超越MobileNetV3!Facebook提出更轻更快的FBNetV2
关注上方“深度学习技术前沿”,选择“星标公众号”,
资源干货,第一时间送达!

作者:dwilimeth
知乎链接:https://zhuanlan.zhihu.com/p/132533771
本文仅供参考学习,如有侵权,请联系删除!

- 论文:https://arxiv.org/abs/2004.05565
- 代码(即将开源):https://github.com/facebookresearch/mobile-vision
今天介绍一篇 Facebook 工作 FBNet 的升级版本 FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions。
本文的搜索空间相比于 FBNet 提升了将近 倍,搜到了一个和 EfficientNet B0 精度接近,但是 FLOPs 小了 20% 的网络结构。代码会开源在 Github。
Motivation
首先回顾一下基于 DARTS 的这种可微分的网络结构搜索方法 (Differentiable Neural Architecture Search) :一般是构造一个包含所有候选结构的超图 (super graph),然后从中选一条 single path 做为最终的网络结构。
作者指出,基于 DARTS 的方法有两个缺点:
1. 搜索空间相对较小。由于要把很大的 super graph 以及 featuremap 存在 GPU 上,显存的限制就使得 DARTS 系列方法的搜索空间,比基于 RL,进化算法方法的搜索空间要小;
2. 搜索代价会随着每层的选择的增加线性增长。每在 supergraph 中增加一个新的搜索维度,显存和计算量都会大幅增长,这也就制约了搜索空间不能太大。
作者的改进方向就是在几乎不引入显存和计算量代价的情况下,相比于 FBNet,搜索空间加入了 channels 和 input resolution 两个维度,从而把搜索空间提升了将近 倍。怎么做到的呢?主要是两点改进:
1. 对 supergraph 中的 channel / input resolution 选项加入 mask
2. 复用 supergraph 中所有选项的 featuremap
下面进行详细的介绍。
Channel Search
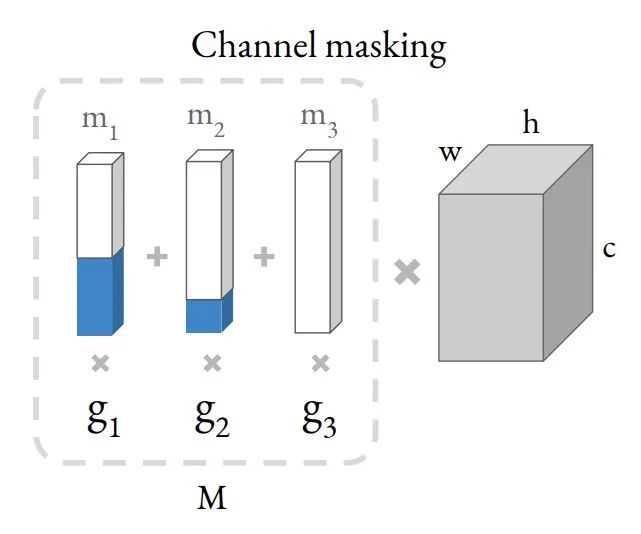 channel masking机制
channel masking机制
把不同的 channel 加入搜索空间,之前的 DNAS 系列方法就是把不同的选项融进 supergraph,这样会带来接近 种选择的可能。为了减少搜索 channel 时候的计算量,作者构造了 channel masking的机制,把不同 channel 的最终输出,表征为和一个 mask 相乘的形式。
具体的做法如上图所示。右边那个灰色的长方体表示一个 shape 为 (c, h, w) 的 tensor,和左边的 mask 向量 M 相乘的结果。M 可以拆解为多个 mask 和对应的 Gumbel Softmax 的系数 的乘积和。通过调节左边的 mask,就能得到等价的不同 channel 的结果。相当于对一个大的 tensor,mask 掉额外的 channel,得到相应的别的 channel 的结果。

想要进行加权和,首先就会遇到上图 Step A 中的问题:channel 不同,对应的 tensor shape 不用,无法直接相加。为了解决这个问题,可以引入 Step B 中的方法:对输出做 zero padding,使之shape 对齐(也就是图中蓝色部分),然后就可以加权和了。Step B 和 Step C 是等价的。Step C 相当于对卷积的 filter 进行 mask。随后作者又进行了一个简化的假设,假设所有的 weighting 共享,也就是 Step D 的形式。Step E 和 Step D 是等效的,即为最终的 channel masking 机制。
Input Resolution Search
 spatial subsampling 机制
spatial subsampling 机制
上面说了在 channel 维度的做法。在 Spatial 维度的做法也是类似的,作者也想构造一种加权和的形式表征不同分辨率的 feature。如上图 A 所示,不同分辨率的 tensor 不能直接相加。图 B 说明了在边缘 padding 的方式不行,pixel 无法对齐。图 C 说明了为了让 pixel 对齐,要采用这种 Interspersing zero-padding 的形式。但是图 C 这种方式会又带来感受野 mis-alignment 的问题:如图 D 所示,Interspersing zero-padding 之后,一个 3x3 的 kenel 有效感受野变成了 2x2。所以图 E 才是作者最终的解决方法:和 F 运算完之后再 padding。
Search Space
通过上述的Channel masking 和 Resolution subsampling 机制,FBNet V2 的搜索空间就可以在 channel 和 spatial 维度扩展了。FBNet V2有三个不同的系列:FBNetV2-F, FBNetV2-P, FBNetV2-L。分别对应的优化目标为Flops,参数量和大模型。下表是大模型 FBNetV2-P 的搜索空间:

输入为288x288x3。channel 维度的搜索体现在表格种的 number of filters f,比如说可能是 16 到 28 之间步长为 4 的一个值。spatial 维度的搜索体现在表格中的block expansion rate e,从 0.75 到 4.5,步长为 0.75。
TBS 就是指待搜的 block。这些 TBS 对应的 block 具体的搜索空间如下表:

可以看出,组成的 block type 就是由 3x3 或者 5x5 的 depth-wise conv + SE + relu / hswith 组成。
这三个系列最后搜出来的结果,在 ImageNet 上的结果如下表:
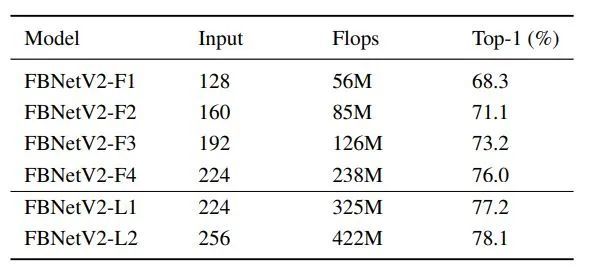

同样是以 FBNetV2-P 为例子,和其他方法的对比如下图:


总结一下,本文的贡献点主要在于提出了一种 channel 维度的 mask 机制 和 spatial 维度的 subsampling 机制,能扩大 DNAS 系列方法的搜索空间,同时几乎不增加显存和计算开销。
重磅!DLer-计算机视觉交流群已成立!
欢迎各位Cver加入计算机视觉微信交流大群,本群旨在交流图像分类、目标检测、点云/语义分割、目标跟踪、机器视觉、GAN、超分辨率、人脸检测与识别、动作行为/时空/光流/姿态/运动、模型压缩/量化/剪枝、NAS、迁移学习、人体姿态估计等内容。更有真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流等,欢迎加群交流学习!
进群请备注:研究方向+地点+学校/公司+昵称(如图像分类+上海+上交+小明)
广告商、博主请绕道!

???? 长按添加,邀请您进群!