吴恩达深度学习之卷积神经网络(四)人脸识别和神经功能转换
1、什么是人脸识别
人脸识别就是识别人脸,比如手机人脸识别开机,人脸识别打卡等。
需要注意的是,人脸识别需要和活体检测(用来确认被识别的是一个活人)放在一起使用,这样才能避免用照片骗过手机或者打卡机,我们这里主要将人脸识别部分。
人脸识别相关术语:

验证问题:
输入:图片,名字/ID
输出:确认是否输入的信息与该人相符
识别问题:
假设有一个验证系统,其准确率为99%,假设在识别系统中有100个人需要识别,那么其很有可能会有一个人被识别错,如果需要识别的人很多,比如上班打卡,好几千人,那么如果 其准确率还是99%,那么其有可能会有几十个人被识别错,这种错误率相当大,所以,识别系统需要做到更高的准确度,百分之99.9%以上才说得过去。
所以,识别问题比验证问题难得多。验证问题是1对1,而识别问题是多对多。
2、one-shot学习
one-shot -学习就是在很少样本的情况下训练好系统,然后做到很高的识别率。

上图所示,如果数据库中的训练集只有上图右边四张图片,我们要识别这四个人,如果来一个测试集我们能识别出。这就是one-shot学习。
我们如果用传统的卷积神经网络去做模型很麻烦:
1、它需要很多训练集,这不符合one-shot学习的少量训练集。
2、就算用卷积神经网络,如果我们在公司首先识别四个人并且训练好了模型,当公司新来一个人,模型的softmax部分就要修改,这样需要重新训练模型,很麻烦。
引入one-shot学习:

similarity函数:d(imag1,imag2)=degree of difference between images
试想,如果数据库中有image1,新来一张imag2,如果他们直接的不同值很小,就可以认为他们很相似,如下图所示,我们设置一个阈值,我们两张图片小于阈值,就认为这两张图片一样,这样就识别出来了,这也是一个验证问题。

