kaggle项目—“泰坦尼克号生存率分析”
项目背景
1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员有1502人遇难。沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员。虽然幸存下来有一些运气因素,但有一些人比其他人更有可能生存,在本项目中将对哪些人可能生存作出分析,运用Python和机器学习的相关模型来预测哪些乘客幸免于难,数据来源自Kaggle
开发环境
Win7
Python3.6.0
项目步骤
提出问题—数据采集—数据处理—特征选择—训练模型—模型评估—提交结果
提出问题
具备哪些特征的人更容易存活?
数据来源
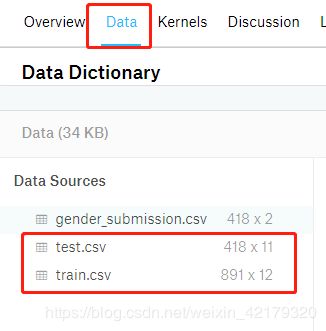
从Kaggle官网页面下载数据:https://www.kaggle.com/c/titanic
train.csv是用于训练模型的,共包含12个字段:PassengerId、Survived 、Pclass、Name、Sex、Age、SibSp、Parch、Ticket、Fare、Cabin、Embarked
test.csv是需要进行预测的,共包含11个字段:PassengerId、Pclass、Name、Sex、Age、SibSp、Parch、Ticket、Fare、Cabin、Embarked
需要对test的Survived进行预测,被解释变量为二分类变量。
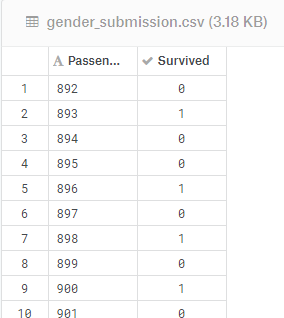
gender_submission.csv是提交结果的示样格式:
导入项目需要的库
import numpy as np
import pandas as pd
import csv
from sklearn.preprocessing import LabelEncoder as LE
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression as LR
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.svm import SVC
from sklearn.ensemble import GradientBoostingClassifier as GBC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.naive_bayes import GaussianNB as GNB
数据采集
#加载数据
train_data = pd.read_csv('D:/1桌面文件/快惠卡/桌面文件/Python文件/基本知识/train.csv',engine='python')
test_data = pd.read_csv('D:/1桌面文件/快惠卡/桌面文件/Python文件/基本知识/test.csv',engine='python')
查看初始数据集有几行几列
print(train_data.shape)
print(test_data.shape)
![]()
数据处理
因为需要同时清洗两个数据集,所以先要把两个数据集进行拼接
#上下整合两个表
all_data = pd.concat([train_data,test_data],axis=0)
#查看整合后的数据几行几列
print(all_data.shape)
#查看整合后的数据信息情况
all_data.info()
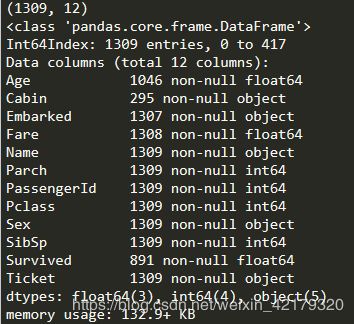
统计各字段缺失值情况:
Age缺失:(1309-1046)/1309=20%
Cabin缺失:77%
Embarked缺失:2条
Fare缺失:1条
缺失值处理
如果字段是连续类型,一般用平均值填充
如果字段是分类类型,一般用出现最多次的类别填充
#数据清洗,缺失值处理
#连续型
##年龄缺失值处理
all_data['Age'] = all_data['Age'].fillna(all_data['Age'].mean())
##票价缺失值处理
all_data['Fare'] = all_data['Fare'].fillna(all_data['Fare'].mean())
#分类型
##分类变量类别值统计
print(all_data['Embarked'].value_counts())
##最多为S,登船港口缺失值填充
all_data['Embarked'] = all_data['Embarked'].fillna('S')
##由于船舱号缺失值77%,缺失过多特殊处理
all_data['Cabin'] = all_data['Cabin'].fillna('NULL')
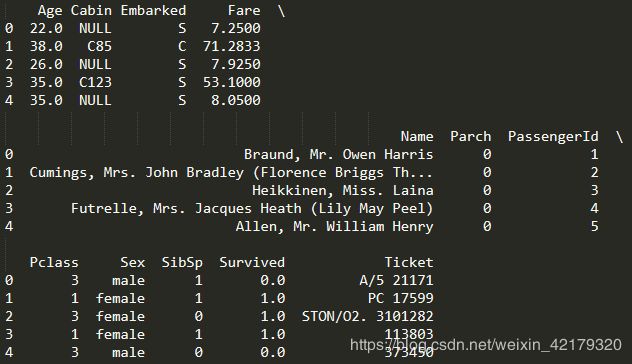
#检查缺失处理后的数据集
all_data.info()
print(all_data.head())

