带你走进MyBatis的源码世界
前言
MyBatis的架构及运行流程已在《自己手动仿写MyBatis框架完整版》一文中详细说明,就不再过多赘述。本文根据MyBatis 3.4.6版本进行阐述,下面直接进入MyBatis的源码世界。
一、配置简介
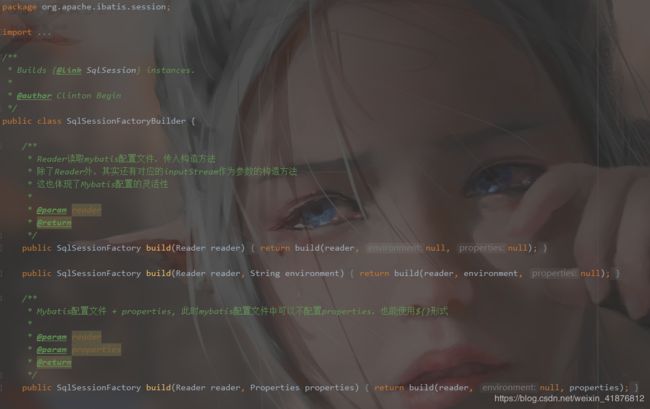
既然MyBatis是以SqlSessionFactoryBuilder去创建SqlSessionFactory,那我们就以SqlSessionFactoryBuilder类为突破口,进入MyBatis的源码世界。

![]()
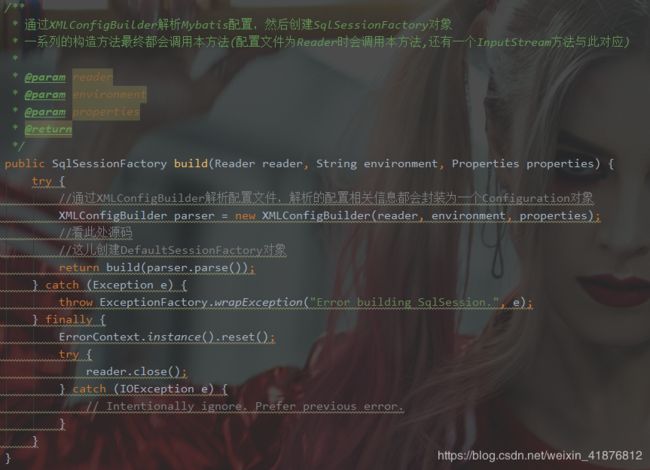
SqlSessionFactoryBuilder通过XMLConfigBuilder去解析我们传入的mybatis的配置文件,接下来我们看看XMLConfigBuilder部分源码:



