spark部分:算子大总结
spark部分算子的分类:
一.transformation类算子
flatmap
map
flatmap

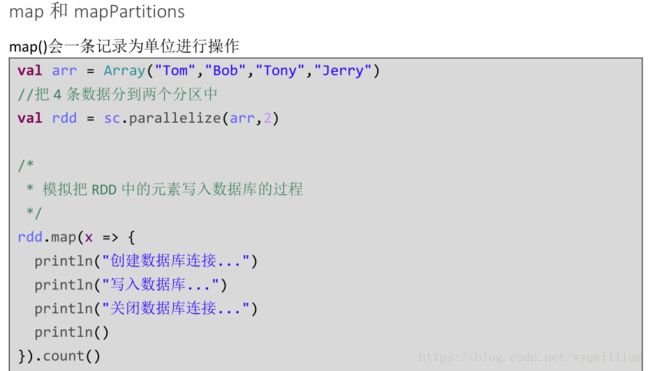
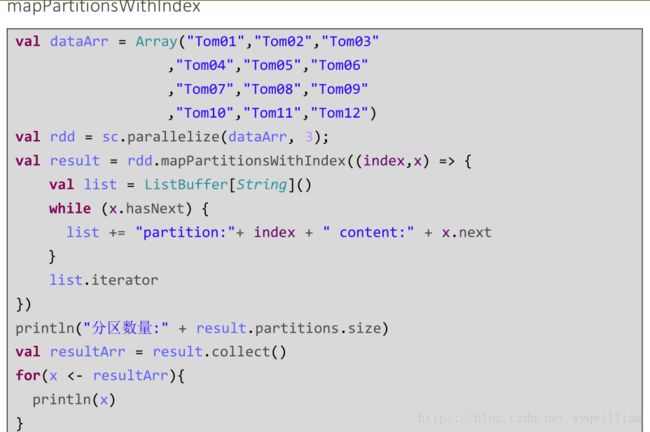
mappartitions
aggregatebykey
combinebykey
reducebykey
groupbykey
filter
val rdd = sc.makeRDD(Array("hello","hello","hello","world"))
rdd.filter(!_.contains("hello")).foreach(println)
结果:
worldsample
val rdd = sc.makeRDD(Array(
"hello1","hello2","hello3","hello4","hello5","hello6",
"world1","world2","world3","world4"
))
rdd.sample(false, 0.3).foreach(println)
结果:
hello4
world1
在数据量不大的时候,不会很准确union
sortByKey:按 key 进行排序
val rdd = sc.makeRDD(Array(
(5,"Tom"),(10,"Jed"),(3,"Tony"),(2,"Jack")
))
rdd.sortByKey().foreach(println)
结果:
(2,Jack)
(3,Tony)
(5,Tom)
(10,Jed)
说明:
sortByKey(fasle):倒序sortby:自定义排序规则
object SortByOperator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestSortBy").setMaster("local")
val sc = new SparkContext(conf)
val arr = Array(
Tuple3(190,100,"Jed"),
Tuple3(100,202,"Tom"),
Tuple3(90,111,"Tony")
)
val rdd = sc.parallelize(arr)
rdd.sortBy(_._1).foreach(println)
/* (90,111,Tony)
(100,202,Tom)
(190,100,Jed)
*/
rdd.sortBy(_._2).foreach(println)
/*(190,100,Jed)
(90,111,Tony)
(100,202,Tom)
*/
rdd.sortBy(_._3).foreach(println)
/*
(190,100,Jed)
(100,202,Tom)
(90,111,Tony)
*/
sc.stop();
}
}distinct:去掉重复数据


