ORB SLAM2学习笔记之mono_kitti(三)
ORB SLAM2学习笔记之mono_kitti(三)
- 一、Tracking流程
- 二、实例化mpTracker
- ORBextractor
- 三、TrackMonocular
- GrabImageMonocular
- CurrentFrame构造
- ExtractORB函数的说明
- ComputePyramid
- ComputeKeyPointsOctTree
- CurrentFrame构造流程图
一、Tracking流程
大致流程如图所示,下面对细节进行展开说明。
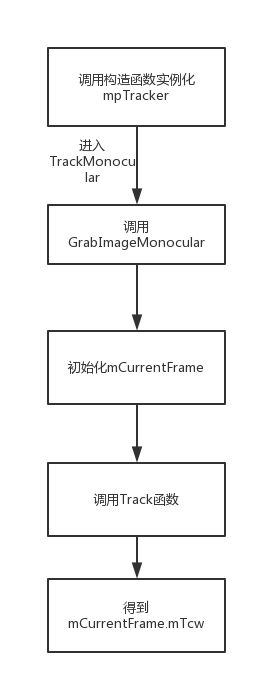
二、实例化mpTracker
在System构造函数中new一个Tracing对象指针mpTracker,方式如下所示:
//Initialize the Tracking thread
//(it will live in the main thread of execution, the one that called this constructor)
mpTracker = new Tracking(this, mpVocabulary, mpFrameDrawer, mpMapDrawer,
mpMap, mpKeyFrameDatabase, strSettingsFile, mSensor);
构造对象过程中,先进行了传参,如camera焦距,畸变系数,帧率等,然后读取配置文件里的有关提取特征方面的信息,比如每一帧需要提取的特征数(包括整个图像金字塔),金字塔层间尺度,金字塔层数,FAST关键点阈值等,最重要的是最后调用了ORBextractor构造一个ORB特征提取器。
mpIniORBextractor = new ORBextractor(2*nFeatures,fScaleFactor,nLevels,fIniThFAST,fMinThFAST);

那构造特征提取器时都干了些什么呢,如下所示:
ORBextractor
第一步:算金字塔每层的尺度,然后根据尺度计算每层应该提取多少特征点,这里面涉及了一个等比数列,唤起高中的记忆,还挺有意思的。最后,保证提取总特征点数≥ nfeatures。
//参数:特征点多少,金字塔层与层之间的尺度(用于算每层提取关键点的数量),金字塔层级数量,FAST角点阈值,最小角点阈值
ORBextractor::ORBextractor(int _nfeatures, float _scaleFactor, int _nlevels,
int _iniThFAST, int _minThFAST):
nfeatures(_nfeatures), scaleFactor(_scaleFactor), nlevels(_nlevels),
iniThFAST(_iniThFAST), minThFAST(_minThFAST)
{
mvScaleFactor.resize(nlevels);
mvLevelSigma2.resize(nlevels);
mvScaleFactor[0]=1.0f;
mvLevelSigma2[0]=1.0f;
for(int i=1; i<nlevels; i++)
{
mvScaleFactor[i]=mvScaleFactor[i-1]*scaleFactor;
mvLevelSigma2[i]=mvScaleFactor[i]*mvScaleFactor[i];
}
mvInvScaleFactor.resize(nlevels);
mvInvLevelSigma2.resize(nlevels);
for(int i=0; i<nlevels; i++)
{
mvInvScaleFactor[i]=1.0f/mvScaleFactor[i];
mvInvLevelSigma2[i]=1.0f/mvLevelSigma2[i];
}
mvImagePyramid.resize(nlevels);//金字塔有几层
mnFeaturesPerLevel.resize(nlevels);
float factor = 1.0f / scaleFactor; //梯度q
//第一层特征点的数量 nfeatures是总特征点的数量 后面的式子是等比数列求和公式 nfeatures × (1-q)/(1 - q^n)
float nDesiredFeaturesPerScale = nfeatures*(1 - factor)/(1 - (float)pow((double)factor, (double)nlevels));
//依次算每层的特征点数量,加和,保证最后总的特征点数量 ≥ nfeatures
int sumFeatures = 0;
for( int level = 0; level < nlevels-1; level++ )
{
mnFeaturesPerLevel[level] = cvRound(nDesiredFeaturesPerScale);
sumFeatures += mnFeaturesPerLevel[level];
nDesiredFeaturesPerScale *= factor;
}
mnFeaturesPerLevel[nlevels-1] = std::max(nfeatures - sumFeatures, 0);
第二步:准备制作描述子,包括采用bit_pattern_31_模板,计算像素点半径什么的,有点opencv源码的知识,没太看懂,不能钻牛角尖。。。有大神看懂下面的代码能给我讲一哈吗,求带求带
/*!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!复制训练用的模板!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!*/
const int npoints = 512;//512个点,256对点,比较完会有一个256位的描述子
const Point* pattern0 = (const Point*)bit_pattern_31_;//??? bit_pattern_31_可能的意思是描述子的计算区域直径是 31 的模式
//std::copy(start, end, std::back_inserter(container)); 从 start 到 end 的迭代器复制完放入 container 的后面
std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern));