如果要将其引入到识别问题:
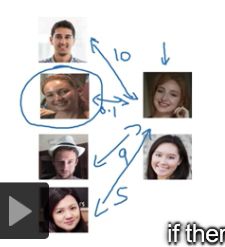
如上图所示,输入一张图片与数据库中图片做similarity函数计算,我们发现新图片与左边第二张图片的差别值最小,差不多就认为新的图片就是左边第二个人。
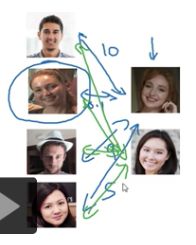
同理,又来一人又做该处理。
所以one-shot学习的精髓就是学习similarity函数,该函数学习好了,就能计算出新来图片和数据库中图片的差别值,若差别值小于某阈值,就任务两张图片一样,若大于则不同,这就做到了识别。若把one-shot函数用到公司打卡里,我们也只需将新来员工放到数据库中,这样当新来员工打卡刷脸时,也能识别。
3、siamese网络(将图片编码,用于计算两张图片的差值)
我们要得到d函数,就要训练siamese网络。
该网络用于训练一个神经网络用于将图片编码,编码后的数据用来计算图片之间的差值d。
d函数的作用就是输入两张图片,计算他们之间的差值。
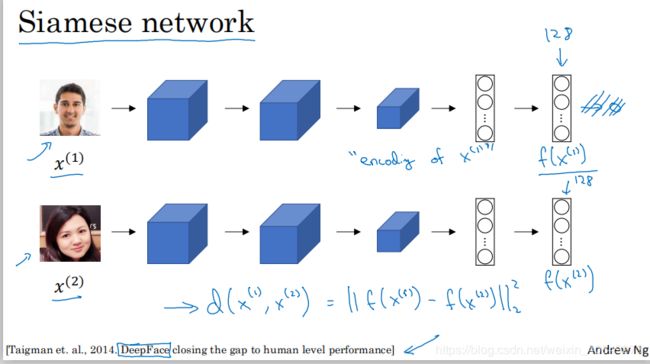
如上图所示,一般输入一张图片到卷积网络,最后是用softmax做分类。我们这里去除最后softmax部分,输入一张图片,最终得到一个128维的向量。如果我们把x(1)作为输入,那么这个向量用f(x(1))表示,也就是给x(1)编码了。
若我们用相同的神经网络并且权重相同,输入第二张图片x(2),最终得到f(x(2)),那么:
定义d(x(1),x(2))=f(x(1))与f(x(2))之间的范数。这也是两张图片之间的差别具体数值处理。
而这个网络结构也就是siamese网络,接下来的工作就是训练该网络学习参数。
总结:
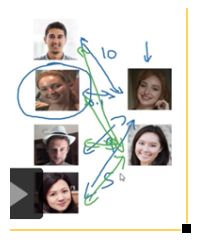
两边各个图片经过siamese编码,然后用范数计算图片之间的差值,若小于某阈值,则识别同一人,反之亦然。
siamese网络中的权重不可能随随便便给出,这就要通过训练获得。
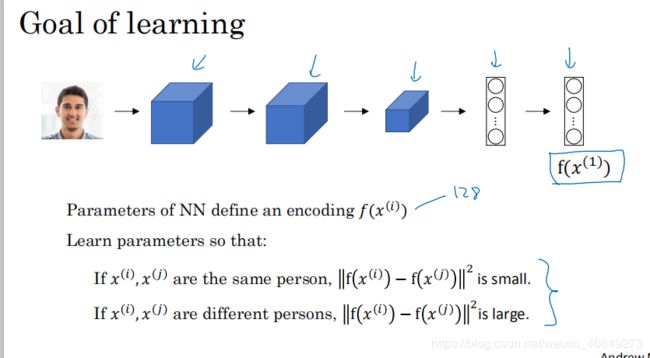
如上图所示,siamese网络的作用就是用于编码图片x(i),并且将该图片映射到一个128维度的向量。
要做的工作是训练该网络并且学习到参数,用来计算两张图片之间的差值,通过差值进行识别。
训练网络参数的目标:
输入数据集经行,使得输入两张图片,x(i),x(j)若两张图片是同一个人,则他们之间的范数很小,若两张图片不是同一个人,则他们之间的范数很大。不断经过训练满足该条件并且不断更新权重,最终训练整个网络。如果按着这个方向去训练,那么如果输入的图片和系统库里面的图片相像,那么他们之间的差别值(编码后对应的范数)就会很小,如果不相像,那么他们之间的差别值(编码后对应的范数)就会很大。
网络最终作用,当输入两张相同的图片,他们之间经过编码后的范数很小,当输入两张不同图片,他们之间经过编码后的范数很大。将该网络用于one-shot学习中的d函数,使得,当员工刷脸时,如若数据库中有该照片,则他们分别经过编码后的范数很小,如数据库中没有该照片,则他们分别经过编码后的范数很大。
也就是说,Siamese网络在人脸识别中,用于两边图片的编码,然后计算差值。
然后用训练好的siamese网络直接用于2中的one-shot学习。
训练好后的系统使用:
当输入一张新图片进去进行识别,系统会给该图片进行编码,也会给系统库中的图片进行编码,然后将新图片和系统库中的图片比较。因为系统是按着上面目标进行训练的,所以当系统库中的图片和输入的图片一致,他们之间计算出来的范数就会很小,当系统可中的图片和输入的图片冲突,他们之间计算出来的范数就会很大,我们可以根据这个范数进行人脸识别,当这个范数小于我们给定的阈值时,两张图片匹配,刷脸成功,当这个范数大于我们给定的阈值时,刷脸失败。
4、Triplet损失
(用于训练以上网络权重)要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。

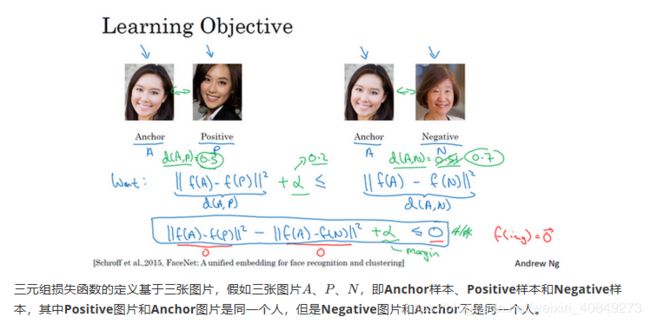
我们看下这是什么意思,为了应用三元组损失函数,你需要比较成对的图像,比如这个图片,为了学习网络的参数,你需要同时看几幅图片,比如这对图片(编号1和编号2),你想要它们的编码相似,因为这是同一个人。然而假如是这对图片(编号3和编号4),你会想要它们的编码差异大一些,因为这是不同的人。
用三元组损失的术语来说,你要做的通常是看一个 Anchor 图片,你想让Anchor图片和Positive图片(Positive意味着是同一个人)的距离很接近。然而,当Anchor图片与Negative图片(Negative意味着是非同一个人)对比时,你会想让他们的距离离得更远一点。

