记第一次使用kaggle的过程
kaggle新手
- 前言
- kaggle流程
- Digit Recognizer项目
- 代码简介
- 训练
- 最后
前言
本编博客内容如下
1.记录第一次使用的大致流程
2.MNIST项目的介绍及代码
kaggle流程
1.认真阅读Overview的的内容,包括但不限于,该项目的基本背景描述(Description),评价准则(Evaluation),截止时间(Timeline),奖金,内核要求(Kernels Requirements)。其中内核要求自己还没用过,个人理解为按要求上传代码进行测试,而非自己提交结果,如有理解错误,欢迎指正。
2.认真阅读Data数据部分,有对主办方提供的数据的描述,对自己的数据处理很重要。
3.还有一些规则可以看看。例如不能有代码泄露出去的要求等。
Digit Recognizer项目
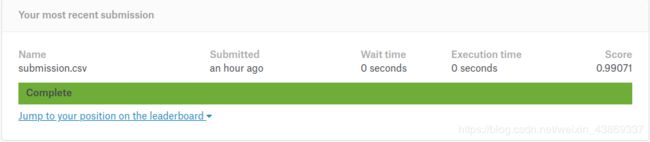
该项目就是MNIST数据的分类问题,用来入门,下面介绍使用pytorch进行分类,随便训练50个epochs,达到99.071%的准确率。
全部代码放在github上
https://github.com/AFOXCOW/Kaggle-MNIST
代码简介
这部分是对代码的简介,由于代码不难,所以会pytorch的可以直接取代码用就行了。
1.数据预处理部分
from torch.utils.data import Dataset
import pandas as pd
import numpy as np
import torch
class mnist_all(Dataset):
def __init__(self,csv_file,transform=None):
self.data_labels = pd.read_csv(csv_file).values
self.transform = transform
def __len__(self):
return len(self.data_labels)
def __getitem__(self,idx):
label = self.data_labels[idx][0]
label = np.array([label])
img_flatten = self.data_labels[idx][1:]
img = img_flatten.reshape((28,28))
img = np.expand_dims(img,axis=0)
train_sample = {'image':img,'label':label}
if self.transform:
train_sample = self.transform(train_sample)
return train_sample
class mnist_test(Dataset):
def __init__(self,csv_file,transform=None):
self.data_labels = pd.read_csv(csv_file).values
self.transform = transform
def __len__(self):
return len(self.data_labels)
def __getitem__(self,idx):
img_flatten = self.data_labels[idx]
img = img_flatten.reshape((28,28))
img = np.expand_dims(img,axis=0)
img = torch.from_numpy(img)
train_sample = {'image':img}
if self.transform:
train_sample = self.transform(train_sample)
return train_sample
class ToTensor(object):
def __call__(self,sample):
img , label = sample['image'],sample['label']
return {'image':torch.from_numpy(img),'label':torch.LongTensor(label)}
这种写法是使用pytorch的dataset的专用写法,只需要按要求构筑好对应的类就可以很方便地使用,具体使用方法pytorch的官网写的很详细了。
https://pytorch.org/tutorials/beginner/data_loading_tutorial.html
可以看到,这里我只是将其转换为图片形式(csv是一维数据),没有多余的操作。
2.模型定义
import torch.nn as nn
class My_VGG(nn.Module):
def __init__(self,num_of_classes):
super(My_VGG,self).__init__()
self.features = nn.Sequential(
#input (1,28,28)
nn.Conv2d(1,64,kernel_size=3),
#(64,26,26)
nn.Conv2d(64,128,kernel_size=3),
#(128,24,24)
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2),
#(128,12,12)
nn.Conv2d(128,256,kernel_size=3),
#(256,10,10)
nn.Conv2d(256,512,kernel_size=3),
#(512,8,8)
nn.ReLU(),
nn.BatchNorm2d(512),
nn.MaxPool2d(kernel_size=2),
#(512,4,4)
)
self.classifier = nn.Sequential(
nn.Linear(512*4*4,1024),
nn.Dropout(),
nn.Linear(1024,512),
nn.Dropout(),
nn.Linear(512,num_of_classes),
)
def forward(self,x):
in_size = x.size(0)
x = self.features(x)
x = x.view(in_size,-1)
x = self.classifier(x)
return x
这里是定义的模型,大家可以根据自己喜好自己写自己的模型,也可以直接加载pytorch自带的模型,但是建议还是自己搭一个比较好,这个项目不需要太复杂的网络都可以达到很好的效果。
训练
由于没有提供验证集,所以我将train.csv的数据分成两部分,这样在训练的过程中也好知道有没有问题(例如过拟合)(验证集有很多用处,其中一个是early stop,但是现在正则化以及dropout很好用,所以early stop很少用了)
#data_loader
all_data = mnist_all('./data/train.csv',transform = transforms.Compose([ToTensor()]))
train_size = int(0.8 * len(all_data))
test_size = len(all_data) - train_size
train_dataset, test_dataset = random_split(all_data, [train_size, test_size])
train_loader = DataLoader(train_dataset,batch_size = args.batch_size,shuffle=True,num_workers=3)
test_loader = DataLoader(test_dataset,batch_size = args.test_batch_size,shuffle=True,num_workers=3)
代码大致流程如下
1.准备数据
2.准备模型
3.准备优化选项
4.对每个epoch,跑一个batchsize就计算一次loss,然后反向传播,再优化参数。
(具体的更多细节在代码中都有体现,基本都可以搜到为什么)
最后
使用方法
python train.py -h
可以看到如何训练以及参数设置
训练好后
python submit.py -h
可以看参数设置(用CPU还是GPU),最后生成符合要求的CSV文件,提交后由kaggle计算得出准确度。
有什么疑问可以留言评论!!
就是这样!!