//This is for orientation
// pre-compute the end of a row in a circular patch
umax.resize(HALF_PATCH_SIZE + 1);
int v, v0, vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1); //cvFloor含义是取不大于参数的最大整数值
int vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2); //cvCeil含义是取不小于参数的最小整数值
//?????????????????????????????????????????????????????????????????????????????????????????????????
const double hp2 = HALF_PATCH_SIZE*HALF_PATCH_SIZE; //半径的平方
for (v = 0; v <= vmax; ++v)
umax[v] = cvRound(sqrt(hp2 - v * v));
// Make sure we are symmetric
for (v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v)
{
while (umax[v0] == umax[v0 + 1])
++v0;
umax[v] = v0;
++v0;
}
三、TrackMonocular
如果忽略其他线程的构造,就继续回到main函数里,看得出main函数里很重要的就是这个TrackMonocular了,函数体如下所示:
cv::Mat System::TrackMonocular(const cv::Mat &im, const double ×tamp)
{
if(mSensor!=MONOCULAR)
{
cerr << "ERROR: you called TrackMonocular but input sensor was not set to Monocular." << endl;
exit(-1);
}
// Check mode change
{
unique_lock<mutex> lock(mMutexMode);
if(mbActivateLocalizationMode)
{
mpLocalMapper->RequestStop();
// Wait until Local Mapping has effectively stopped
while(!mpLocalMapper->isStopped())
{
usleep(1000);
}
mpTracker->InformOnlyTracking(true);
mbActivateLocalizationMode = false;
}
if(mbDeactivateLocalizationMode)
{
mpTracker->InformOnlyTracking(false);
mpLocalMapper->Release();
mbDeactivateLocalizationMode = false;
}
}
// Check reset
{
unique_lock<mutex> lock(mMutexReset);
if(mbReset)
{
mpTracker->Reset();
mbReset = false;
}
}
cv::Mat Tcw = mpTracker->GrabImageMonocular(im,timestamp);
unique_lock<mutex> lock2(mMutexState);
mTrackingState = mpTracker->mState;
mTrackedMapPoints = mpTracker->mCurrentFrame.mvpMapPoints;
mTrackedKeyPointsUn = mpTracker->mCurrentFrame.mvKeysUn;
return Tcw;
}
看得出这个函数调用完会返回一个Mat类的东西,就是Tcw位姿。函数刚开始先check了一下系统现在是不是LocalizationMode,有没有Reset,用了mutex大概是为了防止不同线程访问共享内存从而出错,并发编程这里还不是很懂,也没有什么具体资料,等学会以后会更新一下,还请大神走过路过赐教一下鸭…接下来进入GrabImageMonocular函数,计算都是在这里进行的。
GrabImageMonocular
函数需要两个参数:图片和对应的时间戳。先进行图片格式的转换,然后构造了CurrentFrame,最后进行Track。
cv::Mat Tracking::GrabImageMonocular(const cv::Mat &im, const double ×tamp)
{
mImGray = im;
//根据传入图片的不同情况转换图片格式
if(mImGray.channels()==3)
{
if(mbRGB)
cvtColor(mImGray,mImGray,CV_RGB2GRAY);
else
cvtColor(mImGray,mImGray,CV_BGR2GRAY);
}
else if(mImGray.channels()==4)
{
if(mbRGB)
cvtColor(mImGray,mImGray,CV_RGBA2GRAY);
else
cvtColor(mImGray,mImGray,CV_BGRA2GRAY);
}
if(mState==NOT_INITIALIZED || mState==NO_IMAGES_YET) //之前Tracking构造函数的时候,已经将mState初始化为NO_IMAGES_YET
mCurrentFrame = Frame(mImGray,timestamp,mpIniORBextractor,mpORBVocabulary,mK,mDistCoef,mbf,mThDepth);
else
mCurrentFrame = Frame(mImGray,timestamp,mpORBextractorLeft,mpORBVocabulary,mK,mDistCoef,mbf,mThDepth);
Track();
return mCurrentFrame.mTcw.clone();
}
CurrentFrame构造
构造当前帧( CurrentFrame )需要传入几个参数,见下面注释。函数内部干了几件事:
