Hive中with cube、with rollup、grouping sets用法
表结构
-
CREATE
TABLE
test (f1
string,
-
f2
string,
-
f3
string,
-
cnt
int)
ROW
FORMAT
delimited
FIELDS
TERMINATED
BY
'\t'
stored
AS textfile;
-
LOAD
DATA
LOCAL inpath
'/data/logs/suiyingli/tmp/test.data' overwrite
INTO
TABLE
test;
原始数据
•A A B 1
•B B A 1
•A A A 2
1、with cube
查询语句
-
SELECT f1,
-
f2,
-
f3,
-
sum(cnt),
-
GROUPING__ID,
-
rpad(
reverse(
bin(
cast(GROUPING__ID
AS
bigint))),
3,
'0')
-
FROM
test
-
GROUP
BY f1,
-
f2,
-
f3
WITH
CUBE;
结果

with cube查询结果
2、with rollup
查询语句
-
SELECT f1,
-
f2,
-
f3,
-
sum(cnt),
-
GROUPING__ID,
-
rpad(
reverse(
bin(
cast(GROUPING__ID
AS
bigint))),
3,
'0')
-
FROM
test
-
GROUP
BY f1,
-
f2,
-
f3
WITH
ROLLUP;
结果

with rollup查询结果
3、grouping sets
查询语句
-
SELECT f1,
-
f2,
-
f3,
-
sum(cnt),
-
GROUPING__ID,
-
rpad(
reverse(
bin(
cast(GROUPING__ID
AS
bigint))),
3,
'0')
-
FROM
test
-
GROUP
BY f1,
-
f2,
-
f3
-
GROUPING
SETS((f1),(f1,f2))
结果
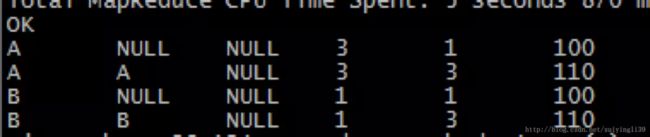
grouping sets查询结果
总结
cube的分组组合最全,是各个维度值的笛卡尔(包含null)组合,
rollup的各维度组合应满足,前一维度为null后一位维度必须为null,前一维度取非null时,下一维度随意,
grouping sets则为自定义维度,根据需要分组即可。
ps:通过grouping sets的使用可以简化SQL,比group by单维度进行union性能更好。
2、with cube统计结果处理:
CUBE 操作所生成的空值带来一个问题:如何区分 CUBE 操作所生成的 NULL 值和从实际数据中返回的 NULL 值?这个问题可用 GROUPING 函数解决。如果列中的值来自事实数据,则 GROUPING 函数返回 0;如果列中的值是 CUBE 操作所生成的 NULL,则返回 1。在 CUBE 操作中,所生成的 NULL 代表全体值。可将 SELECT 语句写成使用 GROUPING 函数将所生成的 NULL 替换为字符串 ALL。因为事实数据中的 NULL 表明数据值未知,所以 SELECT 语句还可译码为返回字符串 UNKNOWN 替代来自事实数据的 NULL。例如:
-
SELECT
CASE
WHEN (
GROUPING(Item) =
1)
THEN
'ALL'
-
ELSE
ISNULL(Item,
'UNKNOWN')
-
END
AS Item,
-
CASE
WHEN (
GROUPING(Color) =
1)
THEN
'ALL'
-
ELSE
ISNULL(Color,
'UNKNOWN')
-
END
AS Color,
-
SUM(Quantity)
AS QtySum
-
FROM Inventory
-
GROUP
BY Item, Color
WITH
CUBE;
多维数据集
CUBE 运算符可用于生成 n 维的多维数据集,即具有任意数目维度的多维数据集。只有一个维度的多维数据集可用于生成合计,例如:
-
-- 此 SELECT 语句返回的结果集既显示了 Item 中每个值的小计,也显示了 Item 中所有值的总计:
-
SELECT
CASE
WHEN (
GROUPING(Item) =
1)
THEN
'ALL'
-
ELSE
ISNULL(Item,
'UNKNOWN')
-
END
AS Item,
-
SUM(Quantity)
AS QtySum
-
FROM Inventory
-
GROUP
BY Item
WITH
CUBE;