(连载)词向量的理解——BERT模型的句子向量表示
文章均从个人微信公众号“ AI牛逼顿”转载,文末扫码,欢迎关注!
word embedding的出现提升了自然语言处理的效果。典型的使用场景就是把高质量的词向量输入到的模型中,通过后续的一系列计算,去完成相应的任务。比如文本分类,文本匹配等等。
说到高质量的词向量,这里要给出一个名词:预训练。土豪公司利用大量数据、构造复杂深层的网络结构能够训练出高质量的词向量,然后把结果开放,可以直接拿来用。这比自己用小量数据去获取词向量的效果要好得多。
 这就是预训练的意思。买来就可以吃,也可以根据自己的喜好,再稍微加工一下。(不要流口水哈)
这就是预训练的意思。买来就可以吃,也可以根据自己的喜好,再稍微加工一下。(不要流口水哈)
然而,质量再高,多义词的向量表示依然是笼罩在word embedding头上的一朵乌云。
 不解决多义词的向量表示,智能?智障吧
不解决多义词的向量表示,智能?智障吧
从上篇文章可以看到,同一个单词只占参数矩阵的同一行。这就导致了两种不同的上下文信息都会编码成同一个向量,而这个向量包含了这个词不同的意义。当我们使用这个词的向量表示时,就算明确了词的具体含义,但是取出来的向量只能混合所有词义,那肯定会影响后续任务的效果了。
其次,后续任务一般是对句子甚至是整篇文章的分析。简单的做法就是把每个词的向量加起来,这样就得到了整个句子的向量表示。由于多义词问题的存在,句子向量的表示效果会受到影响。另外,词语的向量相加是不是最好的处理方式呢?
一、解决问题的思路
对于第一个问题,ELMO模型给出了解决思路:
1、先训练好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。
2、在实际使用Word Embedding的时候,单词已经具备了特定的上下文,根据上下文单词的语义去调整单词的Word Embedding表示。这样经过调整后的Word Embedding就能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。
对于第二个问题,GPT模型给出了解决思路:
和上篇文章里训练词向量的方法类似,只是把对象换成了句子,从而可以获得整个句子的向量表示。
关于这两个模型的详细介绍,可以参考文末链接。之所以提到这两个模型,关键在于它们改变了处理后续任务的方式。它们在预训练的基础上,可以直接适用于各种类型的后续任务!词语或者句子的向量表示只是中间结果而已,还顺带着把之前存在的问题给解决了。
接下来要介绍的BERT模型,继承了它们的思路,同时还汲取了上述两个模型的优点:双向编码和Transformer特征提取。关于Transformer的一些细节,可以参考我之前的一篇文章。
二、BERT模型的理解
BERT模型的核心就是预训练过程。其过程也非常简洁:它会先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。其次随机掩盖掉两个句子中的一些词,并要求模型预测这些词是什么,这样就能学习句子内部的关系。最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
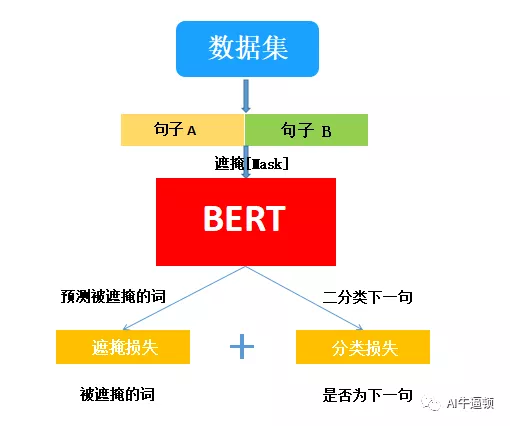 同时完成两个目标的学习:预测被遮掩的词和判断是否为下一句
同时完成两个目标的学习:预测被遮掩的词和判断是否为下一句
其中,预测被遮掩的词是模型的亮点。它没有采用之前介绍的语言模型,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。这种做法和完形填空如出一辙。(至于随机遮掩的一些技巧和处理办法,参考文末链接)
 很多空都是要看到后面才能做出正确的选择。勾起了很不愉快的英语学习回忆
很多空都是要看到后面才能做出正确的选择。勾起了很不愉快的英语学习回忆
