数据挖掘实战(二):特征工程
文章目录
- 一、特征衍生
- 二、特征选择
- 1. 利用随机森林做特征选择
- 2. 利用IV值做特征选择
- 2.1 WOE
- 2.2 IV
- 2.3 代码实现
- 3. 利用相关系数做特征选择
一、特征衍生
特征衍生是现有的特征进行某种组合,生成新的具有含义的特征。
举例:
下面有份数据集,这份数据表示的是用户在电商平台上的购物行为(购物行为0表示点击但未购买,1表示购买)
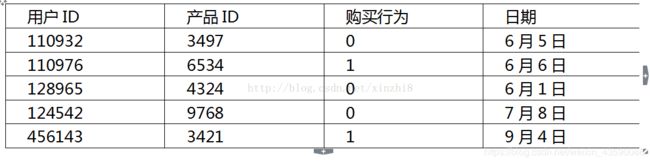
通过这份数据(1〜9月的购物数据),需要解决的场景是预测接下来3个月(10〜12 月)用户会购买哪些产品。这里只有后面两个字段可以代入计算,因此可以扩充字段。这里分用户和商品来讨论
1、 用户
(1)根据历史购买
购买频率 = 用户购买总量 / (用户最后购买时间 - 用户第一次购买时间)

(2)根据时间序列

2、商品
(1)商品热度
商品的特点主要可以 通过3方面来刻画,分别是产品的产品热度、季节因素和产品的消耗频率。
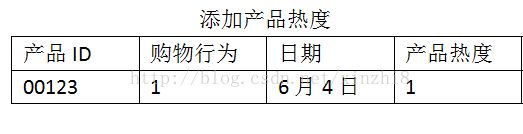
(2)产品时间序列

3、购物者和商品的关系
比如消费者看上一个物品,但是比较贵,所以每周点击这个物品,看有没有打折,于是可以构造一个特征,即用户A对产品B的点击频率。
二、特征选择
1. 利用随机森林做特征选择
在做特征工程时,当提取完特征后,可能存在并不是所有的特征都能分类起到作用的问题,这个时候就需要使用特征选择的方法选出相对重要的特征用于构建分类器。
y = df['status']
x = df[df.loc[:,df.columns != 'status'].columns]
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier()
forest_clf.fit(x,y)
# 随即森林自带“feature_importances_”属性,可以计算出每个特征的重要性。
features_weights = dict(zip(df.columns,forest_clf.feature_importances_))
fearures_weights_sorted = sorted(features_weights.items(),key = lambda x:x[1],reverse=True)
# 降序排列,选择前15个
for item in range(15):
print(features_weights_sorted[item][0],':',features_weights_sorted[item][1])
输出:
trans_fail_top_count_enum_last_1_month : 0.0673929669765
history_suc_fee : 0.0507540024626
latest_six_month_apply : 0.0353743734012
trans_day_last_12_month : 0.0305523664734
historical_trans_day : 0.0227202860861
abs : 0.0226874745121
first_transaction_time : 0.0210097647691
query_sum_count : 0.0200768569447
first_transaction_day : 0.0180287037591
historical_trans_amount : 0.0179484857245
repayment_capability : 0.017806736205
latest_one_month_suc : 0.0172000463325
consfin_avg_limit : 0.0169807470247
loans_avg_limit : 0.0168177855921
trans_amount_increase_rate_lately : 0.0165810588516
2. 利用IV值做特征选择
IV的全称是Information Value,中文意思是信息价值,或者信息量,用来衡量一个变量的预测能力,类似于信息增量、基尼系数等。计算IV值首先需要用到WOE值(即weight of evidence,翻译为证据权重)
2.1 WOE
要对一个特征计算 WOE,尤其是连续型的数值特征,需要先对特征做离散化处理,也叫做分组或分箱。假设共有 M 个样本,其中正负样本数量分别为 PM 和 NM ,满足 PM+NM=M。只考虑单个特征,分组数量为 N,第 i 个分组中正负样本数量分别为 pi 和 ni。则对于第 i 组,其 WOE 计算公式为:
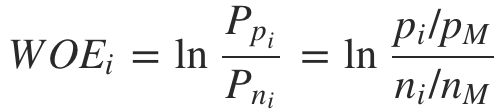
从公式中可以看出,WOE 表达的是当前分组中正样本占所有正样本的比例与当前分组中负样本占所有负样本的比例的比例关系。
举例:预测公司的客户集合中的每个客户对于我们的某项营销活动是否能够响应。随机抽取了100000个客户进行了营销活动测试,收集了这些客户的响应结果,作为我们的建模数据集,其中响应的客户有10000个。
特征变量:最近一个月是否有购买、最近一次购买金额等
分组i:每一行代表一个分组i
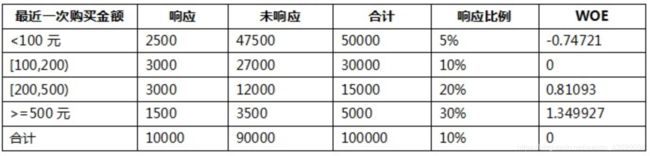