通过这段源码,我们可以看出在MyBatis的配置文件中:
1、configuration为根节点
2、其下有十个子节点:properties(属性)、settings(全局配置参数)、typeAliases(类型别名)、plugins(插件)、objectFactory(对象工厂)、objectWrapperFactory、reflectorFactory、environments(环境集合属性对象)、databaseIdProvider、typeHandlers(类型处理器)、mappers(映射器)
接下来我们围绕着这十个子节点中比较重要的几个逐个解析。
二、properties
先上两种properties的配置方式:
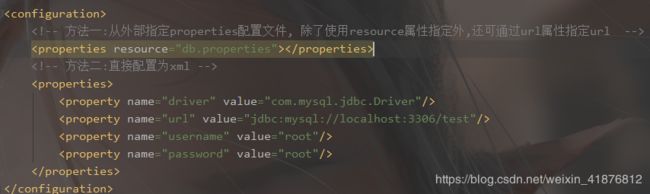
试问:如果以上两种方式都进行了配置,那么是哪种方试优先呢?
接下来我们去源码中一探究竟。
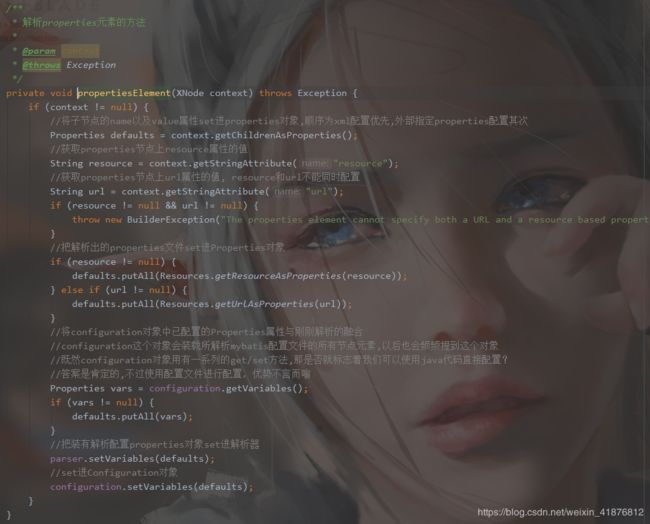
通过源码,不难看出,如若两种方式均配置,则以在xml文件直接配置的方式优先。
三、settings
该配置会改变MyBatis的运行行为,本篇不做源码详解,只阐述功能。下列是关于setttings完整的配置,可以简单了解下。
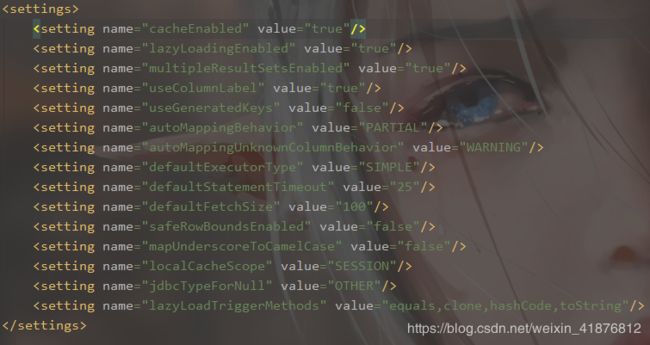
配置的说明详见下表:
| 设置参数 | 描述 | 有效值 | 默认值 |
| cacheEnabled | 该配置影响的所有映射器中配置的缓存的全局开关。 | true | false | true |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置fetchType属性来覆盖该项的开关状态。 | true | false | false |
| aggressiveLazyLoading | 当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载(参考lazyLoadTriggerMethods) | true | false | false |
| multipleResultSetsEnabled | 是否允许单一语句返回多结果集(需要兼容驱动) | true | false | true |
| useColumnLabel | 使用列标签代替列名。不同的驱动在这方面会有不同的表现, 具体可参考相关驱动文档或通过测试这两种不同的模式来观察所用驱动的结果。 | true | false | true |
| useGeneratedKeys | 允许 JDBC 支持自动生成主键,需要驱动兼容。 如果设置为 true 则这个设置强制使用自动生成主键,尽管一些驱动不能兼容但仍可正常工作(比如 Derby) | true | false | false |
| autoMappingBehavior | 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示取消自动映射;PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集。 FULL 会自动映射任意复杂的结果集(无论是否嵌套)。 | NONE, PARTIAL, FULL | PARTIAL |
| autoMappingUnknownColumnBehavior | 指定发现自动映射目标未知列(或者未知属性类型)的行为。 NONE: 不做任何反应 WARNING: 输出提醒日志 (‘org.apache.ibatis.session.AutoMappingUnknownColumnBehavior’ 的日志等级必须设置为 WARN) FAILING: 映射失败 (抛出 SqlSessionException) |
NONE, WARNING, FAILING | NONE |
| defaultExecutorType | 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。 | SIMPLE REUSE BATCH | SIMPLE |
| defaultStatementTimeout | 设置超时时间,它决定驱动等待数据库响应的秒数。 | 任意正整数 | Not Set (null) |
| defaultFetchSize | 为驱动的结果集获取数量(fetchSize)设置一个提示值。此参数只可以在查询设置中被覆盖。 | 任意正整数 | Not Set (null) |
| safeRowBoundsEnabled | 允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为false。 | true | false | false |
| safeResultHandlerEnabled | 允许在嵌套语句中使用分页(ResultHandler)。如果允许使用则设置为false。 | true | false | true |
| mapUnderscoreToCamelCase | 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。 | true | false | false |
| localCacheScope | MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据。 | SESSION | STATEMENT | SESSION |
| jdbcTypeForNull | 当没有为参数提供特定的 JDBC 类型时,为空值指定 JDBC 类型。 某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。 |
jdcType枚举。最常见的是:NULL、VARCHAR等。 |
OTHER |
| lazyLoadTriggerMethods | 指定哪个对象的方法触发一次延迟加载。 | 用逗号分隔的方法名称列表 | equals,clone,hashCode,toString |
| defaultScriptingLanguage | 指定动态 SQL 生成的默认语言。 | 类型别名或完全限定类名。 | org.apache.ibatis.scripting.xmltags.XMLLanguageDriver |
| defaultEnumTypeHandler | 指定默认情况下枚举处理器的枚举句柄。(从3.4.5开始) | 类型别名或完全限定类名。 | org.apache.ibatis.type.EnumTypeHandler |
| callSettersOnNulls | 指定当结果集中值为 null 的时候是否调用映射对象的 setter(map 对象时为 put)方法,这对于有 Map.keySet() 依赖或 null 值初始化的时候是有用的。注意基本类型(int、boolean等)是不能设置成 null 的。 | true | false | false |
| returnInstanceForEmptyRow | 当返回行的所有列都是空时,MyBatis默认返回null。 当开启这个设置时,MyBatis会返回一个空实例。 请注意,它也适用于嵌套的结果集 (i.e. collectioin and association)。(从3.4.2开始) | true | false | false |
| logPrefix | 指定 MyBatis 增加到日志名称的前缀。 | 任何String | Not set |
| logImpl | 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。 | SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING | Not set |
| proxyFactory | 指定 Mybatis 创建具有延迟加载能力的对象所用到的代理工具。 | CGLIB | JAVASSIST | JAVASSIST |
| vfsImpl | 指定VFS的实现 | 自定义VFS的实现的类全限定名,以逗号分隔。 | Not set |
| useActualParamName | 允许使用方法签名中的名称作为语句参数名称。 为了使用该特性,你的工程必须采用Java 8编译,并且加上-parameters选项。(从3.4.1开始) | true | false | true |
| configurationFactory | 指定一个提供Configuration实例的类。这个被返回的Configuration实例是用来加载被反序列化对象的懒加载属性值。这个类必须包含一个签名方法static Configuration getConfiguration()。(从 3.2.3 版本开始) | 类型别名或完全限定类名。 | Not set |
四、typeAliases
通俗点来说,这个配置的作用就是给实体类起别名,让我们做引用时不必再写类的全限定名。
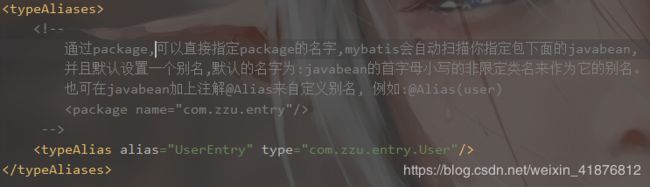
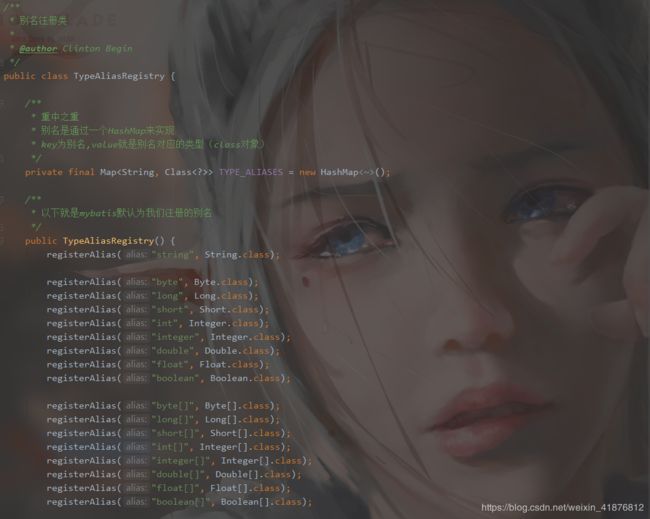
下面我们看看源码。

