朴素贝叶斯分类算法(Naive Bayes)
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯原理简单,也很容易实现,多用于文本分类,比如垃圾邮件过滤。
理论基础
1、条件概率: 朴素贝叶斯最核心的部分是贝叶斯法则,而贝叶斯法则的基石是条件概率。贝叶斯法则如下:
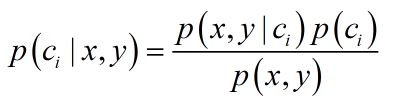
这里的C表示类别,输入待判断数据,式子给出要求解的某一类的概率。我们的最终目的是比较各类别的概率值大小,而上面式子的分母是不变的,因此只要计算分子即可。仍以“坏蛋识别器”为例。我们用C0表示好人,C1表示坏人,现在100个人中有60个好人,P(C0)=0.6,那么P(x,y|C0)怎么求呢?注意,这里的(x,y)是多维的,因为有60个好人,每个人又有“性别”、“笑”、“纹身”等多个特征,这些构成X,y是标签向量,有60个0和40个1构成。这里我们假设X的特征之间是独立的,互相不影响,这就是朴素贝叶斯中“朴素”的由来。在假设特征间独立的假设下,很容易得到P(x,y|C0)=P(x0,y0|C0)P(x1,y1|C0)...P(xn,yn|C0)。
2、举例说明:
例1:工厂生产产品,合格产品的概率是0.9,误检的概率是0.2,误检情况中合格产品的概率是0.1,那合格产品被误检的概率是多少?
直接套用贝叶斯公式,可得:

例2:假设有个严重的疾病,发生的概率是万分之一,现在某人神经大条,怀疑得了该病,跑到医院检查,结果确有此病,不过医院的测试报告只有99%准确度(另外,也指正常人检测99%没问题,1%检测错误)。那么,他的死亡风险有多大?
咋一看,此人快要和世界说拜拜了,这个时候贝叶斯公式派上用场了,其中,用D表示该病(D=1,得病;D=0,健康),P表示报告准确度(T=1,准确;T=0,错误),可得:
![]()
可见,患病的几率很小,并没有想象中可怕。
案例实战
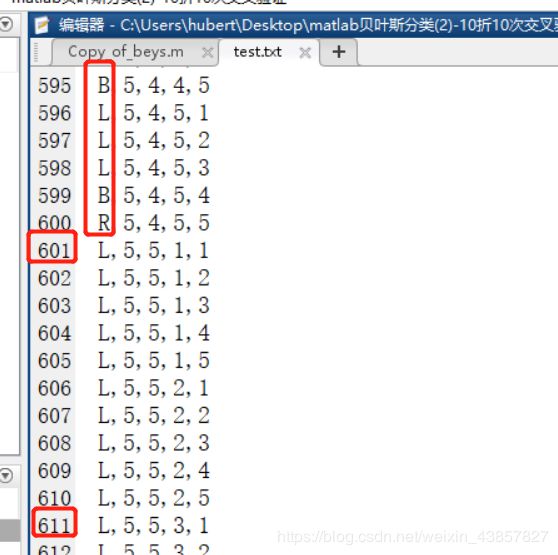
1、数据简介:text.txt 下载地址
本训练数据共有625个训练样例,每个样例有4个属性x1,x2,x3,x4,每个属性值可以取值{1,2,3,4,5}。数据集中的每个样例都有标签"L",“B"或"R”。我们在这里序号末尾为1的样本当作测试集,共有63个,其他的作为训练集,共有562个。
2、读取数据
clear;
clc;
ex=importdata('test.txt'); %读入文件
X=ex.data;
[m,n]=size(ex.textdata); %数据大小

3、实现类的标签"L",“B”,"R"转换成数字1,2,3
Y=zeros(m);
for i=1:m
if strcmp(ex.textdata(i),'L')==1 %如果字符串是L则y(i)等于1
Y(i)=1;
elseif strcmp(ex.textdata(i),'B')==1
Y(i)=2;
else Y(i)=3;
end
end

3、整体代码:
clear;
clc;
ex=importdata('test.txt'); %读入文件
X=ex.data;
[m,n]=size(ex.textdata); %数据大小
Y=zeros(m);
for i=1:m
if strcmp(ex.textdata(i),'L')==1 %如果字符串是L则y(i)等于1
Y(i)=1;
elseif strcmp(ex.textdata(i),'B')==1
Y(i)=2;
else Y(i)=3;
end
end
%朴素贝叶斯算法实现分类问题(三类y=1,y=2,y=3)
%我们把所有数字序号末尾为1的留作测试集,其他未训练集
% m=625; %样本总数
% m1=562; %训练集样本数量
% m2=63; %测试集样本数量
%10折10次交叉验证
indices = crossvalind('Kfold',m,10); %产生10个fold,即indices里有等比例的1-10
accuracy = 0;
for i=1:10
test=(indices==i); %逻辑判断,每次循环选取一个fold作为测试集 625*1
train=~test; %取test的补集作为训练集,即剩下的9个fold 625*1
data_train=X(train,:); %以上得到的数都为逻辑值,用与样本集的选取
label_train=Y(train,:); %label为样本类别标签,同样选取相应的训练集
data_test=X(test,:); %同理选取测试集的样本和标签
label_test=Y(test,:);
[l1,l3] = size(label_train);%562 625
[l2,l4] = size(label_test); %63 625
%三类样本数量分别记为count1,count2,count3
count1=0;
count2=0;
