【数据库】作业5——SQL练习2 - INDEX / INSERT / SELECT
- INDEX:【例3.13】~【例3.15】
- INSERT:【例3.69】~【例3.71】REF:使用 INSERT INTO - VALUES 插入数据
- SELECT:【例3.16】~【例3.28】REF:教材3.4“数据查询”的部分例题
建表&插入数据
1. 在SQLserver上运行,观察运行效果,并把代码写到作业中。
2. 写出自己的理解/收获/心得体会(部分比较复杂的例题,建议增加测试方法和测试数据,举一反三)。
作业原地址:作业
-
INDEX
1.建立索引
使用CREATE INDEX语句
CREATE [UNIQUE] [CLUSTERER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);
<表名>:是要建索引的基本表的名字。
索引:可以建立在该表的一列或多列上,各列名之间用逗号分隔。
<次序>:可选ASC(升序)或DESC(降序),默认为ASC。
UNIQUE:表示此索引的每一个索引值只对应唯一的数据记录。
CLUSTER:表示要建立的索引是聚簇索引。(插眼——详细概念在7.5.2)
2.修改索引
对于已经建立的索引,如果需要对其进行重命名,可以使用ALTER INDEX语句
ALTER INDEX <旧索引名>RENAME TO<新索引名>;
3.删除索引
删除索引使用DROP INDEX 语句
DROP INDEX <索引名>;
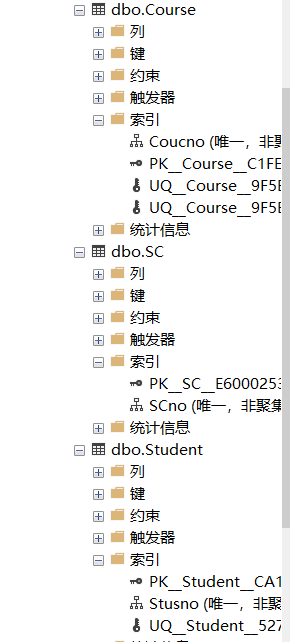
【例3.13】为学生-课程数据库中的Student,Course和SC三个表建立索引。Student表按学号升序建唯一索引,Course表按课程号升序建唯一索引,SC表按学号升序和课程号降序建唯一索引。
CREATE UNIQUE INDEX Stusno ON Student(Sno);
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
截图:
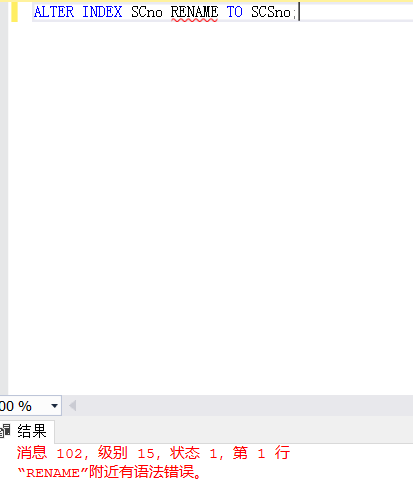
【例3.14】将SC表的SCno索引名改为SCSno。
ALTER INDEX SCno RENAME TO SCSno; /*×有问题×*/
好像又出错了...
!插眼修改索引
原因:alter不能改变索引名,如若改变索引名就需要调用存储过程。
更改:
EXEC sp_rename @objname = 'student.stusno1', @newname = 'stusno2', @objtype = 'index'
/*或者如下*/
EXEC sp_rename '表名.旧索引名', '新索引名', 'index'
原文链接:https://blog.csdn.net/weixin_30540691/article/details/101091086?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522158426904519725219926872%2522%252C%2522scm%2522%253A%252220140713.130056874..%2522%257D&request_id=158426904519725219926872&biz_id=0&utm_source=distribute.pc_search_result.none-task
更换代码:
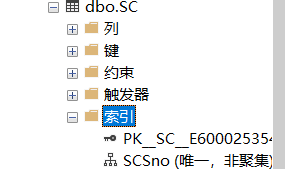
EXEC sp_rename 'SC.SCno', 'SCSno', 'index'
修改成功:
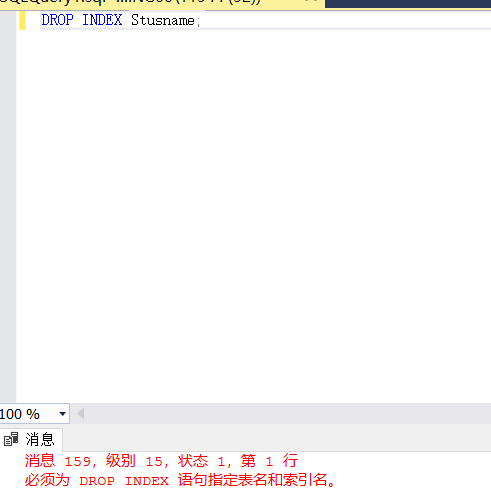
【例3.15】删除Student表的Stusname索引。
DROP INDEX Stusname; /*×有问题×*/
又出错了...
!插眼删除索引

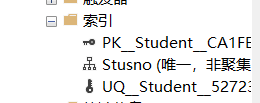
报错里说要指定表名和索引名,所以试试<表名>.<索引名>,而且Student的索引里没有Stusname,只有Stusno,所以
更换代码:
DROP INDEX Student.Stusno;
删除成功:

