Spark共享变量之广播变量和自定义累加器的介绍及使用
Shared Variables(共享变量)
在 Spark 程序中,当一个传递给 Spark 操作 (例如 map 和 reduce) 的函数在远程节点上面运行时,Spark 实际上操作的是这个函数所用变量的一个独立副本。这些在Driver端声明的变量会被复制到每个Executor进程所在的执行机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark 为两种常见的使用模式提供了两种有限的共享变量: 广播变量(Broadcast Variable)和 累加器(Accumulator)!
1.广播变量 broadcast
1.1 为什么需要使用广播变量?
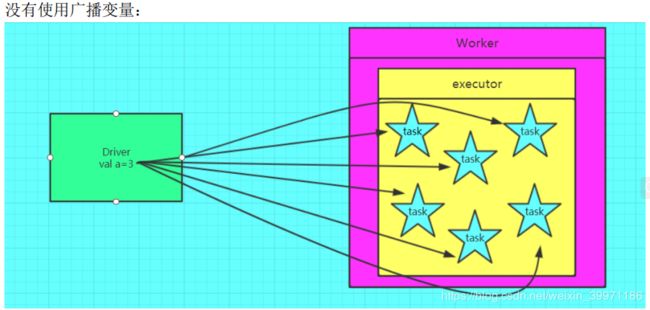
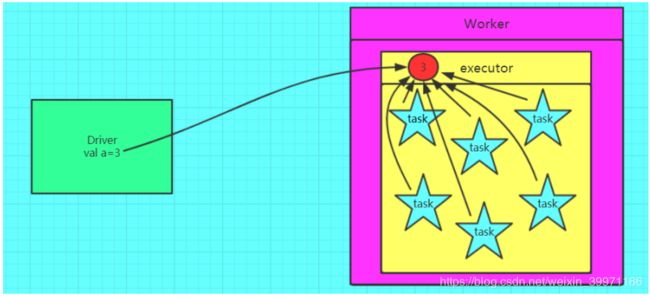
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由 Driver 端进行分发,一般来讲,如果这个变量不是广播变量,那么每个 task 就会分发一份, 这在 task 数目十分多的情况下 Driver 的带宽会成为系统的瓶颈,而且会大量消耗 task 服务器上的资源,如果将这个变量声明为广播变量,那么只是每个 executor 拥有一份,这个 executor 中启动的所有 task 会共享这个变量,节省了通信的成本和服务器的资源。
1.2 广播变量使用案例
import org.apache.spark.SparkContext
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* @author huleikai
* @create 2019-06-18 10:21
*/
object TestBroadcast {
def main(args: Array[String]): Unit = {
/* broadcast广播变量如果把某个变量进行了广播,
* 不表示每个task拥有一个副本,而是每一个executor中保持一个副本,
* 这个executor中的所有task公用这个变量副本
*/
val session: SparkSession = SparkSession.builder
.appName("TestBroadcast")
.master("local")
.getOrCreate()
val sc: SparkContext = session.sparkContext
val abc = 1
//将变量进行广播
val bc: Broadcast[Int] = sc.broadcast(abc)
val rdd: RDD[Int] = sc.makeRDD(1 to 10)
val result: RDD[Int] = rdd.map(_ + bc.value)
println(result.collect.mkString(" ")) //2 3 4 5 6 7 8 9 10 11
}
}注意:
① 不能将一个 RDD 使用广播变量广播出去,因为 RDD 是不存储数据的,可以将 RDD 的结果广播出去
② 广播变量只能在 Driver 端定义,不能在 Executor 端定义
③ 在 Driver 端可以修改广播变量的值,在 Executor 端无法修改广播变量的值
④ 如果 executor 端用到了 Driver 的变量,如果不使用广播变量在 Executor 有多少 task 就有多少 Driver 端的变量副本。如果 Executor 端用到了 Driver 的变量,如果使用广播变量在每个 Executor 中都只有一份 Driver 端的变量副本
1.3 广播变量使用对比效果图
2.Accumulators 累加器
2.1 为什么要定义累加器?
