keras 利用vgg16处理kaggle的猫狗大战二分类问题
一,kaggle的猫狗打大战数据集
Kaggle猫狗大战的数据集下载链接:https://www.kaggle.com/c/dogs-vs-cats
二,vgg网络
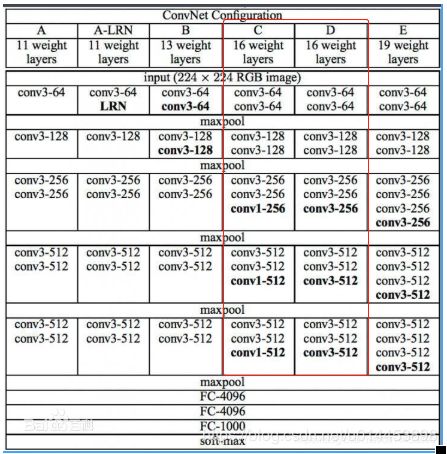
vgg是拥有比较深层数的cnn网络(当然比不上resnet),其中vgg按照层数的不同分为了vgg11,vgg13,vgg16,vgg19,举例说明vgg11就是卷积层加上全连接层一共11层,具体如下图,其中红色框框住的C,D,就是vgg16的两种实现方式,其中本来实现的是D方式:
三,训练代码:
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, BatchNormalization
from keras import optimizers
import numpy as np
from keras.layers.core import Lambda
from keras import backend as K
from keras.optimizers import SGD
from keras import regularizers
import os
import matplotlib.pyplot as plt
import cv2
import keras.models
resize = 224
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
path = r"F:\dataset\dogs-vs-cats\train" #数据集位置
'''从训练集中取5000张作为训练集,再取5000张作为测试集'''
def load_data():
imgs = os.listdir(path)
num = len(imgs)
train_data = np.empty((5000, resize, resize, 3), dtype="int32")
train_label = np.empty((5000, ), dtype="int32")
test_data = np.empty((5000, resize, resize, 3), dtype="int32")
test_label = np.empty((5000, ), dtype="int32")
for i in range(5000):
if i % 2:
train_data[i] = cv2.resize(cv2.imread(path+'/'+ 'dog.' + str(i) + '.jpg'), (resize, resize))
train_label[i] = 1
else:
train_data[i] = cv2.resize(cv2.imread(path+'/' + 'cat.' + str(i) + '.jpg'), (resize, resize))
train_label[i] = 0
for i in range(5000, 10000):
if i % 2:
test_data[i-5000] = cv2.resize(cv2.imread(path+'/' + 'dog.' + str(i) + '.jpg'), (resize, resize))
test_label[i-5000] = 1
else:
test_data[i-5000] = cv2.resize(cv2.imread(path+'/' + 'cat.' + str(i) + '.jpg'), (resize, resize))
test_label[i-5000] = 0
return train_data, train_label, test_data, test_label
def vgg16():
weight_decay = 0.0005
nb_epoch = 100
batch_size = 32
# layer1
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same',
input_shape=(224, 224, 3), kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
# layer2
model.add(Conv2D(64, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# layer3
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer4
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# layer5
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer6
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer7
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# layer8
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer9
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer10
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
# layer11
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer12
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# layer13
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
# layer14
model.add(Flatten())
model.add(Dense(512, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# layer15
model.add(Dense(512, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# layer16
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('softmax'))
return model
if __name__ == '__main__':
# import data
train_data, train_label, test_data, test_label = load_data()
train_data = train_data.astype('float32')
test_data = test_data.astype('float32')
train_label = keras.utils.to_categorical(train_label, 2) #把label转成onehot化
test_label = keras.utils.to_categorical(test_label, 2) #把label转成onehot化
model = vgg16()
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) #设置优化器为SGD
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
history = model.fit(train_data, train_label,
batch_size=10,
epochs=100,
validation_split=0.2, #把训练集中的五分之一作为验证集
shuffle=True)
model.save('vgg16dogcat.h5')
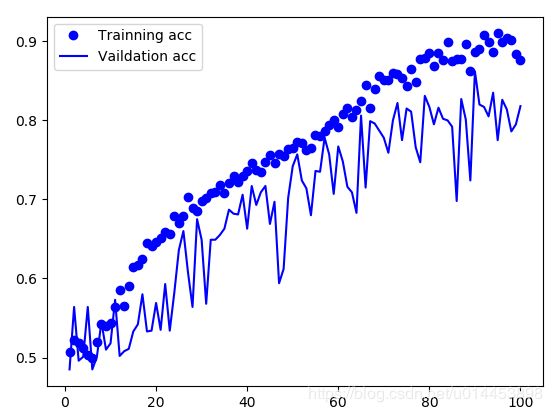
###huatu
acc = history.history['acc'] # 获取训练集准确性数据
val_acc = history.history['val_acc'] # 获取验证集准确性数据
loss = history.history['loss'] # 获取训练集错误值数据
val_loss = history.history['val_loss'] # 获取验证集错误值数据
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Trainning acc') # 以epochs为横坐标,以训练集准确性为纵坐标
plt.plot(epochs, val_acc, 'b', label='Vaildation acc') # 以epochs为横坐标,以验证集准确性为纵坐标
plt.legend() # 绘制图例,即标明图中的线段代表何种含义
plt.show()运行效果:

并且会保存一个名为vgg16dogcat.h5的模型。
四,测试代码
from keras.models import load_model
import cv2
import numpy as np
import os
os.environ['CUDA_VISIBLE_DEVICES']='1'
resize = 224
def jundge(predicted):
predicted = np.argmax(predicted)
if predicted == 0:
print('cat')
else:
print('dog')
load_model = load_model("./vgg16dogcat.h5") # 读取模型
img = cv2.imread('cat.png') # 读入灰度图
img = cv2.resize(img, (resize, resize))
img = img.reshape(-1,resize,resize,3)
img = img.astype('float32')
predicted = load_model.predict(img) # 输出预测结果
print(predicted)
jundge(predicted)
网上找一张图片:

然后运行结果:

第一行分别显示预测为猫的概率和狗的概率,可以看到预测为猫的概率有0.93,而预测为狗的概率有0.065.
第二行是选择大概率的一项,即显示为cat。