count3=0;
%count_1(i,j)表示在第一类(y=1)的情况下,第i个属性是j的样本个数
count_1=zeros(4,5);
%count_2(i,j)表示在第二类(y=2)的情况下,第i个属性是j的样本个数
count_2=zeros(4,5);
%count_3(i,j)表示在第三类(y=3)的情况下,第i个属性是j的样本个数
count_3=zeros(4,5);
ii=1;%用来标识测试集的序号
for i=1:l1
x=data_train(i,:);
if label_train(i)==1
count1=count1+1;
for j=1:4 %指示第j个属性
for k=1:5 %第j个属性为哪个值
if x(j)==k
count_1(j,k)=count_1(j,k)+1;
break;
end
end
end
elseif label_train(i)==2
count2=count2+1;
for j=1:4 %指示第j个属性
for k=1:5 %第j个属性为哪个值
if x(j)==k
count_2(j,k)=count_2(j,k)+1;
break;
end
end
end
else
count3=count3+1;
for j=1:4 %指示第j个属性
for k=1:5 %第j个属性为哪个值
if x(j)==k
count_3(j,k)=count_3(j,k)+1;
break;
end
end
end
end
%分别计算三类概率y1=p(y=1)、y2=p(y=2)、y3=p(y=3)的估计值
y1=count1/l1;
y2=count2/l1;
y3=count3/l1;
%y_1(i,j)表示在第一类(y=1)的情况下,第i个属性取值为j的概率估计值
%y_2(i,j)表示在第二类(y=2)的情况下,第i个属性取值为j的概率估计值
%y_3(i,j)表示在第三类(y=3)的情况下,第i个属性取值为j的概率估计值
for i=1:4
for j=1:5
y_1(i,j)=count_1(i,j)/count1;
y_2(i,j)=count_2(i,j)/count2;
y_3(i,j)=count_3(i,j)/count3;
end
end
end
%做预测,p1,p2,p3分别表示输入值xx为第1,2,3类的概率
cc=0; %用cc表示正确分类的样本
for i=1:l2
xx=data_test(i,:);
yy=label_test(i);
p1=y1*y_1(1,xx(1))*y_1(2,xx(2))*y_1(3,xx(3))*y_1(4,xx(4));
p2=y2*y_2(1,xx(1))*y_2(2,xx(2))*y_2(3,xx(3))*y_2(4,xx(4));
p3=y3*y_3(1,xx(1))*y_3(2,xx(2))*y_3(3,xx(3))*y_3(4,xx(4));
%下面分别输出三类的概率
%ans1=p1/(p1+p2+p3)
%ans2=p2/(p1+p2+p3)
%ans3=p3/(p1+p2+p3)
if p1>p2&&p1>p3
if yy==1
cc=cc+1;
end
end
if p2>p1&&p2>p3
if yy==2
cc=cc+1;
end
end
if p3>p1&&p3>p2
if yy==3
cc=cc+1;
end
end
end
%拿训练集做测试集,得到的正确率
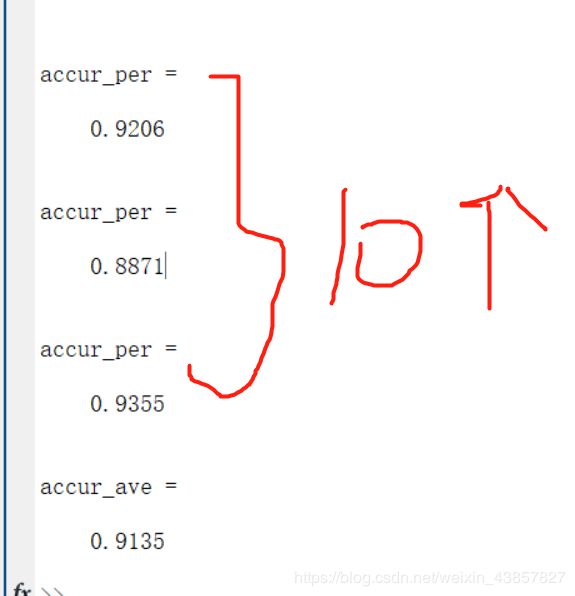
accur_per = cc/l2
accuracy = accuracy + accur_per;
end
accur_ave = accuracy/10
clc
clear
close all
data=importdata('balance-scale.data');
wholeData=data.data;
%交叉验证选取训练集和测试集
cv=cvpartition(size(wholeData,1),'holdout',0.04);%0.04表明测试数据集占总数据集的比例
trainData=wholeData(training(cv),:);
testData=wholeData(test(cv),:);
label=data.textdata;
attributeNumber=size(trainData,2);
attributeValueNumber=5;
%%
%将分类标签转化为数据
sampleNumber=size(label,1);
labelData=zeros(sampleNumber,1);
for i=1:sampleNumber
if label{i,1}=='R'
labelData(i,1)=1;
elseif label{i,1}=='B'
labelData(i,1)=2;
else
labelData(i,1)=3;
end
end
