CVPR2020论文解读:CNN合成的图片鉴别
CVPR2020论文解读:CNN合成的图片鉴别
《CNN-generated images are
surprisingly easy to spot… for now》


论文链接:https://arxiv.org/abs/1912.11035
代码链接:https://peterwang512.github.io/CNNDetection/
该文章被CVPR2020录用,Arxiv公开于2019年12月,作者来自 UC Berkeley 和 Adobe Research。
CNN 生成的图像与真实图像很难分辨吗?来自 Adobe 和加州伯克利的研究者发现,仅仅在一种 CNN 生成的图像上进行训练的分类器,也可以检测许多其他模型生成的结果。或许,GAN 和
Deepfake 在「瞒天过海」上也不是万能的。
近来,诸如生成对抗网络(GAN)的深度图像生成技术快速发展,引发了公众的广泛关注和兴趣,但这也使人们担心,会逐渐走入一个无法分辨图像真实与否的世界。
这种担忧尤其体现在一些特定的图像操纵技术上,例如用来进行面部风格替换的「Deepfake」,以及逼真的人像生成。其实这些方法仅仅是一种广泛应用技术中的两个实例:基于卷积神经网络(CNN)的图像生成。
《CNN-generated images are
surprisingly easy to spot… for now》提出,即使是在一种 CNN 生成的图像所训练的分类器,也能够跨数据集、网络架构和训练任务,展现出惊人的泛化能力。这篇论文目前已被 CVPR 2020 接收,代码和模型也已公布。
这篇论文主要探索如何利用单一的GAN模型来鉴别其他各种GAN生成的图像。无论各种GAN生成的图像是何种类型,使用何种网络结构,合成的假图都用相同的缺陷。作者首先利用11种GAN模型来构造一个大规模的合成图像鉴别数据库,ForenSynths Datsets。之后仅仅利用单一的ProGAN模型来训练,就能够在ForenSynths上表现出良好的泛化性能,甚至可以打败新出的StyleGAN2和DeepFake。通过实验表明数据增强作为后处理方法,以及训练数据的多样性是成功的关键,尤其是数据增强使得训练一个鉴别器就有良好的泛化能力和鲁棒性。这篇论文收录在CVPR 2020,是反造假技术再进一步的标志。造假和反造假技术一直在共同进步。
在这项工作中,研究者希望找到一种用于检测 CNN 生成图像的通用图像伪造检测方法。检测图像是否由某种特定技术生成是相对简单的,只需在由真实图像和该技术生成的图像组成的数据集上训练一个分类器即可。

但现有的很多方法的检测效果很可能会与图像生成训练中使用的数据集(如人脸数据集)紧密相关,并且由于数据集偏差的存在,一些方法在新数据(例如汽车)测试时可能泛化性较差。更糟糕的是,随着图像生成方法的发展,或是用于训练的技术被淘汰,这种基于特定生成技术的检测器可能会很快失效。
所以 CNN 生成的图像是否包含共同的伪造痕迹呢?例如某种可检测的 CNN 特征,这样就可以将分类器推广到整个生成方法族,而不只是针对单个生成方法。一般来说,泛化性确实一直是图像伪造检测领域的难题。例如,最近的一些工作 [48,13,41] 观察表明,对某一种 GAN 架构所生成图像进行训练的分类器在其他架构上进行测试时性能较差,并且在许多情况下,仅仅训练数据集的改变(而非架构或任务)就会导致泛化失败 [48]。这是有道理的,因为图像生成方法千差万别,它们使用的是不同的数据集、网络架构、损失函数和图像预处理方式。
但研究者发现,与当前人们的理解相反,为检测 CNN 生成的图像所训练的分类器能够跨数据集、网络架构和训练任务,展现出惊人的泛化能力。在本文中,研究者遵循惯例并通过简单的方式训练分类器,使用单个 CNN 模型(使用 ProGAN,一种高性能的非条件式 GAN 模型)生成大量伪造图像,并训练一个二分类器来检测伪造图像,将模型使用的真实训练图像作为负例。
此外,本文还提出了一个用于检测 CNN 生成图像的新数据集和评价指标,并通过实验分析了影响跨模型泛化性的因素。
基于 CNN 生成模型的数据集
研究者创建了一个 CNN 生成图像的新数据集「ForenSynths」,该数据集由 11 种模型生成的图像组成,从非条件式的图像生成方法(如 StyleGAN)到超分辨率方法,以及 deepfake。每个模型都在适合其特定任务的不同图像数据集上进行训练。研究者还继续在论文撰写后发布的模型上评估检测器,发现它可以在最新的非条件式 GAN——StyleGAN2 实现开箱即用。
实验:检测 CNN 生成的图像
鉴于数据集中的非条件式 GAN 模型可以生成任意数量的图像,研究者选择了一种特定的模型 ProGAN 来训练检测器。使用单一模型进行训练,这个方法与现实世界中的检测问题极为相似,即训练时并不清楚需要泛化模型的多样性和数量。
接着,研究者创建了一个仅由 ProGAN 生成的图像和真实图像组成的大规模数据集。使用 20 个模型,每个模型在不同的 LSUN 物体类别上进行训练,并生成 36K 的训练图像和 200 张验证图像,每个模型所用的真实和伪造的图像数量是相等的。一共有 720K 图像用于训练、4K 图像用于验证。
这一实验的主要思想是在这个 ProGAN 数据集上训练一个判断「真实或伪造」的分类器,并评估该模型对其他 CNN 合成图像的泛化效果。在分类器的选择上,使用了经过 ImageNet 预训练的 ResNet-50,并在二分类的设定下进行训练。
亮点:该工作意图探究深度生成取证泛化能力可能性。从训练数据的多样性、数据增强技术做探讨,说明了一定强先验条件下,泛化能力是可能的(AP衡量)。该文章做了偏基础的探究性实验工作。
缺陷:
-
这种泛化效果的先验假设是,测试的样本都是同一种伪造技术,这是不满足实际应用环境的。 -
对衡量指标AP的阈值threshold,和准确率Acc.未做讨论,未说明是否会存在较大的数据集之间的bias偏差。
思考:
-
训练用的是ProGAN,内容是场景,非人脸 -
SAN 超分辨率很难检测,说明其有较强的篡改噪声能力,是否能加以利用? -
Deepfake的泛化效果较差,因为经过强手工设计,并非ProGAN类似全局CNN图片生成。 -
对Photoshop类似的算法无效。
Introduction
通用的检测器、用11种CNN生成技术的数据集、预处理和后处理、数据增强。
“针对生成技术的共有特征”为出发点,公布了以11种生成方法生成的的测试集“ForenSynths”,包含GAN生成、超分辨率、手工设计的Deepfakes。以ProGAN用作训练,采用特定数据增强的前/后处理方法,能带来泛化能力和鲁棒性。
- Related work
分三部分:检测CNN生成的技术、图像取证、CNN生成的共有特征。
CNN生成的共有特征:因为CNN的结构相似,导致生成的结果存在一种相似模式,举例为上采样和下采样。
- A dataset of CNN-based generation models
训练尺寸:224x224的随机裁剪(数据集尺寸为256x256)
- Detecting CNN-Synthesized images
4.1 Training classifiers
用ProGAN训练,探究泛化能力的上界;
采用ProGAN训练的原因:生成图像分辨率高、网络结构简单
ProGAN训练集用了20种LSUN类别:相当于20种生成的类型,airplane、cat…
每类别36K训练图片,20种一共720k训练图片
网络结构:预训练的ResNet-50+二分类
数据增强:随机翻转+224x224随机裁剪;同时Blur和JPEG压缩划分了几个等级。
衡量指标:AP,对不同数据集单独衡量,而非混合在一起(存在潜在数据集偏差问题,未做探究)
4.2 Effect of data augmentation
泛化性(训练数据增强,测试不处理)