这就是为什么叫做三元组损失,它代表你通常会同时看三张图片,你需要看Anchor图片、Postive图片,还有Negative图片,我要把Anchor图片、Positive图片和Negative图片简写成A、P、N。

现在我要对这个表达式做一些小的改变,有一种情况满足这个表达式,但是没有用处,就是把所有的东西都学成0,如果总是输出0,即0-0≤0,这就是0减去0还等于0,如果所有图像的都是一个零向量,那么总能满足这个方程。所以为了确保网络对于所有的编码不会总是输出0,也为了确保它不会把所有的编码都设成互相相等的。另一种方法能让网络得到这种没用的输出,就是如果每个图片的编码和其他图片一样,这种情况,你还是得到0-0。
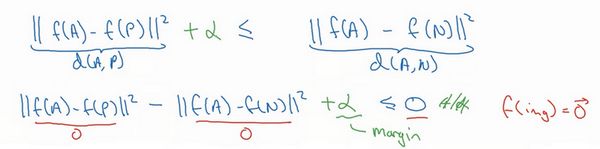
为了阻止网络出现这种情况,我们需要修改这个目标,也就是,这个不能是刚好小于等于0,应该是比0还要小,


另一方面如果这个![]() 大于0,然后你取它们的最大值,最终你会得到绿色下
大于0,然后你取它们的最大值,最终你会得到绿色下
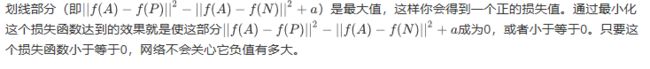
-------------------------------------------------------------------------------------------------------------



![]() 如果A和N是随机选择的不同的人,有很大
如果A和N是随机选择的不同的人,有很大
的可能性![]() 么。
么。

也就是说,我们的网络结构使得比较接近两张图片的都能分辨出来,那么差别比较大图片的更加容易分辨出来。
如果你对此感兴趣的话,这篇论文中有更多细节,作者是Florian Schroff, Dmitry Kalenichenko, James Philbin,他们建立了这个叫做FaceNet的系统,我视频里许多的观点都是来自于他们的工作。
• Florian Schroff, Dmitry Kalenichenko, James Philbin (2015). FaceNet: A Unified Embedding forFace Recognition and Clustering
--------------------------------------------------------------------------------------------------------------------------------
总结一下,训练这个三元组损失你需要取你的训练集,然后把它做成很多三元组,这就是一个三元组(编号1),有一个Anchor图片和Positive图片,这两个(Anchor和Positive)是同一个人,还有一张另一个人的Negative图片。这是另一组(编号2),其中Anchor和Positive图片是同一个人,但是Anchor和Negative不是同一个人,等等。

定义了这些包括A、P和N图片的数据集之后,你还需要做的就是用梯度下降最小化我们之前定义的代价函数J,这样做的效果就是反向传播到网络中的所有参数来学习到一种编码,使得如果两个图片是同一个人,那么它们的d就会很小,如果两个图片不是同一个人,它们的 就会d很大。这也就符合3中最后一段话中的目标。
这就是三元组损失,并且如何用它来训练网络输出一个好的编码用于人脸识别。现在的人脸识别系统,尤其是大规模的商业人脸识别系统都是在很大的数据集上训练,超过百万图片的数据集并不罕见,一些公司用千万级的图片,还有一些用上亿的图片来训练这些系统。这些是很大的数据集,即使按照现在的标准,这些数据集并不容易获得。幸运的是,一些公司已经训练了这些大型的网络并且上传了模型参数。所以相比于从头训练这些网络,在这一领域,由于这些数据集太大,这一领域的一个实用操作就是下载别人的预训练模型,而不是一切都要从头开始。但是即使你下载了别人的预训练模型,我认为了解怎么训练这些算法也是有用的,以防针对一些应用你需要从头实现这些想法。
这就是三元组损失,下个视频中,我会给你展示Siamese网络的一些其他变体,以及如何训练这些网络,让我们进入下个视频吧。
5、人脸验证与二分类
Triplet loss是一个学习人脸识别卷积网络参数的好方法,还有其他学习参数的方法,让我们看看如何将人脸识别当成一个二分类问题。
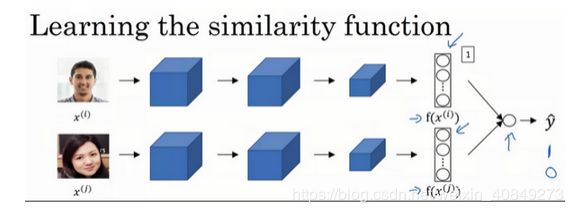
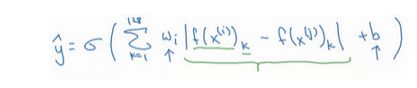
另一个训练神经网络的方法是选取一对神经网络,选取Siamese网络,使其同时计算这些嵌入,比如说128维的嵌入(编号1),或者更高维,然后将其输入到逻辑回归单元,然后进行预测,如果是相同的人,那么输出是1,若是不同的人,输出是0。这就把人脸识别问题转换为一个二分类问题,训练这种系统时可以替换Triplet loss的方法。


