作者:佐治亚理工学院(美国)
1 引言
以机器翻译为例子说明,传统的encoder-decoder框架使用的RNN,有两个明显的缺点:
(1)RNN具有遗忘性,经过几个时间步之后,老的信息会被遗忘;
(2)没有清晰的词对齐,是散乱的。
2 公式化
一般形式:

其中a的形式有如下几种:(其实还存在很多形式,作者并未全部列出。)
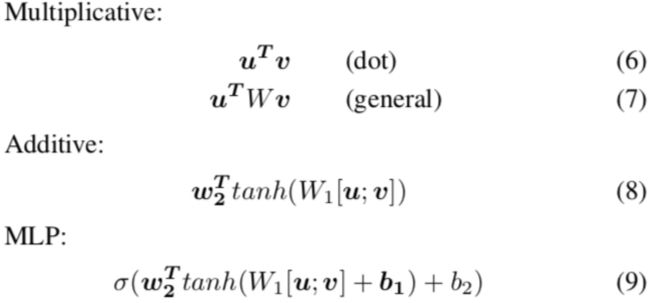
3 变化
在下面这种情况下,attention无法直接将Q与(3)对应上:

所以需要更复杂的attention去处理这种情况:

3.1 Multi-dimensional Attention
前面第2节介绍的通常我们称为1D Attention或者vector Attention,这点也是很好理解的。
使用Multi-dimensional的动机是为了获取多维度的信息。

这个表里面是1D扩展为2D的例子。
drawback:虽然multi-attention方法能够同时获取多维度的信息,但是其表示能力会下降。
sloutions: 在2D attention矩阵上加F范数来进行约束。
3.2 Hierarchical Attention

在这小节里,比较出名的是HAN,这种NAACL2016的一篇用来做文档分类的文章,比较具有代表性。HAN的结构是从
bottom-up构建的。
另外,还有一个GEC任务上的基于Top-down构建的。
3.3 Self Attention
这就是大名鼎鼎的,也是最近在NLP上取得比较大进步的技术方案。具体的细节这里不做过多赘述,主要从两个例子来说明Self-attention的作用。
(1)Self-attention被称为internal attention
example:Volleyball match is in progress between ladies
这里的match是这句话的头,是所有其他词的中心,所以我们希望attention学到这种内部固有的依赖关系。
(2)Self-attention与word embedding是相关的。
example:
I arrived at the bank after crossing the street
I arrived at the bank after crossing the river
这里的单词bank在不同的上下文情况下有不同的意思,所以我们希望模型能学到带有上下文语义信息的token embeddings。
其中的Transformer就是一个很好的例子。
3.4 Memory-based Attention
这里对应到前面给的那个例子,很有意思。提到Memory,就是模型要存储一些信息到memory里。这里的例子可以很好的说明:

Figure2 是具体的过程,Figure3是真实的例子说明。
3.5 Task-specific Attention
这些具体的任务是将attention的思想应用到其中,并且取得一定效果。具体的有:自动摘要、结构化的attention网络、机器翻译里的local attention模型等等。
其中的自动摘要中的attention思想是指:一篇文章中最重要的句子,肯定与其他重要的句子有更显著的linked。
4 Application
其实上面已经提到了Attention的很多NLP应用了,可以认为这里是更进一步的补充。
4.1 Attention for Ensemble
很显然能够想到在Ensemble中使用attention思想。
4.2 Attention for Gating
本人对这个应用影响比较深刻的是另外一篇文章,有兴趣的可以去参考:名字暂时忘记了,后期不上。
其主要思想在input上增加了attention机制。
4.3 Attention for Pre-training
这里当然要提到最近才出现的BERT,这是近几年NLP上的一些技术的集大成者,也给我一些人生路上的思考。
BERT模型使用的训练语料和模型都是很大的,这就好比人生路上的经历,当你经历了很多之后,才能去掉糟粕,留下精华。在需要的时候发挥巨大的作用,就像BERT模型在11项任务上都取得很好的性能一样。
但是BERT模型仍有它的不足,当遇到复杂的问题时,这些预训练好的模式并不一定能适用。这也就好比即使你经历再多,遇到棘手的问题时,仍然需要付出一定的努力才能攻克。