变量重编码
利用LabelEncoder进行重编码
#变量重编码
le = LE()
##性别
all_data['Sex'] = le.fit_transform(all_data['Sex'].values)
##登船港口
all_data['Embarked'] = le.fit_transform(all_data['Embarked'].values)
##船舱号
all_data['Cabin'] = le.fit_transform(all_data['Cabin'].values)
##查看编码后的数据集
print(all_data.head())
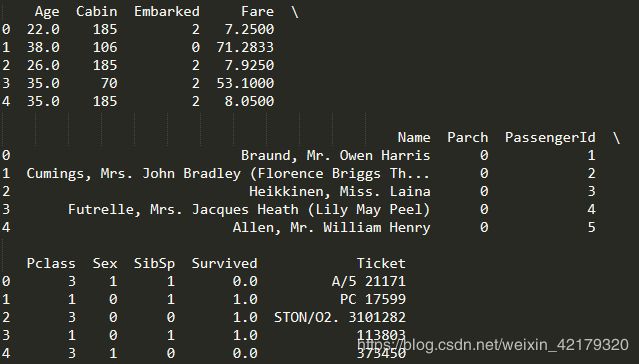
数据清洗后,别忘拆回两个数据集
#拆分回两个数据集,train,test
train_data = all_data[0:891]
test_data = all_data[891:].drop('Survived',axis=1)
##检查原始数据集与拆分后的行列是否一致
print(train_data.shape)
print(test_data.shape)
![]()
特征选择
删除无用列Name、Ticket,然后查看各变量与Survived的相关系数,选取相关系数绝对值较大的几个进入特征集
#相关性矩阵
##删除无用列
train_data = train_data.drop(['Name','Ticket'],axis=1)
print(train_data.shape)
corr_train_data = train_data.corr()
corr_sur = corr_train_data['Survived'].sort_values(ascending =False)
print(corr_sur)
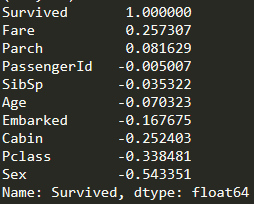
这里可看到Fare、Embarked、Cabin、Pclass、Sex与Survived相关性较强
#特征集选择
X = train_data[['Fare','Embarked','Cabin','Pclass','Sex']]
#结果集
y = train_data['Survived']
交叉验证
利用train_test_split对训练集进行拆分,用于交叉验证模型,测试数据占原始数据的80%
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.8)
训练模型
选用分类算法中比较常用的几个模型:
model1 = LR() #逻辑回归模型
model2 = RFC() #随机森林模型
model3 = SVC() #支持向量机模型
model4 = GBC() #梯度提升分类器模型
model5 = KNN() #K最近邻分类模型
model6 = GNB() #高斯朴素贝叶斯模型
model1.fit(X_train,y_train)
model2.fit(X_train,y_train)
model3.fit(X_train,y_train)
model4.fit(X_train,y_train)
model5.fit(X_train,y_train)
model6.fit(X_train,y_train)
模型评估
#评估模型
print(model1.score(X_train,y_train))
print(model2.score(X_train,y_train)) #模型分最高
print(model3.score(X_train,y_train))
print(model4.score(X_train,y_train))
print(model5.score(X_train,y_train))
print(model6.score(X_train,y_train))

可以看出第二个模型的分数最高为0.92,模型效果最好
预测
#对test数据集进行预测
X = test_data[['Fare','Embarked','Cabin','Pclass','Sex']]
y_predict = model2.predict(X)
#因为项目要求提交的结果Survived数据类型为整数,需要把上面得到的浮点类型进行转换
y_predict = y_predict.astype(int)
保存预测结果为CSV格式
#写入CSV文件
PassengerId = test_data['PassengerId']
titanic_pred = pd.DataFrame({'PassengerId':PassengerId,'Survived':y_predict})
print(titanic_pred.head())
titanic_pred.to_csv('titanic_pred.csv',index=0)

提交结果至Kaggle
第一步:

第二步:
第三步:
得出Kaggle计算的排名和正确率
 后续仍需要对模型进行不断优化
后续仍需要对模型进行不断优化