第一个:从ORBextractor中提取一些参数用于后面提取特征点;
Frame::Frame(const cv::Mat &imGray, const double &timeStamp, ORBextractor* extractor,ORBVocabulary* voc, cv::Mat &K, cv::Mat &distCoef, const float &bf, const float &thDepth)
:mpORBvocabulary(voc),mpORBextractorLeft(extractor),mpORBextractorRight(static_cast<ORBextractor*>(NULL)),
mTimeStamp(timeStamp), mK(K.clone()),mDistCoef(distCoef.clone()), mbf(bf), mThDepth(thDepth)
{
// Frame ID
mnId=nNextId++;
// Scale Level Info 图像金字塔参数
mnScaleLevels = mpORBextractorLeft->GetLevels();
mfScaleFactor = mpORBextractorLeft->GetScaleFactor();
mfLogScaleFactor = log(mfScaleFactor);
mvScaleFactors = mpORBextractorLeft->GetScaleFactors();
mvInvScaleFactors = mpORBextractorLeft->GetInverseScaleFactors();
mvLevelSigma2 = mpORBextractorLeft->GetScaleSigmaSquares();
mvInvLevelSigma2 = mpORBextractorLeft->GetInverseScaleSigmaSquares();
第二个:调用函数ExtractORB提取ORB特征,然后对特征点去畸变;
// ORB extraction
ExtractORB(0,imGray);//能得到 mvKeys 与 mDescriptors,关键点和描述子
N = mvKeys.size();
if(mvKeys.empty())
return;
UndistortKeyPoints(); //关键点去畸变
// Set no stereo information
mvuRight = vector<float>(N,-1);
mvDepth = vector<float>(N,-1);
mvpMapPoints = vector<MapPoint*>(N,static_cast<MapPoint*>(NULL));
mvbOutlier = vector<bool>(N,false);
第三个:如果是对第一帧图像,还会计算图片边界,然后把特征点分配进之前打算分的格子中
// This is done only for the first Frame (or after a change in the calibration)
if(mbInitialComputations)
{
ComputeImageBounds(imGray); // 算出 mnMinX mnMaxX mnMinY mnMaxY
mfGridElementWidthInv=static_cast<float>(FRAME_GRID_COLS)/static_cast<float>(mnMaxX-mnMinX);
mfGridElementHeightInv=static_cast<float>(FRAME_GRID_ROWS)/static_cast<float>(mnMaxY-mnMinY);
fx = K.at<float>(0,0);
fy = K.at<float>(1,1);
cx = K.at<float>(0,2);
cy = K.at<float>(1,2);
invfx = 1.0f/fx;
invfy = 1.0f/fy;
mbInitialComputations=false;
}
mb = mbf/fx;
AssignFeaturesToGrid(); //把特征加入格子中
}
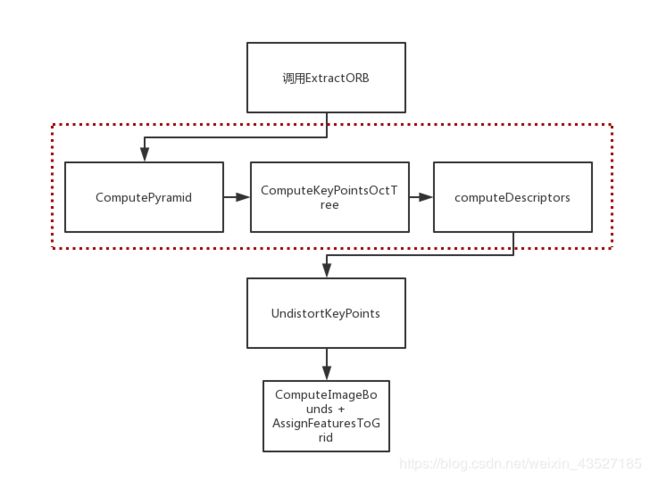
ExtractORB函数的说明
函数里面调用了ORBextractor类里的operator()函数,用于提取关键点和描述子:
void Frame::ExtractORB(int flag, const cv::Mat &im)
{
if(flag==0)
(*mpORBextractorLeft)(im,cv::Mat(),mvKeys,mDescriptors);
else
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}
operator()函数需要传入要提取的图像,内部为:
//提取关键点和描述子
void ORBextractor::operator()( InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints,
OutputArray _descriptors)
{
if(_image.empty())
return;
Mat image = _image.getMat();
assert(image.type() == CV_8UC1 );
// Pre-compute the scale pyramid
ComputePyramid(image); // 计算 mvImagePyramid
vector < vector<KeyPoint> > allKeypoints;
ComputeKeyPointsOctTree(allKeypoints);
//ComputeKeyPointsOld(allKeypoints);
Mat descriptors;
int nkeypoints = 0;
for (int level = 0; level < nlevels; ++level)
nkeypoints += (int)allKeypoints[level].size();
if( nkeypoints == 0 )
_descriptors.release();
else
{
_descriptors.create(nkeypoints, 32, CV_8U);
descriptors = _descriptors.getMat();