重要的源码在下面。




五、plugins
拦截器配置,只要和请求/响应有关的都可以使用拦截器进行一些自定义处理。

六、ObjectFactory
自定义ObjectFactory只需要去继承DefaultObjectFactory(是ObjectFactory接口的实现类),并重写其方法即可。
写好了ObjectFactory, 仅需做如下配置:

接下来我们看看源码。

七、environments

为什么environments可以配置多个environment节点呢?意义何在?
正如我们所知,我们软件开发的生命周期是从测试环境转到生产环境的,为了方便我们快速切换两个环境,故配置两套environment,在environments的default属性配置当前采用哪套environments的id即可。
接下来我们看源码具体是怎么实现此功能的。

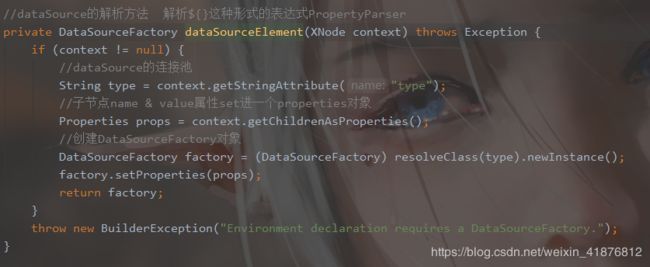
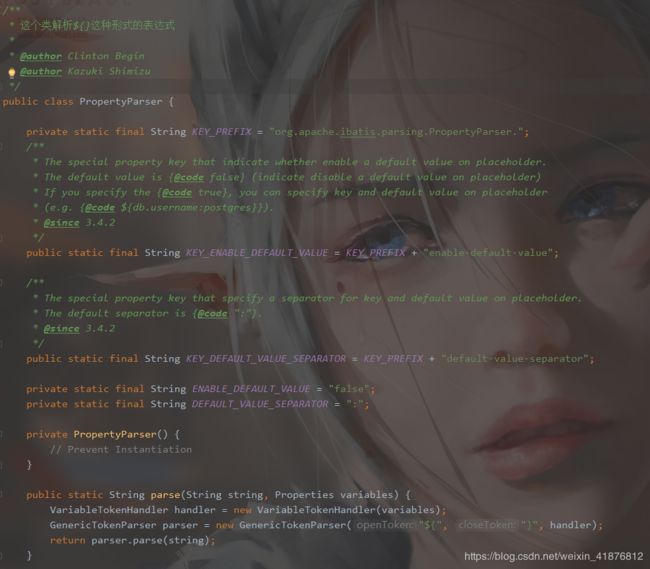
我们刚才看到value属性配置的值为${driver},那么这种方式是怎么解析的呢?分析源码,原来是在PropertyParser中解析的。
八、databaseIdProvider
MyBatis可以根据不同的数据库厂商执行不同的语句 ,这种多厂商的支持是基于映射语句中的databaseId属性。MyBatis会加载不带databaseId属性和带有匹配当前数据库databaseId属性的所有语句。如果同时找到带有databaseId 和不带 databaseId 的相同语句,则后者会被舍弃。为支持多厂商特性只要像下面这样在mybatis-config.xml文件中加入databaseIdProvider 即可:![]()
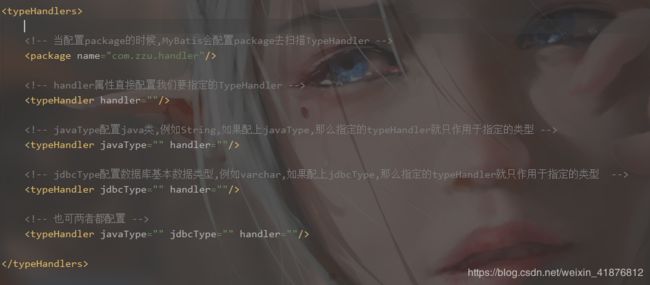
九、typeHandlers
用一句话介绍就是,MyBatis使用typeHandlers类型处理器完成jdbc类型和java类型的转换。
我们先看看他是怎么配置的。
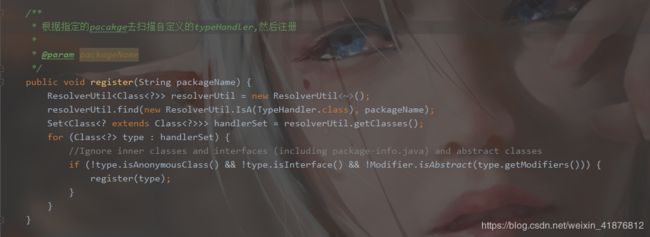
那MyBatis为我们提供哪些typeHandler呢,让我们去源码中找寻的答案。


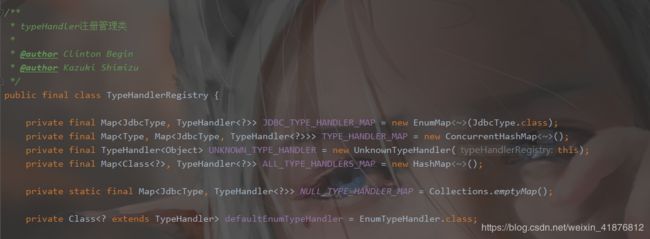
不不不,这只是它的解析方法,下面我们看看它的注册管理类。我只截取几段重要的代码。




