。其中 l L ^ l_{\hat L} lL^是点 X ∗ X^* X∗处的切平面, l g i l_{g_i} lgi是点 X ∗ X^* X∗处的 g i g_i gi切平面,切平面 l L ^ l_{\hat L} lL^与切平面 g i g_i gi的关系如下图中所示。
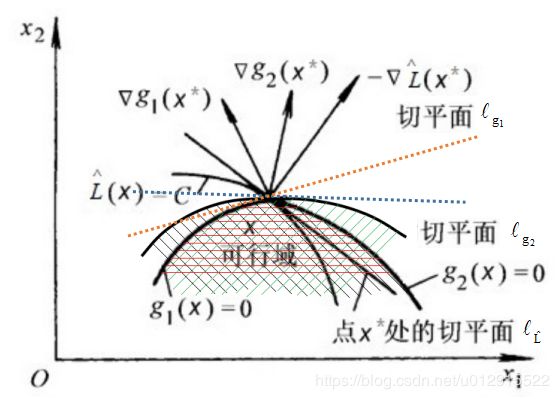
那么可行域与 L ( x ) L(x) L(x)的等高线之间必然存在如下图蓝色斜剖面线的区域,而蓝色斜剖面线区域在 L ( x ) L(x) L(x)减小的方向,所以在蓝色斜剖面线中 L ( x ) < C L(x)\lt C L(x)<C,这与在 x ∗ x^* x∗处取极小值相违背,所以 ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi)不在锥体内不成立。
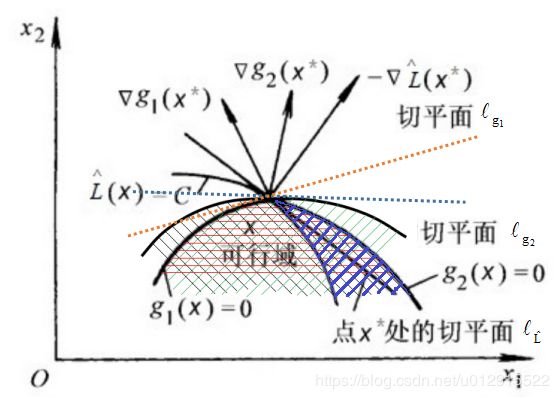
∂ L ^ ( x ∗ ) ∂ x + ∑ α i ∂ g i ( x ∗ ) ∂ x = 0 ⇒ − ∂ L ^ ( x ∗ ) ∂ x = ∑ α i ∂ g i ( x ∗ ) ∂ x \frac{\partial \hat L(x^*)}{\partial x}+\sum\alpha_i\frac{\partial g_i(x^*)}{\partial x}=0 \Rightarrow -\frac{\partial \hat L(x^*)}{\partial x}=\sum\alpha_i\frac{\partial g_i(x^*)}{\partial x} ∂x∂L^(x∗)+∑αi∂x∂gi(x∗)=0⇒−∂x∂L^(x∗)=∑αi∂x∂gi(x∗)
由 ∂ L ^ ( x , λ i ) ∂ x \frac{\partial \hat L(x, \lambda_i)}{\partial x} ∂x∂L^(x,λi)在锥体内成立,可得 α i ≥ 0 \alpha_i\ge0 αi≥0。
综合两种情况,必然有 α i h i ( x ) = 0 \alpha_ih_i(x)=0 αihi(x)=0成立。
所以原问题① 取到极小值拉格朗日函数 L ( x , α i , λ i ) L(x,\alpha_i,\lambda_i) L(x,αi,λi)必然满足以下关系式
{ ∂ L ( x , α i , λ i ) ∂ x = 0 ∂ L ( x , α i , λ i ) ∂ α i = 0 ∂ L ( x , α i , λ i ) ∂ λ i = 0 g i ( x ) ≤ 0 h i ( x ) = 0 α i ≥ 0 α i h i ( x ) = 0 \begin{cases}\frac{\partial L(x,\alpha_i,\lambda_i)}{\partial x}=0\\ \frac{\partial L(x,\alpha_i,\lambda_i)}{\partial \alpha_i}=0\\ \frac{\partial L(x,\alpha_i,\lambda_i)}{\partial \lambda_i}=0\\ g_i(x)\le0\\ h_i(x)=0\\ \alpha_i\ge0\\ \alpha_ih_i(x)=0 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂x∂L(x,αi,λi)=0∂αi∂L(x,αi,λi)=0∂λi∂L(x,αi,λi)=0gi(x)≤0hi(x)=0αi≥0αihi(x)=0
这组条件就叫Karush-Kuhn-Tucker (KKT)条件。
2.4.3 拉格朗日对偶问题
(证明思路摘自《统计学习方法》附录C)
原问题的转化
对于一个一般性的约束最优化问题①,如下
min f ( x ) s . t . g i ( x ) ≤ 0 h i ( x ) = 0 \begin{aligned}& \min \quad f(x)\\ &s.t. \quad g_i(x)\le0\\ &\qquad h_i(x)=0\end{aligned} minf(x)s.t.gi(x)≤0hi(x)=0