在 Spark 应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器。如果一个变量不被声明为一个累加器,那么它将在被改变时不会在 driver 端进行全局汇总,即在分布式运行时每个 task 运行的只是原始变量的 一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
2.2 累加器使用案例
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* @author huleikai
* @create 2019-06-18 10:23
*/
object TestAccumulator {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder
.appName("TestAccumulator")
.master("local")
.getOrCreate()
val sc: SparkContext = session.sparkContext
//累加器:在 Driver 端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新
val sumAccumulator = sc.longAccumulator("sum")
val numRDD: RDD[Int] = sc.makeRDD(1 to 100, 10)
numRDD.foreach(x => {
// executor中完成,效率比较高
sumAccumulator.add(1)
})
println(sumAccumulator.value) //100
}
}注意:
① 累加器在 Driver 端定义赋初始值,累加器只能在 Driver 端读取最后的值,在 Excutor 端更新
② 累加器的执行逻辑必须包含在一个action算子(比如:take、foreach等)或累加器之后必须有action算子调用存在,否则spark延迟加载不会立即划分job执行每个RDD逻辑,导致累加器的值value为0
③ 累加器不是一个调优的操作,因为如果不这样做,计数的结果是错的


2.3 累加器的执行过程
Driver端:Driver端初始化构建Accumulator并初始化,同时完成了Accumulator注册:Accumulators.register(this),同时Accumulator会在序列化后发送到Executor端,Driver接收到ResultTask完成的状态更新后,会去更新Value的值,然后在Action操作执行后就可以获取到Accumulator的值了
Executor端:Executor端接收到Task之后会进行反序列化操作,反序列化得到RDD和function,同时在反序列化的同时也去反序列化Accumulator(在readObject方法中完成),同时也会向TaskContext完成注册,完成任务计算之后,随着Task结果一起返回给Driver
2.4 自定义累加器 Accumulator
Spark原生地只支持数字类型 (Long类型) 的累加器,但是可能这种简单且固定的累加器不能满足我们开发中正常的业务统计需求,所以就需要使用到我们Spark提供的自定义累加器,其实自定义累加器类型的功能在Spark1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。官方同时给出了一个实现的示例:CollectionAccumulator类,这个类允许以集合的形式收集Spark应用执行过程中的一些信息。例如:我们可以用这个类收集Spark处理数据时的一些细节,当然,由于累加器的值最终要汇聚到driver端,为了避免 driver端的outofmemory问题,需要对收集的信息的规模要加以控制,不宜过大。
案例需求:统计指定的某个字符串中的a、b、c这三个字母出现的次数
案例演示:
① 自定义的统计a、b、c三个字母出现次数的累加器类
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
/**
* 统计指定的某个字符串中的a、b、c这三个字母出现的次数
*
* @author huleikai
* @create 2019-06-18 11:00
*/
class WordAggrAccumulator extends AccumulatorV2[String, scala.collection.mutable.Map[String, Int]] {
//需要返回的累加结果Map的初始状态
private val wordAggrMapZero = scala.collection.mutable.Map[String, Int]("a" -> 0, "b" -> 0, "c" -> 0)
//将累加器接受到的值累加后需要返回的累加结果Map
private var wordAggrMapValue = scala.collection.mutable.Map[String, Int]("a" -> 0, "b" -> 0, "c" -> 0)
//判断是否是初始状态,直接与原始状态的Map中的初始值进行对比
override def isZero: Boolean = {
if (wordAggrMapValue.get("a") != wordAggrMapZero.get("a")) {
return false
}
if (wordAggrMapValue.get("b") != wordAggrMapZero.get("b")) {
return false
}
if (wordAggrMapValue.get("c") != wordAggrMapZero.get("c")) {
return false
}
return true
}
//复制一个新的累加器
override def copy(): AccumulatorV2[String, scala.collection.mutable.Map[String, Int]] = {