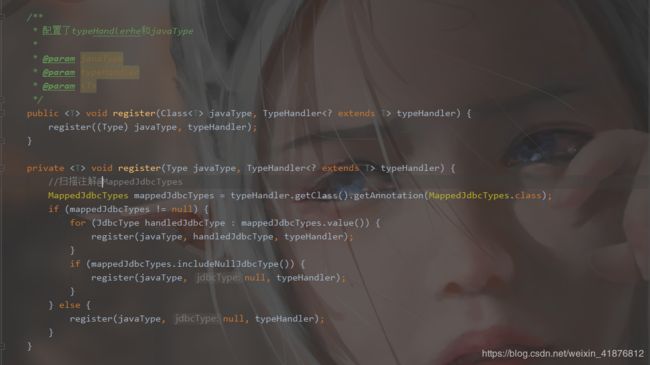
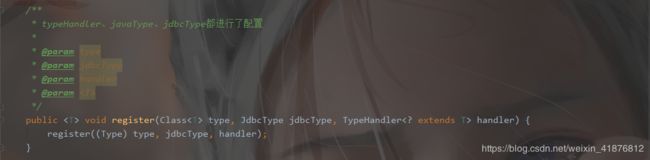
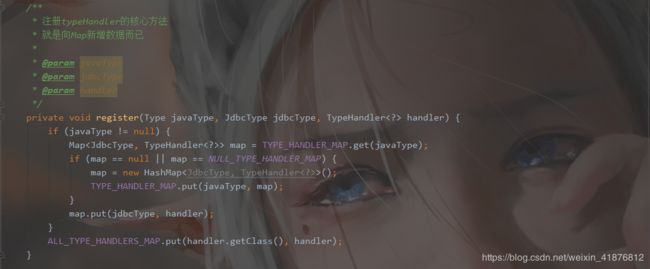

我们看完了typeHandler的源码,那么我们能不能自定义typeHandler呢?
答案是必须的,我们随意点开几个typeHandler,会发现他们都继承了BaseTypeHandler,那我们可以模仿MyBatis通过继承BaseTypeHandler来自定义typeHandler。但是这里就不过多介绍了,我将在文章末尾为大家演示自动定义的typeHandler。/手动滑稽
十、mappers
mapper文件可以说是MyBatis的核心文件之一了,它是数据库与javaBean之间的桥梁。
我们首先看mapper的配置文件,一共有四种加载方式。
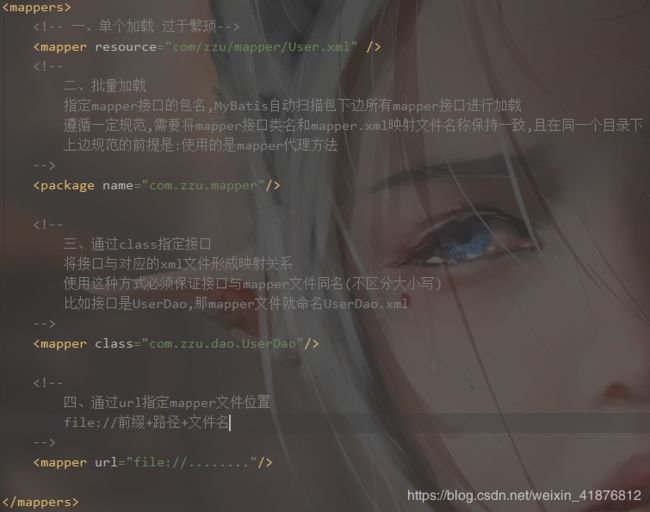
接下来我们看解析mappers的源码。
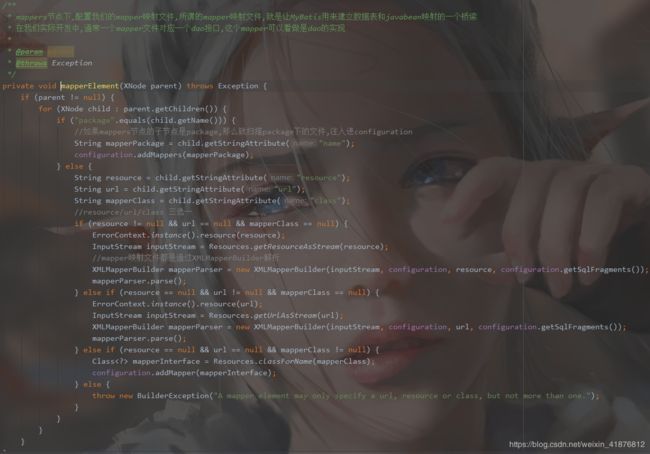
十一、mapper文件的具体内容
1、结构

最外层的当然是mapper元素,mapper中有如下元素:
cache – 给定命名空间的缓存配置。
cache-ref – 其他命名空间缓存配置的引用。
resultMap – 是最复杂也是最强大的元素, 用来描述如何从数据库结果集中来加载对象。
parameterMap – 已废弃!老式风格的参数映射。 内联参数是首选,这个元素可能在将来被移除, 这里不会记录。
sql – 可被其他语句引用的可重用语句块。
insert – 映射插入语句
update – 映射更新语句
delete – 映射删除语句
select – 映射查询语句
2、select
1)介绍
通过select元素执行数据库查询,以下属性会经常用到:
id:标志映射文件中的sql,将sql语句封装到mappedStatement对象中,所以id称为statement的id。
parameterType:指定输入参数的类型。
resultType:select指定resultType表示为输出结果中单条记录映射成的java对象,多条记录也只指定单条记录映射成的java对象。