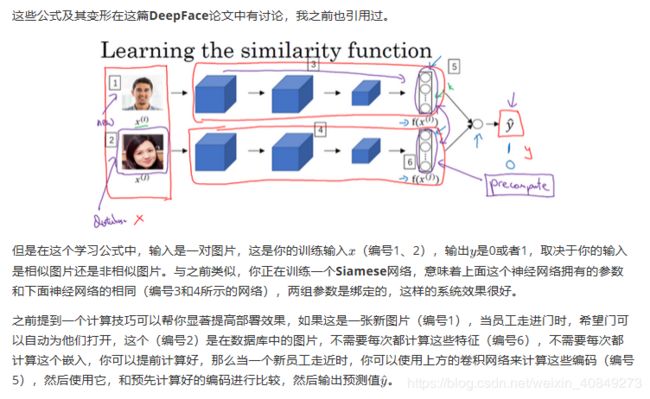
因为不需要存储原始图像,如果你有一个很大的员工数据库,你不需要为每个员工每次都计算这些编码。这个预先计算的思想,可以节省大量的计算,这个预训练的工作可以用在Siamese网路结构中,将人脸识别当作一个二分类问题,也可以用在学习和使用Triplet loss函数上,我在之前的视频中描述过。
总结一下,把人脸验证当作一个监督学习,创建一个只有成对图片的训练集,不是三个一组,而是成对的图片,目标标签是1表示一对图片是一个人,目标标签是0表示图片中是不同的人。利用不同的成对图片,使用反向传播算法去训练神经网络,训练Siamese神经网络。

这个你看到的版本,处理人脸验证和人脸识别扩展为二分类问题,这样的效果也很好。我希望你知道,在一次学习时,你需要什么来训练人脸验证,或者人脸识别系统。
总结:
二分类和4中训练方式有何区别:
同:
1、网络中两个卷积的权重相同。
2、都需要输入成组图片,不同的一个是每组两个,一个是每组3个。
3、训练网络还是需要通过反向传播去跟新权重,都需要优化损失函数。
异:
1、4中训练完比较两张图片需要和给定的阈值,再判断异同;二分类这个问题交给逻辑回归去处理了。
2、之前的是预测值与阈值比较,大于则判断两张图片一致,小于则不同;这里用预测值为1或者0去判断,为1则为一致,为0则为不同;两个其实有些相似,因为逻辑回归预测出来的值本来就是个概率。
6、神经风格转换
最近,卷积神经网络最有趣的应用是神经风格迁移,在编程作业中,你将自己实现这部分并创造出你的艺术作品。
什么是神经风格迁移?让我们来看几个例子,比如这张照片,照片是在斯坦福大学拍摄的,离我的办公室不远,你想利用右边照片的风格来重新创造原本的照片,右边的是梵高的星空,神经风格迁移可以帮你生成下面这张照片。

这仍是斯坦福大学的照片,但是用右边图像的风格画出来。
为了描述如何实现神经网络迁移,我将使用C来表示内容图像,S表示风格图像G,表示生成的图像。

另一个例子,比如,这张图片,C代表在旧金山的金门大桥,还有这张风格图片,是毕加索的风格,然后把两张照片结合起来,得到G这张毕加索风格的的金门大桥。
这页中展示的例子,是由Justin Johnson制作,在下面几个视频中你将学到如何自己生成这样的图片。
为了实现神经风格迁移,你需要知道卷积网络提取的特征,在不同的神经网络,深层的、浅层的。在深入了解如何实现神经风格迁移之前,我将在下一个视频中直观地介绍卷积神经网络不同层之间的具体运算,让我们来看下一个视频。
7、 深度卷积网络在做什么
深度卷积网络到底在学什么?在这个视频中我将展示一些可视化的例子,可以帮助你理解卷积网络中深度较大的层真正在做什么,这样有助于理解如何实现神经风格迁移。