说完预训练的目标之后,再来看看数据是以怎样的形式输入到模型里的。
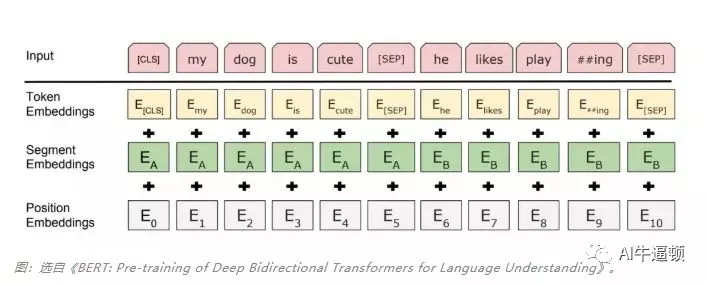
此图从上往下看。最上层是输入的一条数据序列,由两句话组成:
上句:my dog is cute
下句:he likes playing
对输入的句子做一些处理:分词并添加一些标识符。每个句子的最后添加[SEP]标识符,起到分割句子的作用。在第一个句子前面添加[CLS]标识符。这是因为BERT有一个任务是预测B句是不是A句的下一句话,而这个分类任务会借助首句最前面的特殊符 [CLS] 实现,该特殊符可以视为汇集了整个输入序列的表征。
图片中,横线下方有三类向量:标记向量、分割向量、位置向量。标记向量可以理解为就是普通的词向量;分割向量用来表示上句和下句;位置向量能反映各个标记在句子中词序信息。把这三类向量相加,传入到Transformer架构中。
预训练的原理差不多就是这些。真正使用的时候,只需按照不同的任务,把数据按照模型要求的格式准备好就可以了,确实省心不少。更省心的是,不论后续是什么类型的任务(序列标注、分类任务、句子关系判断、生成任务),BERT模型一概通吃!!!(代码使用的细节参考文末链接)
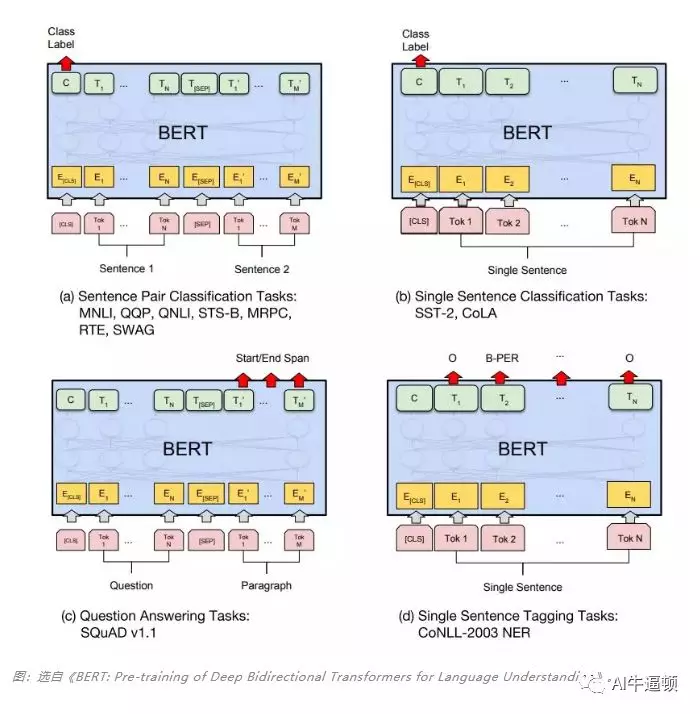 此图是作者根据后续的不同任务,给出的BERT模型的使用办法
此图是作者根据后续的不同任务,给出的BERT模型的使用办法
(a)图输入两个句子,利用最上层的C向量,能解决两个句子关系的判别任务;
(b)图输入单个句子,也是利用最上层的C向量,能解决单个句子的分类任务;
(c)图输入两个句子,利用最上层第二个句子的输出向量,能解决问答或者自动生成的任务。
(d)图输入单个句子,利用最上层每个token的输出向量,能解决序列标注的任务。
三、BERT模型的初步尝试
下面是我尝试BERT模型的结果,做的任务是判断两个句子间的关系。做法比较简单,加载预训练好的中文BERT模型;利用训练数据微调BERT模型里的参数;然后就是在验证集上查看效果;最后就是在测试集上进行测试了。
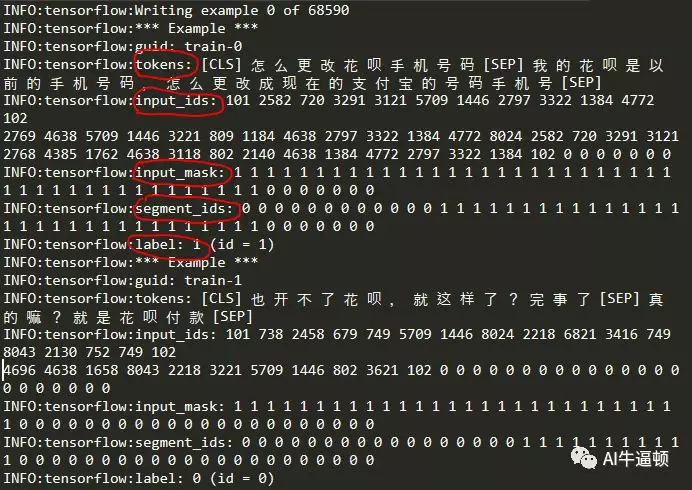 训练开始时返回的信息
训练开始时返回的信息
一共有68590条训练数据,返回的信息含义如下:
1、tokens:按字分割,并添加[CLS]和[SEP]标识符;
2、input_id:各个tokens在字典里的序号;最后有几个0,因为这里设置了固定的输入长度,句子长度不够的,要填充补齐。
3、input_mask:标记为1的是要随机遮掩的,至于是哪些被遮掩,这里体现不出来。同样的,后续有些0也是填充补齐,0不被遮掩。
4、segment_ids:前面是0,后面是1,用来区分上句和下句。1后面还有部分0,也是填充补齐。
5、label:0或者1。0表示不是上下句关系,1表示是上下句关系。图中的第一个Example的label值为1,第二个Example的label值为0。
四、后记
慢,真的很慢!就这么一点数据量,一个通宵还不能在自己的笔记本上完成训练。也只有土豪公司才能玩得起、玩得好这么复杂的模型。后续的尝试还在进行中。。。。。。

千里之行始于足下!定期分享人工智能的干货,通俗展现原理和案例实现,并探索案例在中学物理教育过程中的使用。还有各种有趣的物理科普哟。 坚持原创分享!坚持理解并吸收后的转发分享! 欢迎大家的关注与交流。
参考链接
https://mp.weixin.qq.com/s/vFdm-UHns7Nhbmdoiu6jWg
https://blog.csdn.net/u012526436/article/details/84637834
https://blog.csdn.net/qq_39521554/article/details/83062188
https://zhuanlan.zhihu.com/p/49271699