我这里虽然用了*,但是实际开发中千万不要用*。不多解释,大家都懂。
#{}表示一个占位符,#{id}中的id表示接收输入的参数,参数名称就是id,如果输入的参数就是简单类型,#{}中的参数名可以任意命名,可以value或其它名称。
这里有一个点,# / $都可以用以上的方式,但是是有区别的。使用#的方式底层的实现采用的是PreparedStatement,而$的方式底层采用的是Statement。看到这两个类我们就能知道为什么使用#而不是$了吧.#也就是PreparedStatement可以防止sql注入的风险。什么是sql注入?请自行百度。。。/再次手动滑稽
2)属性
select标签中所有可以设置的属性:
| 属性 | 描述 |
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 |
| parameterType | 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为MyBatis可以通过TypeHandler推断出具体传入语句的参数,默认值为 unset。 |
| resultType | 从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用 resultType 或 resultMap,但不能同时使用。 |
| resultMap | 外部resultMap的命名引用。结果集的映射是MyBatis最强大的特性,对其有一个很好的理解的话,许多复杂映射的情形都能迎刃而解。使用resultMap或resultType,但不能同时使用。 |
| flushCache | 将其设置为true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false。 |
| useCache | 将其设置为true,将会导致本条语句的结果被二级缓存,默认值:对select元素为true。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为unset(依赖驱动)。 |
| fetchSize | 这是尝试影响驱动程序每次批量返回的结果行数和这个设置值相等。默认值为unset(依赖驱动)。 |
| statementType | STATEMENT,PREPARED或CALLABLE的一个。这会让MyBatis分别使用Statement,PreparedStatement或CallableStatement,默认值:PREPARED。 |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE或SCROLL_INSENSITIVE中的一个,默认值为 unset(依赖驱动)。 |
| databaseId | 如果配置了databaseIdProvider,MyBatis会加载所有的不带databaseId或匹配当前databaseId的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
| resultOrdered | 这个设置仅针对嵌套结果select语句适用:如果为 true,就是假设包含了嵌套结果集或是分组了,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false。 |
| resultSets | 这个设置仅对多结果集的情况适用,它将列出语句执行后返回的结果集并每个结果集给一个名称,名称是逗号分隔的。 |
3、insert/delete/update
1)介绍
通过insert/delete/update标签对数据库增、删、改。
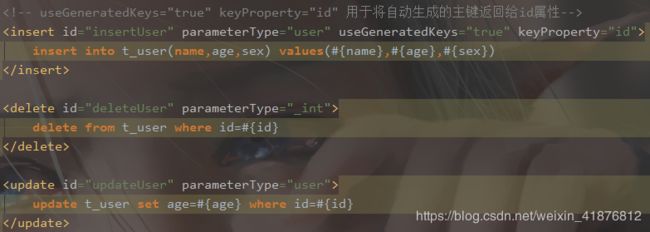
对于insert/delete/update操作时,因为涉及到数据库的变动,应该注意事物的提交,否则会失效。
提交语句:sqlSession.commit();
2)属性
| 属性 | 描述 |
| id | 命名空间中的唯一标识符,可被用来代表这条语句。 |
| parameterType | 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为MyBatis可以通过TypeHandler推断出具体传入语句的参数,默认值为 unset。 |
| flushCache | 将其设置为true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true(对应插入、更新和删除语句)。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为unset(依赖驱动)。 |
| statementType | STATEMENT,PREPARED或CALLABLE的一个。这会让MyBatis分别使用 Statement,PreparedStatement或CallableStatement,默认值:PREPARED。 |
| useGeneratedKeys | (仅对insert和update有用)这会令MyBatis使用JDBC的getGeneratedKeys方法来取出由数据库内部生成的主键(比如:像MySQL和SQL Server的关系数据库管理系统的自动递增字段),默认值:false。 |
| keyProperty | (仅对 insert 和 update 有用)唯一标记一个属性,MyBatis会通过getGeneratedKeys的返回值或者通过insert语句的selectKey子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| keyColumn | (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| databaseId | 如果配置了databaseIdProvider,MyBatis会加载所有的不带databaseId或匹配当前databaseId的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
4、sql
使用sql标签来定义可重用的sql代码段,用include标签引入sql代码段,简化冗余的代码。
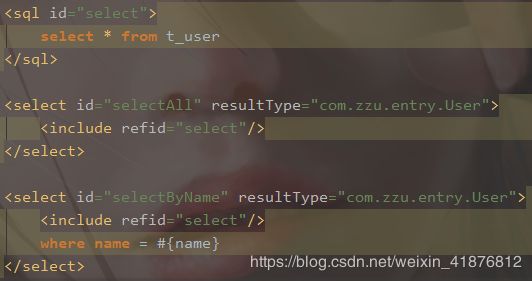
5、resultType/resultMap
1)介绍
resultType:使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。
①如果查询出来的列名和pojo中的属性名不一致,不会创建pojo对象。
②只要查询出来的列名和pojo中的属性有一个一致,则会创建pojo对象。
查询出来的结果只有一行且一列,才可以用简单类型进行输出映射。不管输出的pojo单个对象还是一个列表(list中包含pojo),在mapper.xml中指定的类型是一样的,都是pojo类型,在mapper.java指定的方法返回值类型不一样,一个是pojo类型,一个是List。
resultMap:如果查询出来的列名和pojo属性名不一致,我们则需要定义一个resultMap对列名和pojo属性名之间做一个映射关系。
①定义resultMap。
②使用resultMap作为statement的输出映射类型。
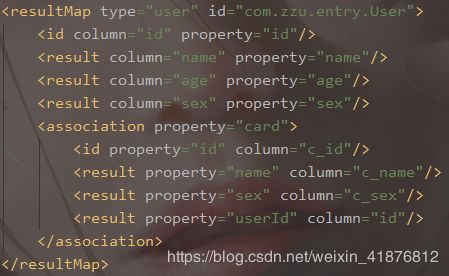
2)resultMap结构
constructor:类在实例化时,用来注入结果到构造方法中。
idArg:ID 参数,标记结果作为 ID 可以帮助提高整体效能。
arg:注入到构造方法的一个普通结果。
resultMap属性:指定定义的resultMap的id,如果这个resultMap在其它的mapper文件,前边需要加namespace。
resultMap元素:type属性是resultMap最终映射的java类型对象类型,可以使用别名,id属性是对resultMap的唯一标识。
id元素:表示查询结果集中的唯一标识。column是查询出来的列名,property是type指定的pojo类型中的字段名,最终resultMap对column和property做一个映射关系。
result元素:是对普通列映射定义。column是查询出来的列名,property是type指定的pojo类型中的字段名。
使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。如果查询出来的列名和pojo的属性名不一致,则需要定义一个resultMap对列名和pojo属性名之间做一个映射关系。
6、association
1)介绍
association标签处理表与表之间一对一的关系。
2)属性
| 属性 | 描述 |
| property | 映射到列结果的字段或属性。如果匹配的是存在的,和给定名称相同的property JavaBeans的属性,那么就会使用。否则 MyBatis 将会寻找给定名称的字段。这两种情形你可以使用通常点式的复杂属性导航。 |
| javaType | 一个Java类的完全限定名,或一个类型别名(参考上面内建类型别名的列表) 。如果你映射到一个JavaBean,MyBatis通常可以断定类型。然而,如javaType果你映射到的是HashMap。那么你应该明确地指定 javaType 来保证所需的行为。 |
| jdbcType | 在这个表格之前的所支持的JDBC类型列表中的类型。JDBC类型是仅仅需要对插入,更新和删除操作可能为空的列进行处理。这是JDBC的需要,jdbcType而不是 MyBatis 的。如果你直接使用JDBC编程,你需要指定这个类型。 |
| typeHandler | 我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的typeHandler。 |
关于对多个表的联合查询,mybatis提供两种方式来加载:
Nested Select:通过执行另一个返回预期复杂类型的映射sql语句。
Nested Results:通过嵌套结果映射来处理联接结果集(joined results)的重复子集。
7、collection
association标签处理表与表之间一对多的关系,collection元素的作用几乎和association是相同的,但他们的不同之处在于collection标签处理表与表之间多对多的关系。collection中多了ofType属性,这个属性用来区分与类的属性property,它代表的是集合属性中包含的类型。
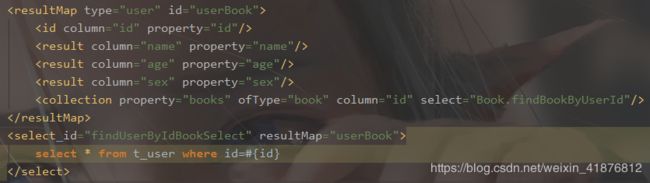
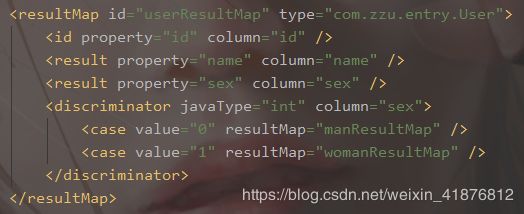
8、discriminator
实际生活中我们往往有一个基类,然后派生出一些类,这些派生类的属性具有一些差异。discriminator元素用来处理一条数据库查询可能会返回包括各种不同的数据类型的结果集,就像switch case语句,根据给定的值选取resultMap。
9、cache
1)介绍
MyBatis包含一个非常强大的查询缓存特性,可以非常方便地配置和定制。默认情况下是没有开启缓存的,除了局部的session缓存。要开启二级缓存,需要在 SQL 映射文件中添加一行:
![]()
这个简单语句的效果如下:
①映射语句文件中的所有select语句将会被缓存。
②映射语句文件中的所有insert、update、delete语句会刷新缓存。
③缓存会使用Least Recently Used(LRU,最近最少使用的)算法来收回。
④根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
⑤缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
⑥缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
2)属性
eviction:缓存的回收策略,默认的是LRU
LRU - 最近最少使用,移除最长时间不被使用的对象
FIFO - 先进先出,按对象进入缓存的顺序来移除它们
SOFT - 软引用,移除基于垃圾回收器状态和软引用规则的对象
WEAK - 弱引用,更积极地移除基于垃圾收集器和弱引用规则的对象
flushInterval:缓存刷新间隔,缓存多长时间清空一次,默认不清空,设置一个毫秒值
readOnly:是否只读
true:只读,mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。
作用: mybatis为了加快获取数据,直接就会将数据在缓存中的引用交给用户 。不安全,速度快
false:读写(默认):mybatis觉得获取的数据可能会被修改。
作用:mybatis会利用序列化&反序列化的技术克隆一份新的数据给你。安全,速度相对慢
size:缓存存放多少个元素
type:指定自定义缓存的全类名(实现Cache接口即可)
3)自定义缓存
只需要实现org.mybatis.cache.Cache接口,简单定义需要做什么处理,然后将
10、动态sql
1)if
根据if标签选择是否使用某个片段,类似于java中的if else语句。
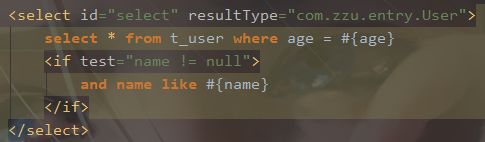
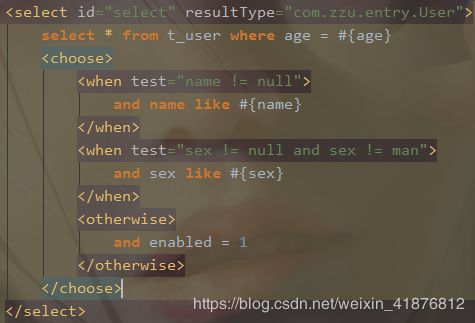
2)choose (when, otherwise)
如果不是每个片段都要被使用,我们只想使用多个中的一个片段,就需要choose语句实现多选一的效果。
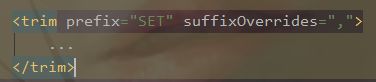
3)trim (where, set)
假如所有的条件都不满足或者第一个条件不满足,就会查询失败,因为多一个where或and。
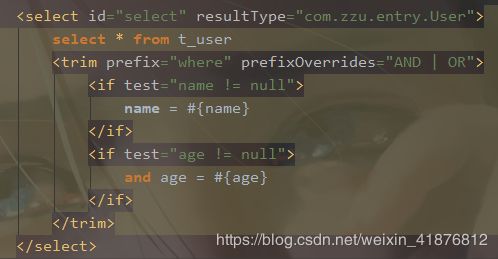
以上代码相当于数据库的where语句。
set标签可以被用于动态包含需要更新的列,而舍去其他的。
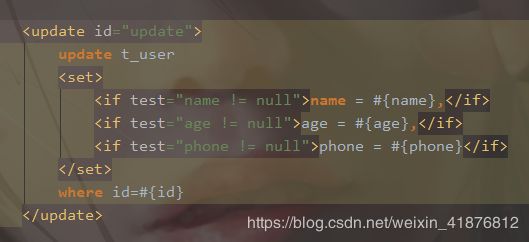
以上代码等同于下面。
4)foreach
对一个集合进行遍历,通常是在构建 IN 条件语句的时候,当使用可迭代对象或者数组时,index是当前迭代的次数,item的值是本次迭代获取的元素。当使用字典(或者Map.Entry对象的集合)时,index是键,item是值。