来看一个例子,假如你训练了一个卷积神经网络,是一个Alexnet,轻量级网络,你希望将看到不同层之间隐藏单元的计算结果。

你可以这样做,从第一层的隐藏单元开始,假设你遍历了训练集,然后找到那些使得单元激活最大化的一些图片,或者是图片块。换句话说,将你的训练集经过神经网络,然后弄明白哪一张图片最大限度地激活特定的单元。注意在第一层的隐藏单元,只能看到小部分卷积神经,如果要画出来哪些激活了激活单元,只有一小块图片块是有意义的,因为这就是特定单元所能看到的全部。你选择一个隐藏单元,发现有9个图片最大化了单元激活,你可能找到这样的9个图片块(编号1左边9个),似乎是图片浅层区域显示了隐藏单元所看到的,找到了像这样的边缘或者线(编号2),这就是那9个最大化地激活了隐藏单元激活项的图片块。(也就是说,数据集中有9个图片块激活了编号2中的单元线条,2也相当于一个隐藏单元,我们把它可视化了)。

然后你可以选一个另一个第一层的隐藏单元,重复刚才的步骤,这是另一个隐藏单元,似乎第二个由这9个图片块(编号1)组成。看来这个隐藏单元在输入区域,寻找这样的线条(编号2),我们也称之为接受域。(数据集中找到编号1中右边9个图片块,激活了编号2中的线条,编号2也相当于一个隐藏单元,我们把它可视化了)。

对其他隐藏单元也进行处理,会发现其他隐藏单元趋向于激活类似于这样的图片。这个似乎对垂直明亮边缘左边有绿色的图片块(编号1)感兴趣,这一个隐藏单元倾向于橘色,这是一个有趣的图片块(编号2),红色和绿色混合成褐色或者棕橙色,但是神经元仍可以激活它。

以此类推,这是9个不同的代表性神经元,每一个不同的图片块都最大化地激活了。你可以这样理解,第一层的隐藏单元通常会找一些简单的特征,比如说边缘或者颜色阴影。(我们通过右边9*9个色块激活了影藏层的9个神经单元,寻找到了一些最简单的特征)。
Zeiler M D, Fergus R.Visualizing and Understanding Convolutional Networks[J]. 2013, 8689:818-833.)本节例子出自该论文

但如果我们重复这一过程,这(Layer 1所示图片)是之前第一层得到的,这个(Layer 2所示图片)是可视化的第2层中最大程度激活的9个隐藏单元。我想解释一下这个可视化,这是(编号2所示)使一个隐藏单元最大激活的9个图片块,每一个组合,这是另一组(编号2),使得一个隐藏单元被激活的9个图片块,这个可视化展示了第二层的9个隐藏单元,每一个又有9个图片块使得隐藏单元有较大的输出或是较大的激活。(第二个隐藏层的9个单元同理被layer2中的对应图片激活,这也就提取出了更好的特征)。

在更深的层上,你可以重复这个过程。
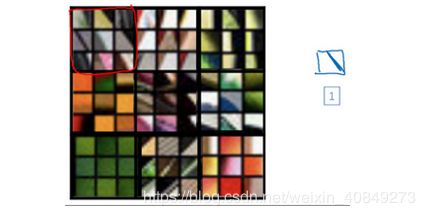
在这页里很难看清楚,这些微小的浅层图片块,让我们放大一些,这是第一层,这是第一个被高度激活的单元(对应编号1),你能在输入图片的区域看到,大概是这个角度的边缘(编号1)放大第二层的可视化图像。