}
_keypoints.clear();
_keypoints.reserve(nkeypoints);
int offset = 0;
for (int level = 0; level < nlevels; ++level)
{
vector<KeyPoint>& keypoints = allKeypoints[level];
int nkeypointsLevel = (int)keypoints.size();
if(nkeypointsLevel==0)
continue;
// preprocess the resized image
Mat workingMat = mvImagePyramid[level].clone();
GaussianBlur(workingMat, workingMat, Size(7, 7), 2, 2, BORDER_REFLECT_101);
// Compute the descriptors
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
computeDescriptors(workingMat, keypoints, desc, pattern);
offset += nkeypointsLevel;
// Scale keypoint coordinates
if (level != 0)
{
float scale = mvScaleFactor[level]; //getScale(level, firstLevel, scaleFactor);
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
keypoint->pt *= scale;
}
// And add the keypoints to the output
_keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
}
}
其中提取FAST关键点有两个很重要的函数是 ComputePyramid和 ComputeKeyPointsOctTree,(其实还有一个computeDescriptors也很重要不过没细看)前者构建了图像金字塔 mvImagePyramid 供给后面 OctTree 的计算。
ComputePyramid
这个函数有个很奇怪的地方,for循环里面有个Mat temp的初始化,也就是说每调用一次就会重新构造temp这个对象,但是这样的话后面copyMakeBorder这个函数就没什么作用了鸭…但我确实就像下面代码中的一样将temp cout 出来发现它并不都是初始化后的状态,C++博大精深…希望路过的大神能帮我解答一下…
void ORBextractor::ComputePyramid(cv::Mat image)
{
for (int level = 0; level < nlevels; ++level)
{
float scale = mvInvScaleFactor[level];
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));//列数是宽,行数是高
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);
Mat temp(wholeSize, image.type()), masktemp;
//cout<<"temp"<
//左上角点坐标,宽,高
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
// Compute the resized image
if( level != 0 )
{
resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR);
//造边界
copyMakeBorder(mvImagePyramid[level], temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101+BORDER_ISOLATED);
}
else
{
//造边界EDGE_THRESHOLD ,以最外面的像素为对称轴,输出为temp
copyMakeBorder(image, temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101);
}
}
}
ComputeKeyPointsOctTree
函数采用划分格子的形式在格子里挑选关键点,这样可能效率更高些,然后通过函数DistributeOctTree以四叉树形式将关键点分配给每个节点,然后将响应值response最大的点挑出来,这样能保证关键点分布是均匀的,然后通过computeOrientation函数利用灰度质心法IC_Angle计算关键点的方向。过程略复杂,如下面注释所示:
void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint> >& allKeypoints)
{
allKeypoints.resize(nlevels);// 有 nlevels 层 keypoints
// 设置格子大小
const float W = 30;
for (int level = 0; level < nlevels; ++level)
{
const int minBorderX = EDGE_THRESHOLD-3;
const int minBorderY = minBorderX;
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+3;
vector<cv::KeyPoint> vToDistributeKeys;
vToDistributeKeys.reserve(nfeatures*10);
const float width = (maxBorderX-minBorderX);
const float height = (maxBorderY-minBorderY);
const int nCols = width/W; //每一行有几个格子
const int nRows = height/W; //每一列有几个格子
const int wCell = ceil(width/nCols); //每一行每个格子的实际宽度
const int hCell = ceil(height/nRows); //每一列每个格子的实际高度