其拉格朗日函数为 L ( x , α i , λ i ) L(x,\alpha_i,\lambda_i) L(x,αi,λi),即有
L ( x , α i , λ i ) = L ^ ( x , λ i ) + ∑ i α i g i ( x ) = f ( x ) + ∑ i α i g i ( x ) + ∑ i λ i h i ( x ) L(x, \alpha_i, \lambda_i)=\hat L(x,\lambda_i)+\sum_i\alpha_ig_i(x)=f(x)+\sum_i\alpha_ig_i(x)+\sum_i\lambda_ih_i(x) L(x,αi,λi)=L^(x,λi)+i∑αigi(x)=f(x)+i∑αigi(x)+i∑λihi(x)
定义
θ P = max α i , λ i ; α i ≥ 0 [ L ( x , α i , λ i ) ] \theta_P=\max_{\alpha_i,\lambda_i;\alpha_i\ge0} [L(x, \alpha_i, \lambda_i)] θP=αi,λi;αi≥0max[L(x,αi,λi)]
在可行域内,对于拉格朗日函数 L ( x , α i , λ i ) L(x,\alpha_i,\lambda_i) L(x,αi,λi),必然有
L ( x , α i , λ i ) = f ( x ) + ∑ i α i g i ( x ) + ∑ i λ i h i ( x ) ≡ f ( x ) \begin{aligned}L(x, \alpha_i, \lambda_i)&=f(x)+\cancel{\sum_i\alpha_ig_i(x)}+\cancel{\sum_i\lambda_ih_i(x)}\\&\equiv f(x) \end{aligned} L(x,αi,λi)=f(x)+i∑αigi(x) +i∑λihi(x) ≡f(x)
故,
θ P = max α i , λ i ; α i ≥ 0 [ L ( x , α i , λ i ) ] = f ( x ) \theta_P=\max_{\alpha_i,\lambda_i;\alpha_i\ge0} [L(x, \alpha_i, \lambda_i)]=f(x) θP=αi,λi;αi≥0max[L(x,αi,λi)]=f(x)
在可行域外,比如 g i ( x ) > 0 o r h i ( x ) = 0 g_i(x)\gt0 \quad or\quad h_i(x)\cancel =0 gi(x)>0orhi(x)= 0,那么 θ P = + ∞ \theta_P=+\infty θP=+∞。
θ P = max α i , λ i ; α i ≥ 0 [ L ( x , α i , λ i ) ] = { f ( x ) + ∞ \theta_P=\max_{\alpha_i,\lambda_i;\alpha_i\ge0} [L(x, \alpha_i, \lambda_i)]=\begin{cases}&f(x)\\&+\infty\end{cases} θP=αi,λi;αi≥0max[L(x,αi,λi)]={f(x)+∞
那么原问题就转化为
min x max α i , λ i ; α i ≥ 0 [ L ( x , α i , λ i ) ] \min_x \max_{\alpha_i,\lambda_i;\alpha_i\ge0} [L(x, \alpha_i, \lambda_i)] xminαi,λi;αi≥0max[L(x,αi,λi)]
这样就把约束条件下的优化问题转化成无条件约束问题。
对偶问题
定义
θ D = min x L ( x , α i , λ i ) \theta_D=\min_x L(x,\alpha_i,\lambda_i) θD=xminL(x,αi,λi)
那么