5)bind
使用繁琐,可以用其它标签代替,不过多叙述。
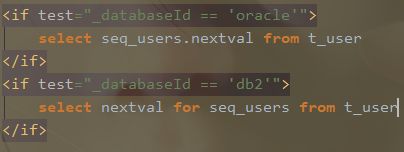
6)Multi-db vendor support
可用于对不同种数据库的sql语句的适配。
十二、一条sql的执行过程
先上一张图,让大家对sql执行过程有一个图形化的印象,然后我们再去追源码。
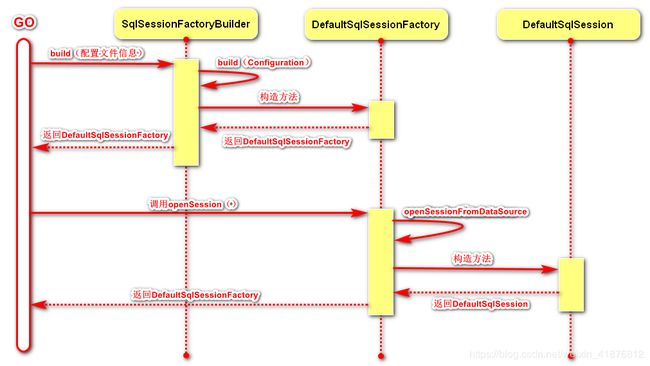
1、首先是SqlSessionFactoryBuilder读取MyBatis的配置文件,然后build一个DefaultSqlSessionFactory。可以简单理解为一个工人建造了一个工厂。