trainLabel=labelData(training(cv),:);
trainSampleNumber=size(trainLabel,1);
testLabel=labelData(test(cv),:);
%计算每个分类的样本的概率
labelProbability=tabulate(trainLabel);
%P_yi,计算P(yi)
P_y1=labelProbability(1,3)/100;
P_y2=labelProbability(2,3)/100;
P_y3=labelProbability(3,3)/100;
%%
%
count_1=zeros(attributeNumber,attributeValueNumber);%count_1(i,j):y=1情况下,第i个属性取j值的数量统计
count_2=zeros(attributeNumber,attributeValueNumber);%count_1(i,j):y=2情况下,第i个属性取j值的数量统计
count_3=zeros(attributeNumber,attributeValueNumber);%count_1(i,j):y=3情况下,第i个属性取j值的数量统计
%统计每一个特征的每个取值的数量
for jj=1:3
for j=1:trainSampleNumber
for ii=1:attributeNumber
for k=1:attributeValueNumber
if jj==1
if trainLabel(j,1)==1&&trainData(j,ii)==k
count_1(ii,k)=count_1(ii,k)+1;
end
elseif jj==2
if trainLabel(j,1)==2&&trainData(j,ii)==k
count_2(ii,k)=count_2(ii,k)+1;
end
else
if trainLabel(j,1)==3&&trainData(j,ii)==k
count_3(ii,k)=count_3(ii,k)+1;
end
end
end
end
end
end
%计算第i个属性取j值的概率,P_a_y1是分类为y=1前提下取值,其他依次类推。
P_a_y1=count_1./labelProbability(1,2);
P_a_y2=count_2./labelProbability(2,2);
P_a_y3=count_3./labelProbability(3,2);
%%
%使用测试集进行数据测试
labelPredictNumber=zeros(3,1);
predictLabel=zeros(size(testData,1),1);
for kk=1:size(testData,1)
testDataTemp=testData(kk,:);
Pxy1=1;
Pxy2=1;
Pxy3=1;
%计算P(x|yi)
for iii=1:attributeNumber
Pxy1=Pxy1*P_a_y1(iii,testDataTemp(iii));
Pxy2=Pxy2*P_a_y2(iii,testDataTemp(iii));
Pxy3=Pxy3*P_a_y3(iii,testDataTemp(iii));
end
%计算P(x|yi)*P(yi)
PxyPy1=P_y1*Pxy1;
PxyPy2=P_y2*Pxy2;
PxyPy3=P_y3*Pxy3;
if PxyPy1>PxyPy2&&PxyPy1>PxyPy3
predictLabel(kk,1)=1;
disp(['this item belongs to No.',num2str(1),' label or the R label'])
labelPredictNumber(1,1)=labelPredictNumber(1,1)+1;
elseif PxyPy2>PxyPy1&&PxyPy2>PxyPy3
predictLabel(kk,1)=2;
labelPredictNumber(2,1)=labelPredictNumber(2,1)+1;
disp(['this item belongs to No.',num2str(2),' label or the B label'])
elseif PxyPy3>PxyPy2&&PxyPy3>PxyPy1
predictLabel(kk,1)=3;
labelPredictNumber(3,1)=labelPredictNumber(3,1)+1;
disp(['this item belongs to No.',num2str(3),' label or the L label'])
end
end
testLabelCount=tabulate(testLabel);
% 计算混淆矩阵
disp('the confusion matrix is : ')
C_Bayes=confusionmat(testLabel,predictLabel)