max α i , λ i ; α i ≤ 0 θ D = max α i , λ i ; α i ≤ 0 min x L ( x , α i , λ i ) \max_{\alpha_i,\lambda_i;\alpha_i\le0}\theta_D=\max_{\alpha_i,\lambda_i;\alpha_i\le0}\min_x L(x,\alpha_i,\lambda_i) αi,λi;αi≤0maxθD=αi,λi;αi≤0maxxminL(x,αi,λi)
为拉格朗日对偶问题,上式可写成一般形式的约束条件下的最大值问题
max α i , λ i ; α i ≤ 0 θ D = max α i , λ i ; α i ≤ 0 min x L ( x , α i , λ i ) s . t . α i ≤ 0 \begin{aligned}&\max_{\alpha_i,\lambda_i;\alpha_i\le0}\theta_D=\max_{\alpha_i,\lambda_i;\alpha_i\le0}\min_x L(x,\alpha_i,\lambda_i)\\ & \quad s.t.\quad \alpha_i\le0 \end{aligned} αi,λi;αi≤0maxθD=αi,λi;αi≤0maxxminL(x,αi,λi)s.t.αi≤0
这是原问题的对偶问题。
原问题与对偶问题的关系
若原问题和对偶问题都存在最优解,假设 d ∗ d^* d∗为对偶问题的最优解, p ∗ p^* p∗为原问题的最优解,那么
θ D = min x L ( x , α i , λ i ) ≤ L ( x , α i , λ i ) ≤ max α i , λ i ; α i ≤ 0 L ( x , α i , λ i ) = θ P \theta_D=\min_xL(x,\alpha_i,\lambda_i)\le L(x,\alpha_i,\lambda_i) \le \max_{\alpha_i,\lambda_i;\alpha_i\le0}L(x,\alpha_i,\lambda_i)=\theta_P θD=xminL(x,αi,λi)≤L(x,αi,λi)≤αi,λi;αi≤0maxL(x,αi,λi)=θP
d ∗ = max α i , λ i ; α i ≤ 0 min x L ( x , α i , λ i ) ≤ min x max α i , λ i ; α i ≤ 0 L ( x , α i , λ i ) = p ∗ d^*=\max_{\alpha_i,\lambda_i;\alpha_i\le0}\min_xL(x,\alpha_i,\lambda_i)\le \min_x\max_{\alpha_i,\lambda_i;\alpha_i\le0}L(x,\alpha_i,\lambda_i)=p^* d∗=αi,λi;αi≤0maxxminL(x,αi,λi)≤xminαi,λi;αi≤0maxL(x,αi,λi)=p∗
我们成这个关系为拉格朗日弱对偶性,如果等式严格成立,我们称之为拉格朗日强对偶性。
我们不加证明的引入以下引理(Slater条件)
引理:当原问题为凸优化问题,且存在严格满足不等式约束条件的 x x x,那么存在一组 ( x ∗ , α i ∗ , λ i ∗ ) (x^*,\alpha_i^*,\lambda_i^*) (x∗,αi∗,λi∗)是原问题的最优解,也是对偶问题的最优解,且满足强对偶性 d ∗ = p ∗ = L ( x ∗ , α i ∗ , λ i ∗ ) d^*=p^*=L(x^*,\alpha_i^*,\lambda_i^*) d∗=p∗=L(x∗,αi∗,λi∗)。
对偶问题的KKT条件
在满足强对偶性的条件下,求解原问题可以转化求解对偶问题,由于原问题约束复杂,相对来说对偶问题会比较好求解。当然原问题取到极值的kkt条件在求解对偶问题的时候依旧成立。