for(int i=0; i<nRows; i++)
{
const float iniY =minBorderY+i*hCell; //cell的起始y值
float maxY = iniY+hCell+6; //cell的最大y值
if(iniY>=maxBorderY-3)
continue;
if(maxY>maxBorderY)
maxY = maxBorderY;
for(int j=0; j<nCols; j++)
{
const float iniX =minBorderX+j*wCell; //cell的起始x值
float maxX = iniX+wCell+6; //cell的最大x值
if(iniX>=maxBorderX-6)
continue;
if(maxX>maxBorderX)
maxX = maxBorderX;
vector<cv::KeyPoint> vKeysCell;
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,iniThFAST,true);
// 如果检测到的fast特征为空,则降低阈值再进行检测
if(vKeysCell.empty())
{
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,minThFAST,true);
}
if(!vKeysCell.empty())
{
for(vector<cv::KeyPoint>::iterator vit=vKeysCell.begin(); vit!=vKeysCell.end();vit++)
{
(*vit).pt.x+=j*wCell; //每个cell中特征点实际的x坐标,当然,是相对于minBorderX的
(*vit).pt.y+=i*hCell; //每个cell中特征点实际的y坐标,当然,是相对于minBorderY的
vToDistributeKeys.push_back(*vit); //装满了每一层FAST特征点
}
}
}
}
//把第level层的keypoints赋值。 keypoints变化,allKeypoints[level]也跟着变化 KeyPoint类里面有pt、angle等信息
vector<KeyPoint> & keypoints = allKeypoints[level];
keypoints.reserve(nfeatures);
//对每个节点里面的特征进行选择最好特征,这样就对检测到的特征进行了均匀化处理
keypoints = DistributeOctTree(vToDistributeKeys, minBorderX, maxBorderX,
minBorderY, maxBorderY,mnFeaturesPerLevel[level], level);
const int scaledPatchSize = PATCH_SIZE*mvScaleFactor[level]; //每层直径的尺度不一样
// Add border to coordinates and scale information
// 换算关键点真实位置(添加边界值),添加关键点的尺度信息
const int nkps = keypoints.size();
for(int i=0; i<nkps ; i++)
{
keypoints[i].pt.x+=minBorderX;
keypoints[i].pt.y+=minBorderY;
keypoints[i].octave=level; //金字塔第几层
keypoints[i].size = scaledPatchSize;
}
}
// compute orientations
for (int level = 0; level < nlevels; ++level)
computeOrientation(mvImagePyramid[level], allKeypoints[level], umax);
}
DistributeOctTree函数功能是把关键点均匀化,就不多说了,代码注释的很详细,直接贴代码了,略长但是逻辑很清晰,父节点生子节点,一生四,四生十六,每层金字塔都这么做:
/*!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!将图像划分成四叉树形式!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!*/
//参数: 第level层的所有FAST关键点组成的vector,特征检测区域上下两个边界的x与y坐标,第level层的特征点数量,第level层
vector<cv::KeyPoint> ORBextractor::DistributeOctTree(const vector<cv::KeyPoint>& vToDistributeKeys, const int &minX,
const int &maxX, const int &minY, const int &maxY, const int &N, const int &level)
{
// Compute how many initial nodes
//根据图像宽高比例确定有几个节点,例如图像太长或太扁初始节点可能多于一个
const int nIni = round( static_cast<float>(maxX-minX)/(maxY-minY) );
//节点在x方向上的长度
const float hX = static_cast<float>(maxX-minX)/nIni;
list<ExtractorNode> lNodes;
vector<ExtractorNode*> vpIniNodes;
vpIniNodes.resize(nIni);
//UL UR BL BR是节点的四个角的坐标
for(int i=0; i<nIni; i++)
{
ExtractorNode ni;
ni.UL = cv::Point2i(hX*static_cast<float>(i),0);
ni.UR = cv::Point2i(hX*static_cast<float>(i+1),0);
ni.BL = cv::Point2i(ni.UL.x,maxY-minY);
ni.BR = cv::Point2i(ni.UR.x,maxY-minY);
ni.vKeys.reserve(vToDistributeKeys.size());