join:
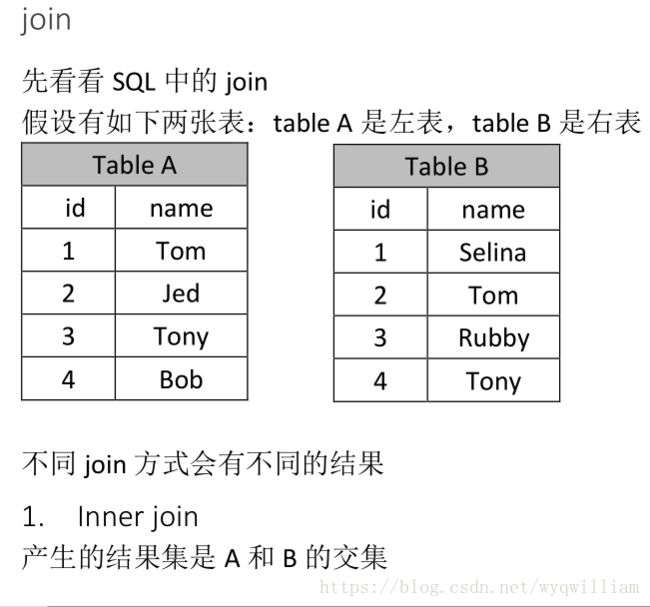
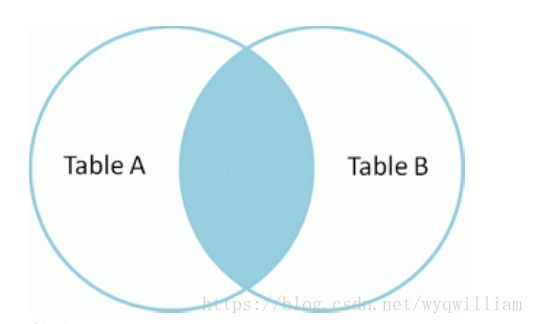
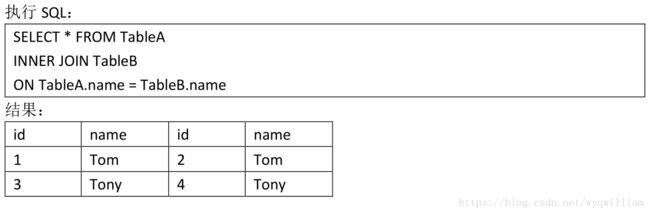

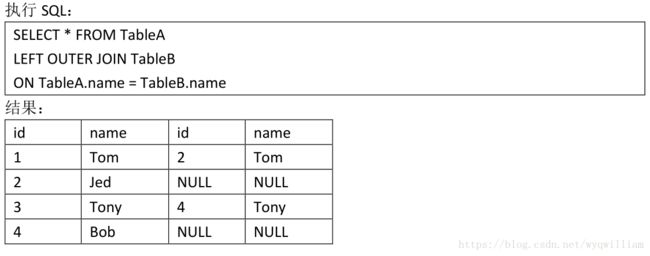


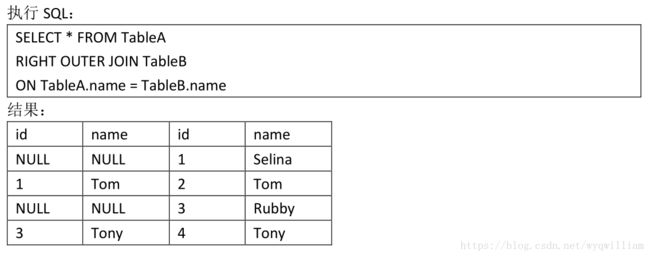

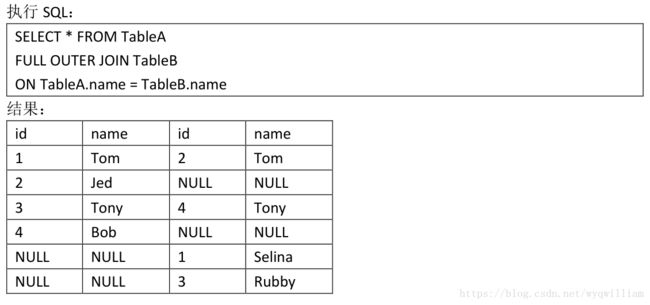
单纯join的时候,是按照rdd中partition最少的rdd来定义的,相当于inner join(个人观点)