{ ∂ L ( x , α i , λ i ) ∂ x = 0 ∂ L ( x , α i , λ i ) ∂ α i = 0 ∂ L ( x , α i , λ i ) ∂ λ i = 0 g i ( x ) ≤ 0 h i ( x ) = 0 α i ≥ 0 α i h i ( x ) = 0 \begin{cases}\frac{\partial L(x,\alpha_i,\lambda_i)}{\partial x}=0\\ \frac{\partial L(x,\alpha_i,\lambda_i)}{\partial \alpha_i}=0\\ \frac{\partial L(x,\alpha_i,\lambda_i)}{\partial \lambda_i}=0\\ g_i(x)\le0\\ h_i(x)=0\\ \alpha_i\ge0\\ \alpha_ih_i(x)=0 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂x∂L(x,αi,λi)=0∂αi∂L(x,αi,λi)=0∂λi∂L(x,αi,λi)=0gi(x)≤0hi(x)=0αi≥0αihi(x)=0
2.4.4 支持向量机模型的对偶问题
支持向量机原问题为
( ω i , b ) → = min ( ω i , b ) ∣ ∣ W ∣ ∣ 2 2 s . t . 1 − z ( k ) ( ∑ ω i X i ( k ) + b ) ≤ 0 , k = 1 , . . . , N \begin{aligned}&(\omega_i,b)\to =\min_{(\omega_i,b)} \frac{||W||^2}{2}\\ &\qquad\qquad s.t. \quad 1-z^{(k)}(\sum\omega_iX_i^{(k)}+b)\le0,k=1,...,N \end{aligned} (ωi,b)→=(ωi,b)min2∣∣W∣∣2s.t.1−z(k)(∑ωiXi(k)+b)≤0,k=1,...,N
那么拉格朗日函数为
L ( α i , b , α i , λ i ) = ∣ ∣ W ∣ ∣ 2 2 + ∑ k α k [ 1 − z ( k ) ( ∑ ω i X i ( k ) + b ) ] L(\alpha_i,b, \alpha_i, \lambda_i)=\frac{||W||^2}{2}+\sum_k\alpha_k[1-z^{(k)}(\sum\omega_iX_i^{(k)}+b)] L(αi,b,αi,λi)=2∣∣W∣∣2+k∑αk[1−z(k)(∑ωiXi(k)+b)]
那么原问题等价于
min ω k , b max α i ; α i ≥ 0 L ( ω i , b , α i ) \min_{\omega_k,b}\max_{ \alpha_i;\alpha_i\ge0}L(\omega_i,b, \alpha_i) ωk,bminαi;αi≥0maxL(ωi,b,αi)
其拉格朗日对偶问题为
max α i min ω i , b L ( ω i , b , α i ) s . t . α i ≥ 0 \begin{aligned}&\max_{ \alpha_i}\min_{\omega_i,b}L(\omega_i,b, \alpha_i)\\&s.t.\quad\alpha_i\ge0\end{aligned} αimaxωi,bminL(ωi,b,αi)s.t.αi≥0
由kkt条件求解该问题。
-
由 ∇ L = 0 \nabla L=0 ∇L=0 可以得到以下关系式
∂ L ( W , b , α i ) ∂ W = W − ∑ α k z ( k ) X k = 0 \frac{\partial L(W,b,\alpha_i)}{\partial W}=W-\sum\alpha_kz^{(k)}X^{k}=0 ∂W∂L(W,b,αi)=W−∑αkz(k)Xk=0
∂ L ( W , b , α i ) ∂ W = − ∑ α k z ( k ) = 0 \frac{\partial L(W,b,\alpha_i)}{\partial W}=-\sum\alpha_kz^{(k)}=0 ∂W∂L(W,b,αi)=−∑αkz(k)=0
代入拉格朗日函数,得到