lNodes.push_back(ni);
vpIniNodes[i] = &lNodes.back();
}
//Associate points to childs
//把图片里的关键点分配到节点中去
for(size_t i=0;i<vToDistributeKeys.size();i++)
{
const cv::KeyPoint &kp = vToDistributeKeys[i];
vpIniNodes[kp.pt.x/hX]->vKeys.push_back(kp);
}
list<ExtractorNode>::iterator lit = lNodes.begin();
while(lit!=lNodes.end())
{
if(lit->vKeys.size()==1)
{
lit->bNoMore=true;
lit++;
}
else if(lit->vKeys.empty())
lit = lNodes.erase(lit);
else
lit++;
}
bool bFinish = false;
int iteration = 0;
vector<pair<int,ExtractorNode*> > vSizeAndPointerToNode; //节点 和 它对应包含的 特征点数
vSizeAndPointerToNode.reserve(lNodes.size()*4); //一共有几个子节点(从初始节点分叉)
while(!bFinish)
{
iteration++;
int prevSize = lNodes.size(); //老节点的数量
lit = lNodes.begin(); //lit是节点的迭代器
int nToExpand = 0;
vSizeAndPointerToNode.clear();//清空
/*感觉while执行完 要么就是不再划分新节点,lnodes里都是老节点,
要么就是分完新节点后老节点被一个个erase掉,新节点从前面一个个添加进来*/
while(lit!=lNodes.end())
{
if(lit->bNoMore)
{
// If node only contains one point do not subdivide and continue
// 如果节点中只有一个特征点就不划分了
lit++;
continue;
}
else
{
// If more than one point, subdivide
ExtractorNode n1,n2,n3,n4;
lit->DivideNode(n1,n2,n3,n4);
// Add childs if they contain points
if(!n1.vKeys.empty())
{
lNodes.push_front(n1); //把子节点推到lnodes前面 变成lnodes的一部分
if(n1.vKeys.size()>1)
{
nToExpand++; //还要再分
//把n1与它里面的特征点数量推进去
vSizeAndPointerToNode.push_back(make_pair(n1.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin(); //begin()迭代器 赋给 第一个元素的迭代器
}
}
if(!n2.vKeys.empty())
{
lNodes.push_front(n2);
if(n2.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n2.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(!n3.vKeys.empty())
{
lNodes.push_front(n3);
if(n3.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n3.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(!n4.vKeys.empty())
{
lNodes.push_front(n4);
if(n4.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n4.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
lit=lNodes.erase(lit); //lit指向下一个元素
continue;
}
}
// Finish if there are more nodes than required features
// or all nodes contain just one point
if((int)lNodes.size()>=N || (int)lNodes.size()==prevSize)
{
bFinish = true;
}
//节点展开次数乘以3用于表明下一次的节点分解可能超过特征数,即为最后一次分解
else if(((int)lNodes.size()+nToExpand*3)>N)
{
while(!bFinish)
{
prevSize = lNodes.size();
vector<pair<int,ExtractorNode*> > vPrevSizeAndPointerToNode = vSizeAndPointerToNode;
vSizeAndPointerToNode.clear();
sort(vPrevSizeAndPointerToNode.begin(),vPrevSizeAndPointerToNode.end());
for(int j=vPrevSizeAndPointerToNode.size()-1;j>=0;j--)
{
ExtractorNode n1,n2,n3,n4;
vPrevSizeAndPointerToNode[j].second->DivideNode(n1,n2,n3,n4);
// Add childs if they contain points
if(n1.vKeys.size()>0)
{
lNodes.push_front(n1);
if(n1.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n1.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n2.vKeys.size()>0)
{
lNodes.push_front(n2);