2、获取到SqlSessionFactory后,就可以进一步获取SqlSession对象。


3.当我们获取到SqlSession对象时,我们就可以为所欲为了。里面有一系列的增删查改以及事物方法供我们选择调用。但是大家有没有感觉少点啥?是的,我们的mapper文件跑哪了?看图。
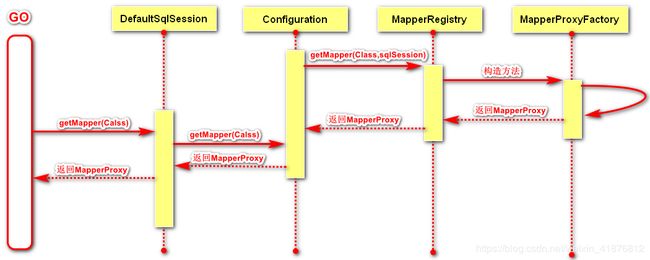
4.MyBatis为我们提供MapperProxy动态代理我们的dao,让我们看看源码中是怎么获取MapperProxy的吧。
通过SqlSession在Configuration中获取。

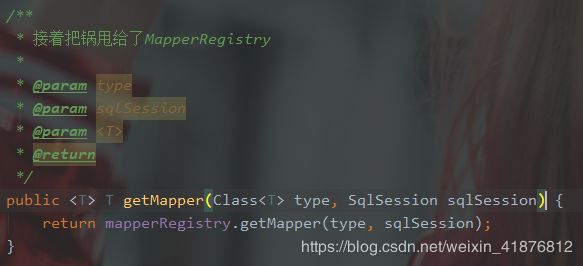
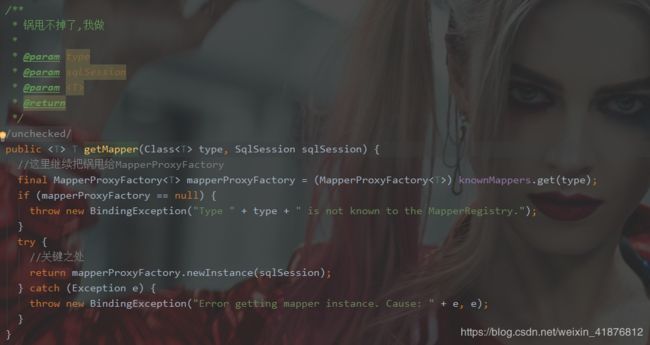
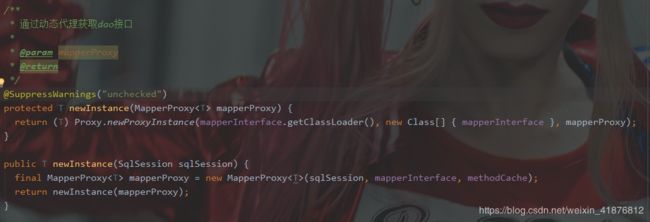
看过我们上面追的源码,我们可以分析以下数据流链路。
SqlSession → Configuration → MapperRegisry → MapperProxyFactory
5.下面让我们看看MyBatis具体怎么执行的sql。
前文中提到,执行sql的是Executor。老规矩,先上图看流程。