有意思了,第二层似乎检测到更复杂的形状和模式,比如说这个隐藏单元(编号1),它会找到有很多垂线的垂直图案,这个隐藏单元(编号2)似乎在左侧有圆形图案时会被高度激活,这个的特征(编号3)是很细的垂线,以此类推,第二层检测的特征变得更加复杂。
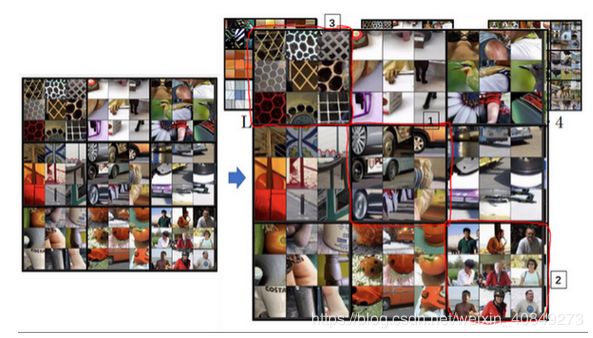
看看第三层我们将其放大,放得更大一点,看得更清楚一点,这些东西激活了第三层。再放大一点,这又很有趣了,这个隐藏单元(编号1)似乎对图像左下角的圆形很敏感,所以检测到很多车。这一个(编号2)似乎开始检测到人类,这个(编号3)似乎检测特定的图案,蜂窝形状或者方形,类似这样规律的图案。有些很难看出来,需要手动弄明白检测到什么,但是第三层明显,检测到更复杂的模式。

下一层呢?这是第四层,检测到的模式和特征更加复杂,这个(编号1)学习成了一个狗的检测器,但是这些狗看起来都很类似,我并不知道这些狗的种类,但是你知道这些都是狗,他们看起来也类似。第四层中的这个(编号2)隐藏单元它检测什么?水吗?这个(编号3)似乎检测到鸟的脚等等。

第五层检测到更加复杂的事物,注意到这(编号1)也有一个神经元,似乎是一个狗检测器,但是可以检测到的狗似乎更加多样性。这个(编号2)可以检测到键盘,或者是键盘质地的物体,可能是有很多点的物体。我认为这个神经元(编号3)可能检测到文本,但是很难确定,这个(编号4)检测到花。我们已经有了一些进展,从检测简单的事物,比如说,第一层的边缘,第二层的质地,到深层的复杂物体。
我希望这让你可以更直观地了解卷积神经网络的浅层和深层是如何计算的,接下来让我们使用这些知识开始构造神经风格迁移算法。
总而言之:也就是提取特征从简单到复杂的过程,最终提取出完整对象(如猫,狗等);而提取特征所需要的图片,也是从简单到复杂的过程(如开始只是一些斜线,提取出斜线的特征,后来斜线特征又能提取出更复杂的特征,最终提取出整个完整对象),而这些所需要的图片,最初是从训练集而来。
8、代价函数
要构建一个神经风格迁移系统,让我们为生成的图像定义一个代价函数,你接下看到的是,通过最小化代价函数,你可以生成你想要的任何图像。

记住我们的问题,给你一个内容图像C,给定一个风格图片S,而你的目标是生成一个新图片G。为了实现神经风格迁移,你要做的是定义一个关于G的代价函数J用来评判某个生成图像的好坏,我们将使用梯度下降法去最小化J(G),以便于生成这个图像。
怎么判断生成图像的好坏呢?我们把这个代价函数定义为两个部分。
![]()
第一部分被称作内容代价,这是一个关于内容图片和生成图片的函数,它是用来度量生成图片G的内容与内容图片C的内容有多相似。
![]()
然后我们会把结果加上一个风格代价函数,也就是关于S和G的函数,用来度量图片G的风格和图片S的风格的相似度。
![]()

艾尔法与贝尔塔用来条件而生成的图片G倾向于像C还是S.
关于神经风格迁移算法我将在接下来几段视频中展示的,是基于Leon Gatys, Alexandra Ecker和Matthias Bethge的这篇论文。这篇论文并不是很难读懂,如果你愿意,看完这些视频,我也非常推荐你去看看他们的论文。
Leon A. Gatys, Alexander S. Ecker, Matthias Bethge, (2015). A Neural Algorithm of Artistic Style (https://arxiv.org/abs/1508.06576)
算法的运行是这样的,对于代价函数J(G),为了生成一个新图像,你接下来要做的是随机初始化生成图像G,它可能是100×100×3,可能是500×500×3,又或者是任何你想要的尺寸。



在这段视频中你看到了神经风格迁移算法的概要,定义一个生成图片G的代价函数,并将其最小化。接下来我们需要了解怎么去定义内容代价函数和风格代价函数,让我们从下一个视频开始学习这部分内容吧。
9、内容代价函数
(关于怎么定义代价函数,具体是怎么去训练的)
首先来看公式:

风格迁移网络的代价函数有一个内容代价部分,还有一个风格代价部分。
我们先定义内容代价部分,不要忘了这就是我们整个风格迁移网络的代价函数,我们看看内容代价函数应该是什么。