鲁棒性(训练、测试同时处理)

4.3 Comparison to other methods
面对整张图片全由CNN生成的图片,效果较好;面对SAN和Deepfake,泛化表现较差。
4.4 New CNN models
对新出的StyleGAN2同样有效。

4.5 Other evaluation metrics
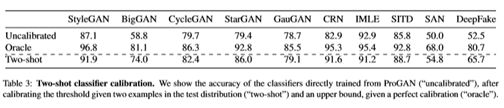
将Acc拿出来,比较真实应用场景下,有两张测试环境图片,估计阈值的情况。
Oracle表示准确率的上界,Two-shot表示拿测试集的两张图片“校准”后的准确率。注意这里的校准的含义是阈值的选取,而并非微调。
- 测试结论
CNN生成方法当前存在能检测的通用“水印”,但不代表未来也可行,因为生成技术会持续进步,甚至补齐此缺陷;
真实场景(In
the wild)下,认真的攻击者会选择生成效果优良的结果,放在网络上,检测难度更大;
对Photoshop类似篡改算法测试来看,face-aware liquify dataset上,作者的分类器表现如随机选择一般;
测试结果
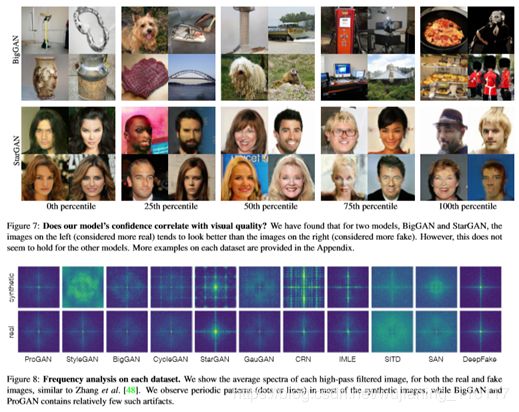
先是在测试集上,肉眼观察分类器判定的效果。作者把质量分成五个等级,上图从左至右分别真实性预测变差。
后续做了频谱分析,发现CNN生成的方法,在傅里叶变换频谱上,可能会呈现周期性的特性。(然而SAN和Deepfake比较正常,可能因为其经过手工设计,并非完全CNN生成。)
两个方面,ProGAN的不同类别、不同生成技术(换BigGAN做训练)
LSUN的20个类别,分别对应不同生成物品/物种种类,比如airplane、cat…
对比400k个图片BigGAN的训练结果:也有一定泛化能力,但效果没ProGAN好。
表 2:跨生成器的泛化结果。图中展示了 Zhang 等人提供的基线和本文模型在不同分类器上的平均准确度(AP),共 11 个生成器参与测试。符号 X 和 † 分别表示在训练时分别以 50%和 10%的概率应用数据增强。随机表现是 50%,可能的最佳表现是 100%。在测试用的生成器被用于训练时,结果显示为灰色(因为它们不是在测试泛化性)。黑色的值表示跨生成器的泛化性结果。其中,最高值以黑色加粗显示。通过减少数据扩充,研究者展示了针对 ProGAN 中较少类的消融实验结果。同时通过平均所有数据集的 AP 分数来得到 mean AP。