下面是sql执行的真正的过程。
我们刚才的数据流链路到了MapperProxy,拿到了一个dao,接下来我们看MapperProxy是怎么处理的。
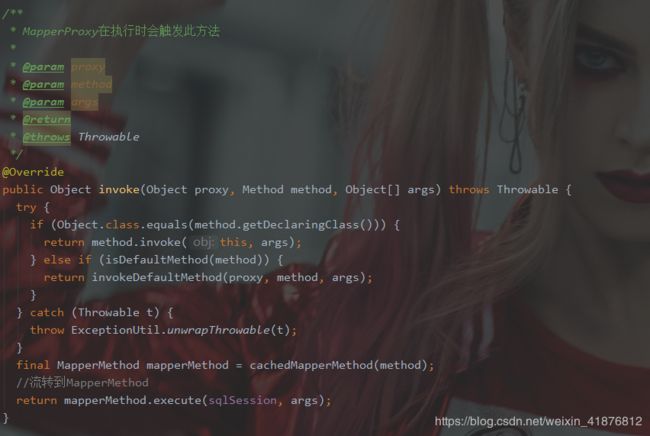
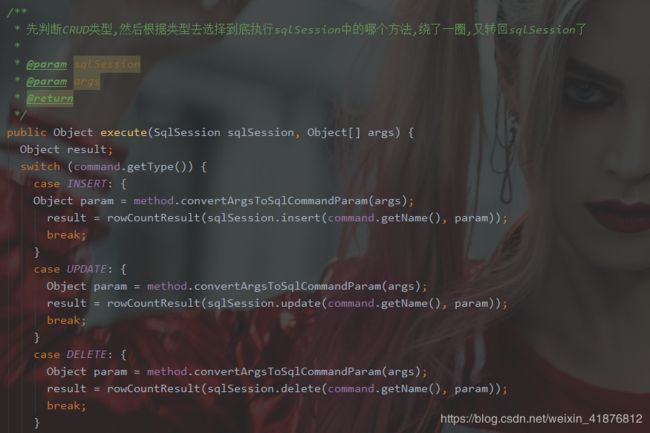
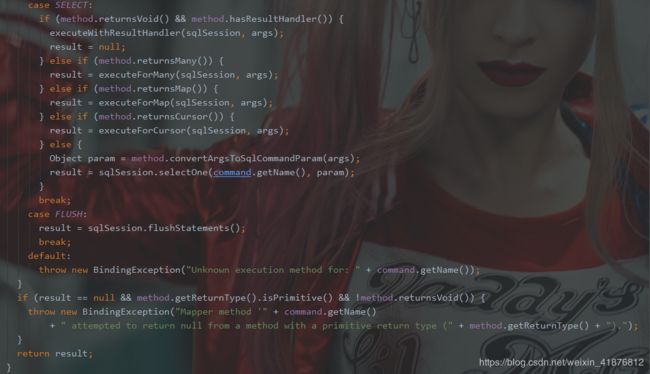
我们发现接下来的数据流链路如下:
MapperProxy → MapperMethod → SqlSession
原来数据绕了一圈又回去了,最终流转到了SqlSession,那我们就从SqlSession里随便挑一个方法进行接下来的追寻吧。
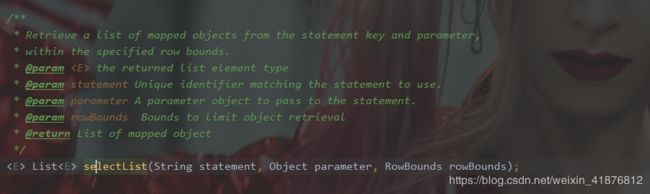
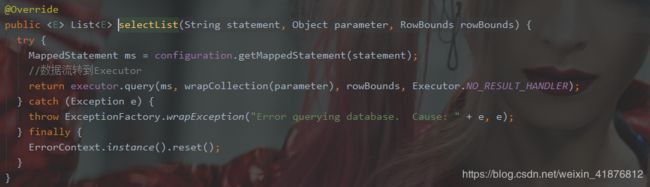
我们追寻selectList方法吧,发现数据流转到了Executor。Executor是一个接口,我们随便找一个它的实现类,就BaseExecutor吧。

发现这个方法流转是这样的:
query() → queryFromDatabase() → doQuery()
在BaseExecutor中,doQuery()竟然是个抽象的方法,于是接着找它的实现类,随便找个SimpleExecutor吧。

接着doQuery()实现中将数据交给StatementHandler处理,那我们就直接看它的一个实现类吧,也是我们开发中mapper映射文件使用的#的底层实现类。
StatementHandler → BaseStatementHandler → PreparedStatementHandler
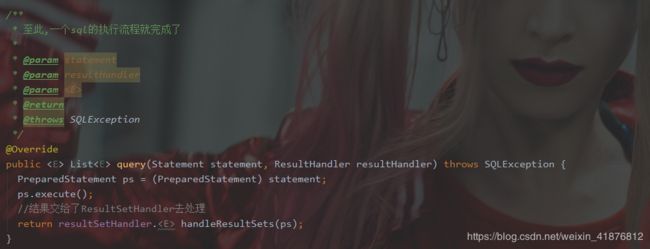
至此,一个sql的执行流程就彻底结束了。
寄语
作为一个涉行未深的程序猿,在计算机这一行,本体属性就相当于是沙漠。需要去吸收大量的知识源泉,来丰富优化自己贫瘠的土壤。这是我看的第一个开源框架的源码,也是最基础的一个框架。但是看完之后,感觉万物相通,其他框架的套路应该和这个相似。以后还是应该多看看源码,多学习学习优秀的人是怎么写代码的。把他们的套路学会,哪怕只是仿写,我相信自己的技术也会提升一个层面。我们是吃不起老本的手艺人啊,只有在代码之路上不断学习,才能走的更远。