L ( α i , b , α i ) = ∣ ∣ W ∣ ∣ 2 2 + ∑ k α k [ 1 − z ( k ) ( ∑ ω i X i ( k ) + b ) ] = 1 2 ( ∑ k α k z ( k ) X ( k ) ) ∙ ( ∑ k α k z ( k ) X ( k ) ) + ∑ k α k { 1 − z ( k ) [ X ( k ) ∙ ( ∑ k α k z ( k ) X ( k ) ) + b ) ] } = 1 2 ∑ i ∑ j α i α j z ( i ) z ( j ) ( X ( i ) ∙ X ( j ) ) − ∑ i ∑ j α i z ( i ) α j z ( j ) ( X ( i ) ∙ X ( j ) ) − ∑ i α i z ( i ) b + ∑ i α i = − 1 2 ∑ i ∑ j α i α j z ( i ) z ( j ) ( X ( i ) ∙ X ( j ) ) + ∑ i α i \begin{aligned}L(\alpha_i,b, \alpha_i)&=\frac{||W||^2}{2}+\sum_k\alpha_k[1-z^{(k)}(\sum\omega_iX_i^{(k)}+b)]\\ &=\frac12(\sum_k\alpha_kz^{(k)}X^{(k)})\bullet(\sum_k\alpha_kz^{(k)}X^{(k)})+\sum_k\alpha_k\{1-z^{(k)}[X^{(k)}\bullet (\sum_k\alpha_kz^{(k)}X^{(k)})+b)]\}\\ &=\frac12\sum_i\sum_j\alpha_i\alpha_jz^{(i)}z^{(j)}(X^{(i)}\bullet X^{(j)})-\sum_i\sum_j\alpha_iz^{(i)}\alpha_jz^{(j)}(X^{(i)}\bullet X^{(j)})-\cancel{\sum_i\alpha_iz^{(i)}b}+\sum_i\alpha_i \\&=-\frac12\sum_i\sum_j\alpha_i\alpha_jz^{(i)}z^{(j)}(X^{(i)}\bullet X^{(j)})+\sum_i\alpha_i\end{aligned} L(αi,b,αi)=2∣∣W∣∣2+k∑αk[1−z(k)(∑ωiXi(k)+b)]=21(k∑αkz(k)X(k))∙(k∑αkz(k)X(k))+k∑αk{1−z(k)[X(k)∙(k∑αkz(k)X(k))+b)]}=21i∑j∑αiαjz(i)z(j)(X(i)∙X(j))−i∑j∑αiz(i)αjz(j)(X(i)∙X(j))−i∑αiz(i)b +i∑αi=−21i∑j∑αiαjz(i)z(j)(X(i)∙X(j))+i∑αi
拉格朗日对偶问题进一步简化为
max α i − 1 2 ∑ i ∑ j α i α j z ( i ) z ( j ) ( X ( i ) ∙ X ( j ) ) + ∑ i α i s . t . α i ≥ 0 ∑ i α i z ( i ) = 0 \begin{aligned}&\max_{ \alpha_i}-\frac12\sum_i\sum_j\alpha_i\alpha_jz^{(i)}z^{(j)}(X^{(i)}\bullet X^{(j)})+\sum_i\alpha_i\\&s.t.\quad\alpha_i\ge0\\&\qquad\sum_i\alpha_iz^{(i)}=0\end{aligned} αimax−21i∑j∑αiαjz(i)z(j)(X(i)∙X(j))+i∑αis.t.αi≥0i∑αiz(i)=0
一般将上述求最大值问题转换为求最小值问题。
min α i 1 2 ∑ i ∑ j α i α j z ( i ) z ( j ) ( X ( i ) ∙ X ( j ) ) − ∑ i α i s . t . α i ≥ 0 ∑ i α i z ( i ) = 0 \begin{aligned}&\min_{ \alpha_i}\frac12\sum_i\sum_j\alpha_i\alpha_jz^{(i)}z^{(j)}(X^{(i)}\bullet X^{(j)})-\sum_i\alpha_i\\&s.t.\quad\alpha_i\ge0\\&\qquad\sum_i\alpha_iz^{(i)}=0\end{aligned} αimin21i∑j∑αiαjz(i)z(j)(X(i)∙X(j))−i∑αis.t.αi≥0i∑αiz(i)=0 -