val wordAggrAccumulator = new WordAggrAccumulator
for (elem <- wordAggrAccumulator.wordAggrMapValue) {
val key: String = elem._1
val oldValue: Int = elem._2
val currentVal: Int = this.wordAggrMapValue.get(key).get
val newValue = oldValue + currentVal
wordAggrAccumulator.wordAggrMapValue.update(key,newValue)
}
wordAggrAccumulator
}
//重置,恢复原始状态
override def reset(): Unit = {
for (elem <- wordAggrMapValue.keys) {
wordAggrMapValue.put(elem, 0)
}
}
//针对传入的字符串,与当前累加器现有的值进行累加
override def add(v: String): Unit = {
if (v == null || "".equals(v)) {
return
}
if (wordAggrMapValue.keySet.contains(v)) {
var oldValue: Int = wordAggrMapValue.get(v).get
oldValue += 1
wordAggrMapValue.put(v, oldValue)
}
}
//将两个累加器的计算结果进行合并
override def merge(other: AccumulatorV2[String, scala.collection.mutable.Map[String, Int]]): Unit = {
if (other == null) {
return
}
val otherMap: mutable.Map[String, Int] = other.value
for (elem <- otherMap) {
val key: String = elem._1
val value: Int = elem._2
var currentVal: Int = wordAggrMapValue.get(key).get
currentVal += value
wordAggrMapValue.put(key, currentVal)
}
}
//将此累加器的计算值返回
override def value: scala.collection.mutable.Map[String, Int] = {
wordAggrMapValue
}
}
② 自定义累加器的测试类
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* @author huleikai
* @create 2019-06-18 10:23
*/
object TestAccumulator {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder
.appName("TestAccumulator")
.master("local")
.getOrCreate()
val sc: SparkContext = session.sparkContext
val accumulator = new WordAggrAccumulator
//注册自定义累加器Accumulator
sc.register(accumulator)
//测试数据
val strRDD: RDD[String] = sc.parallelize(Array("a", "b", "a", "z", "c", "a", "c", "a", "c", "b"), 2)
strRDD.foreach(x => {
//累加统计
accumulator.add(x)
})
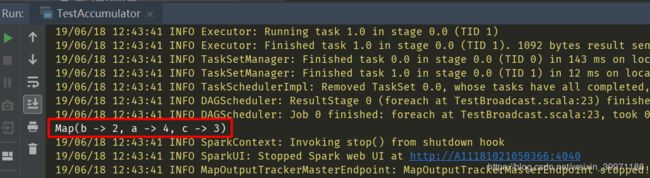
println(accumulator.value)
}
}最终测试的结果截图如下:
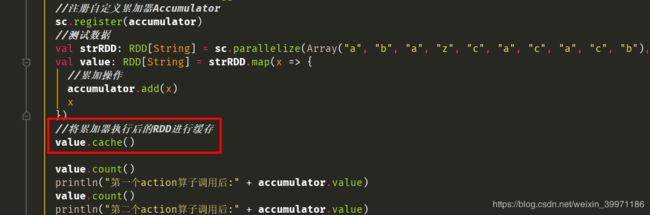
2.5 自定义累加器最常遇见的坑
① 程序运行没报错,但是自定义累加器的统计结果为零
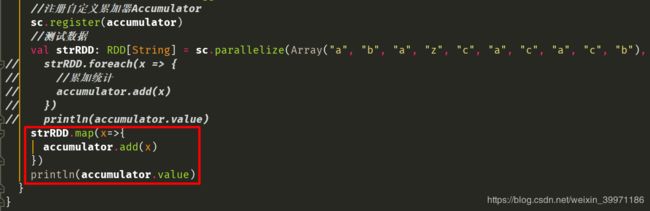
如上图所示,我们将foreach算子的处理注释掉,改用map算子进行累加统计,程序运行正常,没有报错,但是结果却是如下图所示,自定义的累加器统计结果为初始状态,没有进行累加统计,这是因为我们第一次的时候使用的foreach算子是action算子,它会触发Spark job划分及执行,但是当我们将foreach算子注释掉而改用map算子却没结果,因为map算子属于transformation算子,transformation算子属于延迟加载,它只会记录RDD的转化处理逻辑,等到action算子调用时才会触发job操作落地执行。
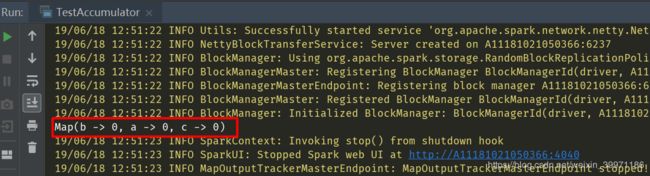
② 程序运行也没有报错,但是累加值结果和我们正常预期的不一致,多了几倍
这是因为当我们的累加器的累加操作是包含在transformtion算子中时,如果程序中有多次action算子被这个包含累加器处理的RDD调用操作,就会触发两次transform操作,相应地,累加器就会加两次,导致结果多几倍。
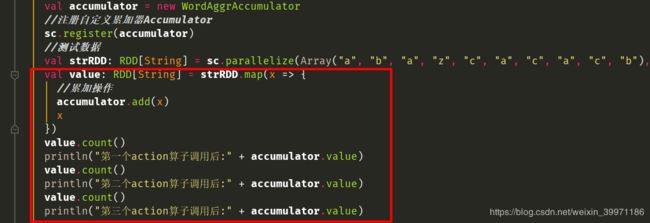
执行结果:

![]()
![]()
解决方案:
① 只使用一次包含了Accumulator的RDD的action算子一次,不再调用第二个或更多的action算子,导致累加器结果叠加
② 使用cache或persist方法,将包含Accumulator累加器的RDD的第一次计算结果进行缓存,防止后面RDD进行重复计算,导致累加器的值不准确