-
INSERT
插入元组的INSERT语句的格式:
INSERT INTO<表名>[(<属性列1>[,<属性列2>]…)]
VALUES(<常量1>[,<常量2>…]);
其功能是将新元组插入指定表中。
INTO子句中没有出现的属性列,新元组在这些列上将取空值,
注意:在表定义时说明了NOT NULL 的属性列不能取空值,否则会出错。
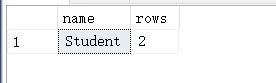
【例3.69】将一个新学生元组(学号:201215128,姓名:陈冬,性别:男,所在系:IS,年龄:18岁)插入到Student中。
INSERT
INTO Student (Sno,Sname,Ssex,Sdept,Sage)
VALUES ('201215128','陈冬','男','IS',18);
【例3.70】将学生张成民的信息插入到Student表中。
INSERT
INTO Student
VALUES('201215126','张成民','男',18,'CS');
【例3.71】插入一条选课记录(‘201215128’,‘1’)。
INSERT
INTO SC(Sno,Cno)
VALUES('201215128','1');新插入的记录的Grade列上自动地赋空值。
或者:
INSERT
INTO SC
VALUES('201215128','1',NULL);没有指出SC的属性名,在Grade列上要明确给出空值。
以上三例结果:
-
SELECT
数据查询是数据库的核心操作。
SELECT [ALL|DISTINCT]<目标列表达式>[,<目标列表达式>]…
FROM<表名或者视图名>[,<表名或视图名>…]|(
[WHERE<条件表达式>]
[GROUP BY<列名1>[HAVING<条件表达式>]]
[ORDER BY<列名2>[ASC|DESC]];
SELECT语句含义:根据WHERE子的条件表达式从FROM子句指定的基本表、视图或派生表中找出满足条件的元组,再按 SELECT子句中的目标表达式选出元组中的属性值形成结果表。
1.选择表中的若干列
(1)查询指定列
【例3.16】查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM Student;
截图:

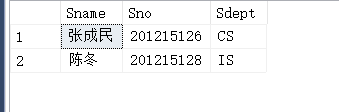
【例3.17】查询全体学生的姓名、学号、所在系。
SELECT Sname,Sno,Sdept
FROM Student
截图:
(2)查询全部列
【例3.18】查询全体学生详细记录。
SELECT *
FROM Student; 等价于:
SELECT Sno,Sname,Ssex,Sage,Sdept
FROM Student;
截图:
(3)查询计算过程
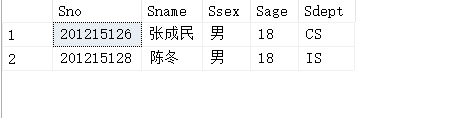
【例3.19】查询全体学生的姓名及其出生年份。
SELECT Sname,2014-Sage /*查询结果的第二列是一个算术表达式*/
FROM Student;
截图:
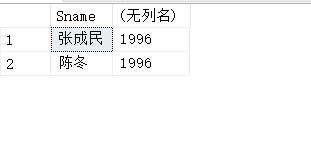
【例3.20】查询全体学生的姓名、出生年份和所在的院系,要求用小写字母表示系名。
SELECT Sname,'Year of Birth:',2014-Sage,LOWER(Sdept)
FROM Student;
截图:
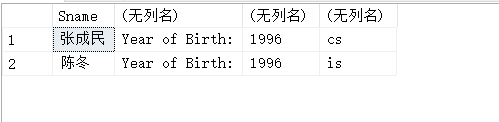
用户可以用个指定别名改变查询结果的列标题。
SELECT Sname NAME,'Year or Birth:'BIRTH,2014-Sage BIRTHDAY,
LOWER(Sdept)DEPERTMENT
FROM Student;
截图:

2.选择表中的若干元组
(1)消除取值重复的行
【例3.21】查询选修了课程的学生学号
SELECT Sno
FROM SC;
因为我几个例题删除重做了好几次,做到这儿的时候发现有些数据不小心弄丢了,所以以下例子均已做,不发截图了。
删掉重复行:
SELECT DISTINCT Sno
FROM SC;
(2)查询满足条件的元组
①比较大小
【例3.22】查询计算机科学系全体学生的名单。
SELECT Sname
FROM Student
WHERE Sdept='CS';
【例3.23】查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
【例3.24】查询考试成绩不及格的学生的学号。
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
注:这里使用了DISTINCT 语句,当一个同学有多门课程不及格,他的学号也只列一次。
②确定范围
【例3.25】查询年龄在20~23岁(包括20和23)之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
【例3.26】查询年龄不在20~23岁之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND 23;
③确定集合
【3.27】查询计算机科学系(CS)、数学系(MA)、信息系(IS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN('CS','MA','IS');
【3.28】查询不是计算机科学系(CS)、数学系(MA)、信息系(IS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept NOT IN('CS','MA','IS');
总结:这次作业感觉还可以,语句都还短还简单,也没有什么需要特别注意的。唯一麻烦的就是一点一点敲代码,这次截图已经 减少很多了,切屏、截图的时间省下了不少,时间基本都是在敲代码,例题太多了(哭哭哭)。
又遇见了两个错误,通过查资料也全都解决了。
出现的问题就是中英文总出错,中文的()和英文的()超难区分,错了还一时照不出来,得加小心了。
后半段出现了个问题,有些地方出了问题或者不懂,我总会删除之前的数据重新再写一遍,然后就可能在哪里不小心弄丢了一些内容,导致接下来的操作全都有影响。
上期传送阵:【数据库】作业4——SQL练习1 - CREATE / DROP / ALTER
下期传送阵:————
插眼传送:
!插眼修改索引
!插眼删除索引
完成时间:2h25min
以上
————(2020.3.15)