求解拉格朗日对偶问题得到参数 { α i ∗ , i = 1 , . . . , N } \{\alpha_i^*,i=1,...,N\} {αi∗,i=1,...,N},不难得到 W ∗ = ∑ i = 1 N α i ∗ z ( i ) X ( i ) W^*=\sum_{i=1}^N\alpha_i^*z^{(i)}X^{(i)} W∗=i=1∑Nαi∗z(i)X(i)
3.由函数间隔的定义,必定存在某一点使得 1 − z ( k ) ( ∑ ω i X i ( k ) + b ) ≤ 0 1-z^{(k)}(\sum\omega_iX_i^{(k)}+b)\le0 1−z(k)(∑ωiXi(k)+b)≤0 等式严格成立,即存在 X ( ∗ ) X^{(*)} X(∗)(实际上就是离分割超平面最近的样本点),使 1 − z ( t ) ( ∑ i = 0 l ω i ∗ X i ( t ) + b ∗ ) = 0 1-z^{(t)}(\sum_{i=0}^l\omega_i^*X_i^{(t)}+b^*)=0 1−z(t)(i=0∑lωi∗Xi(t)+b∗)=0
b ∗ = z ( t ) − ∑ i = 0 l ω i ∗ X i ( t ) = z ( t ) − W ∗ X ( t ) = z ( t ) − ∑ i = 1 N α i ∗ z ( i ) ( X ( i ) ∙ X ( t ) ) b^*=z^{(t)}-\sum_{i=0}^l\omega_i^*X_i^{(t)}=z^{(t)}-W^*X^{(t)}=z^{(t)}-\sum_{i=1}^N\alpha_i^*z^{(i)}(X^{(i)}\bullet X^{(t)}) b∗=z(t)−i=0∑lωi∗Xi(t)=z(t)−W∗X(t)=z(t)−i=1∑Nαi∗z(i)(X(i)∙X(t))
(对于距离分割超平面最近的样本点,那么必然存在 α t ∗ > 0 \alpha_t^*\gt0 αt∗>0,其实根据KKT条件中的相容性条件也可推得上述 b ∗ b^* b∗的关系式 α t ∗ ( 1 − z ( t ) ( ∑ ω i ∗ X i ( t ) + b ) ) = 0 \alpha_t^*(1-z^{(t)}(\sum\omega_i^*X_i^{(t)}+b))=0 αt∗(1−z(t)(∑ωi∗Xi(t)+b))=0)
所以求解问题的一般步骤是:1)求解对偶问题的最优解 α i ∗ \alpha_i^* αi∗,2)按公式求解 W ∗ W^* W∗,3)求解 b ∗ b^* b∗。
参考文献:
[1]. 机器学习[M]. 周志华.
[2]. 统计学习方法[M]. 李航
[3]. Python机器学习算法[M].赵志勇.
文章导引列表:
机器学习
- 小瓜讲机器学习——分类算法(一)logistic regression(逻辑回归)算法原理详解
- 小瓜讲机器学习——分类算法(二)支持向量机(SVM)算法原理详解
- 小瓜讲机器学习——分类算法(三)朴素贝叶斯法(naive Bayes)
- 待续
数据分析
- 小呆学数据分析——使用pandas中的merge函数进行数据集合并
- 小呆学数据分析——使用pandas中的concat函数进行数据集堆叠
- 小呆学数据分析——pandas中的层次化索引
- 小呆学数据分析——使用pandas的pivot进行数据重塑
- 小呆学数据分析——用duplicated/drop_duplicates方法进行重复项处理
- 小呆学数据分析——缺失值处理(一)
- 小呆学数据分析——异常值判定与处理(一)
- 小瓜讲数据分析——数据清洗
数据可视化
- 小瓜讲数据分析——数据可视化工程(matplotlib库使用基础篇)
- 小瓜讲matplotlib高级篇——坐标轴设置(坐标轴居中、坐标轴箭头、刻度设置、标识设置)