下图说明了三种 coalesce 的情况:
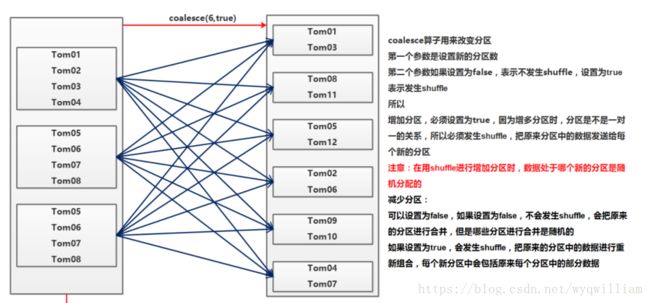


repartition:改变 RDD 分区数
repartition(int n) = coalesce(int n, true)



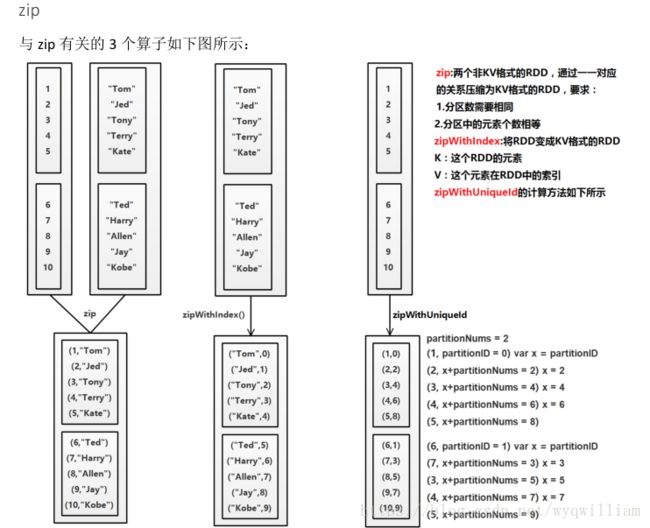
二.action算子
count:统计 RDD 中元素的个数
foreach:遍历 RDD 中的元素
foreachpartitions
foreach 以一条记录为单位来遍历 RDD
foreachPartition 以分区为单位遍历 RDD
foreach 和 foreachPartition 都是 actions 算子
map 和 mapPartition 可以与它们做类比,但 map 和 mapPartitions 是 transformations 算子
collect:把运行结果拉回到 Driver 端
take(n):取 RDD 中的前 n 个元素
first :相当于 take(1)
reduce:按照指定规则聚合 RDD 中的元素
val numArr = Array(1,2,3,4,5)
val rdd = sc.parallelize(numArr)
val sum = rdd.reduce(_+_)
println(sum)
结果:
15countByKey:统计出 KV 格式的 RDD 中相同的 K 的个数
val rdd = sc.parallelize(Array(
("销售部","Tom"), ("销售部","Jack"),("销售部","Bob"),("销售部","Terry"),
("后勤部","Jack"),("后勤部","Selina"),("后勤部","Hebe"),
("人力部","Ella"),("人力部","Harry"),
("开发部","Allen")
))
val result = rdd.countByKey();
result.foreach(println)
结果:
(后勤部,3)
(开发部,1)
(销售部,4)
(人力部,2)countByValue:统计出 RDD 中每个元素的个数
val rdd = sc.parallelize(Array(
"Tom","Jed","Tom",
"Tom","Jed","Jed",
"Tom","Tony","Jed"
))
val result = rdd.countByValue();
result.foreach(println)
结果:
(Tom,4)
(Tony,1)
(Jed,4)三.持久化算子
高级算子
低级算子