从 WOE 的计算公式可以看出,WOE 有正有负,分别表达了特征在该分组上与整体样本是正相关还是负相关。
2.2 IV
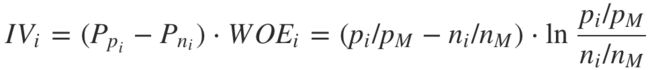
上面是特征的第 i 个分组的 IV 值,整个特征的 IV 值即为所有分组的 IV 值相加:
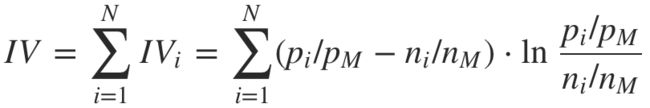
IV 值越高的特征,说明在模型中的预测能力越强,在做特征选择时,可以按 IV 值从高到低筛选。

一个特征的IV值就是几个分组的IV值相加
![]()
2.3 代码实现
# 根据IV(信息价值)
def calc_iv(df, feature, target, pr=False):
"""
Set pr=True to enable printing of output.
Output:
* iv: float,
* data: pandas.DataFrame
"""
lst = []# 新建一个列表,包含某一特征、正样本、负样本、所有样本、target
df[feature] = df[feature].fillna('NULL')
for i in range(df[feature].nunique()): # nuinque()是查看该序列(axis=0/1对应着列或行)的不同值的数量个数
val = list(df[feature].unique())[i] #这里是讲特征里的每个值作为分组,也可以分段分组
lst.append([feature,
val, # Value
df[df[feature] == val].count()[feature], # 特征中等于分组值的计数
df[(df[feature] == val) & (df[target] == 0)].count()[feature], # good rate
df[(df[feature] == val) & (df[target] == 1)].count()[feature]]) # bad rate
data = pd.DataFrame(lst, columns=['Variable', 'Value', 'All', 'Good', 'Bad'])
data['Share'] = data['All'] / data['All'].sum()
data['Bad Rate'] = data['Bad'] / data['All']
data['Distribution Good'] = (data['All'] - data['Bad']) / (data['All'].sum() - data['Bad'].sum())
data['Distribution Bad'] = data['Bad'] / data['Bad'].sum()
# 公式为WoE=(根据分组值选出的好的/所有好的)/(根据分组值选出坏的/所有坏的)
data['WoE'] = np.log(data['Distribution Good'] / data['Distribution Bad'])
# 二维表格式
data = data.replace({'WoE': {np.inf: 0, -np.inf: 0}})
# 计算IV值,IV值范围为0到正无穷
data['IV'] = data['WoE'] * (data['Distribution Good'] - data['Distribution Bad'])
data = data.sort_values(by=['Variable', 'Value'], ascending=[True, True])
data.index = range(len(data.index))
if pr:
print(data)
print("IV = ", data['IV'].sum())
iv = data['IV'].sum() #所有分组值的iv求和就是该特征的iv值
return iv, data
column_headers = list(df.columns.values)
# print(column_headers)
d=[]
for x in column_headers: #输入每个特征,计算每个特征的IV值
IV_1, data = calc_iv(df, x, 'status')
d.append(IV_1)
#整理成Series类型并合并
column_headers=pd.Series(column_headers,name='feature')
d=pd.Series(d,name='iv_value')
iv_result=pd.concat([column_headers,d],axis=1)
iv_result.sort_values(by='iv_value',ascending=False)
输出:

3. 利用相关系数做特征选择
分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征。
#1根据相关系数
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
coor = df.corr() #相关系数
corr_status = abs(coor['status']) #返回绝对值
corr_status_sorted = corr_status.sort_values(ascending=False)
corr_status_sorted = corr_status_sorted[corr_status_sorted.values>0.1] #根据相关系数大于0.1,最终选择出12个特征
features_index = corr_status_sorted.index
corr_status_sorted
输出:
status 1.000000
trans_fail_top_count_enum_last_1_month 0.353827
history_fail_fee 0.316256
latest_one_month_fail 0.303966
loans_overdue_count 0.277031
loans_score 0.247065
apply_score 0.241282
rank_trad_1_month 0.167965
trans_fail_top_count_enum_last_6_month 0.143895
top_trans_count_last_1_month 0.141192
latest_one_month_suc 0.130959
trans_fail_top_count_enum_last_12_month 0.129070
trans_day_last_12_month 0.106758
Name: status, dtype: float64