if(n2.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n2.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n3.vKeys.size()>0)
{
lNodes.push_front(n3);
if(n3.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n3.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n4.vKeys.size()>0)
{
lNodes.push_front(n4);
if(n4.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n4.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
lNodes.erase(vPrevSizeAndPointerToNode[j].second->lit);
if((int)lNodes.size()>=N)
break;
}
if((int)lNodes.size()>=N || (int)lNodes.size()==prevSize)
bFinish = true;
}
}
}
// Retain the best point in each node
vector<cv::KeyPoint> vResultKeys;
vResultKeys.reserve(nfeatures);
for(list<ExtractorNode>::iterator lit=lNodes.begin(); lit!=lNodes.end(); lit++)
{
vector<cv::KeyPoint> &vNodeKeys = lit->vKeys;//vNodeKeys是一个节点中的特征点
cv::KeyPoint* pKP = &vNodeKeys[0];//第一个特征点
float maxResponse = pKP->response; //response代表着该关键点how good,更确切的说,是该点角点的程度。
for(size_t k=1;k<vNodeKeys.size();k++) //选择一个响应最大的特征点
{
if(vNodeKeys[k].response>maxResponse)
{
pKP = &vNodeKeys[k];
maxResponse = vNodeKeys[k].response;
}
}
vResultKeys.push_back(*pKP); //推进去
}
return vResultKeys;//把最终的筛选过的每个节点中响应最好的特征点作为结果返回
}
这里面有个函数叫DivideNode,代码如下,功能就像函数名一样,父节点分成四个子节点,别忘了x和y轴的方向:
void ExtractorNode::DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4)
{
const int halfX = ceil(static_cast<float>(UR.x-UL.x)/2);
const int halfY = ceil(static_cast<float>(BR.y-UL.y)/2);
//Define boundaries of childs
/*!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
* -------------------------------------------------→
* | | |
* | | |
* | n1 | n2 |
* | | |
* | | |
* |----------------------|---------------------|
* | | |
* | | |
* | n3 | n4 |
* | | |
* | | |
* |---------------------------------------------
* ↓
*
*!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!*/
n1.UL = UL;
n1.UR = cv::Point2i(UL.x+halfX,UL.y);
n1.BL = cv::Point2i(UL.x,UL.y+halfY);
n1.BR = cv::Point2i(UL.x+halfX,UL.y+halfY);
n1.vKeys.reserve(vKeys.size());
n2.UL = n1.UR;
n2.UR = UR;
n2.BL = n1.BR;
n2.BR = cv::Point2i(UR.x,UL.y+halfY);
n2.vKeys.reserve(vKeys.size());
n3.UL = n1.BL;
n3.UR = n1.BR;
n3.BL = BL;
n3.BR = cv::Point2i(n1.BR.x,BL.y);
n3.vKeys.reserve(vKeys.size());
n4.UL = n3.UR;
n4.UR = n2.BR;
n4.BL = n3.BR;
n4.BR = BR;
n4.vKeys.reserve(vKeys.size());
//Associate points to childs
for(size_t i=0;i<vKeys.size();i++)
{
const cv::KeyPoint &kp = vKeys[i];
if(kp.pt.x<n1.UR.x)
{
if(kp.pt.y<n1.BR.y)
n1.vKeys.push_back(kp);
else
n3.vKeys.push_back(kp);
}
else if(kp.pt.y<n1.BR.y)
n2.vKeys.push_back(kp);
else
n4.vKeys.push_back(kp);
}
if(n1.vKeys.size()==1)
n1.bNoMore = true;
if(n2.vKeys.size()==1)
n2.bNoMore = true;
if(n3.vKeys.size()==1)
n3.bNoMore = true;
if(n4.vKeys.size()==1)
n4.bNoMore = true;
}
CurrentFrame构造流程图
Track()函数还没有看,看完下篇博客总结,最后看一下构造当前帧的流程图: