单目slam基础 特点匹配 光流匹配 单应变换恢复变换矩阵 本质矩阵恢复变换矩阵 深度滤波
非滤波单目slam基础
非滤波方法的单目视觉SLAM系统综述 论文
直接法 特征点法 混合法区别与联系
按照 2D−2D 数据关联方式的不同 ,视觉定位方法可以分为直接法、非直接法和混合法
1. 直接法假设帧间光度值具有不变性 , 即相机运动前后特征点的灰度值是相同的 .
数据关联时 , 根据灰度值对特征点进行匹配,通过最小化光度误差,来优化匹配.
直接法使用了简单的成像模型 ,
适用于帧间运动较小的情形 , 但在场景的照明发生变化时容易失败 .
直接法中是直接对普通的像素点(DTAM),或者灰度梯度大的点(lsd-slam)进行直接法匹配。
直接法起源是光流法,由于使用了图像中大部分的信息,
对纹理差的部分鲁棒性比直接法好,但是计算量也加大,要并行化计算。
基本原理是亮度一致性约束,
J(x,y) = I(x + u(x,y) + v(x,y)) ,x,y是图像的像素坐标,u,v是同一场景下的两幅图像I,J的对应点的像素偏移。
2. 非直接法 , 又称为特征法 , 该方法提取图像中的特征进行匹配 ,
最小化重投影误差得到位姿 . 图像中的特征点以及对应描述子用于数据关联 ,
通过特征描述子的匹配 ,完成初始化中 2D−2D 以及之后的 3D−2D 的数据关联 .
例如 ORB (Oriented FAST and rotatedBRIEF, ORBSLAM中 ) 、
FAST (Features from accelerated seg-ment test) 、
BRISK (Binary robust invariant scalable keypoints) 、
SURF (Speeded up robustfeatures) ,
或者直接的灰度块(PTAM中, 使用fast角点+灰度快匹配)
可用于完成帧间点匹配。
3. 混合法,又称为半直接法,结合直接法和特征点法
使用特征点法中的特征点提取部分,而特征点匹配不使用 特征描述子进行匹配,
而使用直接法进行匹配,利用最小化光度误差,来优化特征点的匹配,
直接法中是直接对普通的像素点(DTAM),或者灰度梯度大的点(lsd-slam)进行直接法匹配。
1. 单目初始化
单目系统初始化时完成运动估计常用的方法主要有两种 :
1) 将当前场景视为一个平面场景 , 估计单应矩阵并分解得到运动估计 ,
使用这种方法的有 SVO 、 PTAM 等 .
2) 使用极线约束关系 , 估计基础矩阵或者本质矩阵 , 分解得到运动估计 ,
使用这种方法的有 DT SLAM 等 .
初始化中遇到的普遍问题是双视几何中的退化问题 .
当特征共面或相机发生纯旋转的时候 , 解出的基础矩阵的自由度下降 ,
如果继续求解基础矩阵 , 那么多出来的自由度主要由噪声决定 .
3)根据情况旋转两张中间最好的。
为了避免退化现象造成的影响 , 一些VO 系统同时估计基础矩阵和单应矩阵 ,
例如 ORB-SLAM 和 DPPTAM,
使用一个惩罚函数 , 判断当前的情形 , 选择重投影误差比较小的一方作为运动估计结果 .
初始化 一般的初始化流程:

主要是为找到跟第一幅图像有足够数量的特征匹配点,视差足够大的第二幅图像
1. PTAM初始化要求用户两次输入,来获取地图中的前2个关键帧;
需要用户在第一个和第二个关键帧之间,做与场景平行的、缓慢平滑相对明显的平移运动。
2. SVO使用单应进行初始化,但SVO不需要用户输入,算法使用系统启动时的第一个关键帧;
提取FAST特征,用图像间的KLT算法跟踪特征,视差足够的时候就选择作为第二幅图像,然后计算单应矩阵,只能是2维平面
3. SD-SLAM从第1个图像随机初始化场景的深度,通过随后的图像进行优化。
LSD-SLAM初始化方法不需要使用两视图几何。
不像其他SLAM系统跟踪两视图特征,LSD-SLAM只用单个图像进行初始化
4. ORB-SLAM 并行计算基本矩阵和单应矩阵,根据对称转移误差(多视图几何)惩罚不同的模型,最终选择最合适的模型
单目深度估计
单目系统在初始化中还要完成像素点的深度估计 , 单目系统无法直接从单张图像中恢复深度 ,
因此需要一个初始估计 .
解决该问题的:
一种办法是跟踪一个已知的结构(先验知识);
另外一种方法是初始化点为具有较大误差的逆深度,
在之后过程中优化(随机过程优化,多高斯分布(卡尔曼滤波器???),
高斯分布+均匀分布(贝叶斯滤波器 svo))直到收敛至真值 .
像素点的深度估计方法有滤波器方法和非线性优化方法 .
其中 SVO 、 DSO 将深度建模为一 个 类 高 斯 模 型 , 然 后 使 用 滤 波 器 估 计 .
另 外 一种 方 法 对 深 度 图 构 建 一 个 能 量 函 数 , 例 如 LSD-SLAM 、DTAM 、 DPPTAM 等 ,
然后使用非线性优化方法最小化能量函数 .
该函数包括一个光度值误差项以及一个正则项 , 用来平滑所得结果.
特征点匹配
在讲解恢复R,T前,稍微提一下特征点匹配的方法。
常见的有如下两种方式:
1. 计算特征点,然后计算特征描述子,通过描述子来进行匹配,优点准确度高,缺点是描述子计算量大。
2. 光流法:在第一幅图中检测特征点,使用光流法(Lucas Kanade method)对这些特征点进行跟踪,
得到这些特征点在第二幅图像中的位置,得到的位置可能和真实特征点所对应的位置有偏差。
所以通常的做法是对第二幅图也检测特征点,如果检测到的特征点位置和光流法预测的位置靠近,
那就认为这个特征点和第一幅图中的对应。
在相邻时刻光照条件几乎不变的条件下(特别是单目slam的情形),
光流法匹配是个不错的选择,它不需要计算特征描述子,计算量更小。
2. 位姿估计
通用的位姿估计流程

这个先验信息可能是恒速运动模型,可能是假设运动量不大,使用上一时刻的位姿。
1. 恒速运动模型,使用上帧位姿*速度得到当前帧位姿初始值
PTAM,DT-SLAM,ORB-SLAM,DPPTAM都假设相机做平滑运动采用恒定速度运动模型,
用跟踪到的之前两幅图像的位姿变化估计作为当前图像的先验知识(用于数据关联的图像位姿的要求和限制)。
但是,在相机运动方向上有猛烈移动时,这样的模型就容易失效
2. 静止不动模型,使用上帧位姿作为当前帧位姿的初始值
LSD-SLAM和SVO都假设在随后的图像,相机位姿没有明显改变,因此,这种情况下都是用高帧率相机。
直接和间接方式都是通过最小化图像间的测量误差,优化估计的相机位姿;
直接方法测量光度误差(像素值误差),
间接方法通过最小化从图像上一位姿的地图中获得的路标的重投影到当前帧的重投影误差(几何位置误差)。
单应矩阵H 恢复变换矩阵 R, t
单目视觉slam 基础几何知识
p2 = H12 * p1 4对点 A*h = 0 奇异值分解 A 得到 单元矩阵 H , T = K 逆 * H21*K
展开成矩阵形式:
u2 h1 h2 h3 u1
v2 = h4 h5 h6 * v1
1 h7 h8 h9 1
按矩阵乘法展开:
u2 = (h1*u1 + h2*v1 + h3) /( h7*u1 + h8*v1 + h9)
v2 = (h4*u1 + h5*v1 + h6) /( h7*u1 + h8*v1 + h9)
将分母移到另一边,两边再做减法
-((h4*u1 + h5*v1 + h6) - ( h7*u1*v2 + h8*v1*v2 + h9*v2))=0 式子为0 左侧加 - 号不变
h1*u1 + h2*v1 + h3 - ( h7*u1*u2 + h8*v1*u2 + h9*u2)=0
写成关于 H的矩阵形式:
0 0 0 0 -u1 -v1 -1 u1*v2 v1*v2 v2
u1 v1 1 0 0 0 0 -u1*u2 -v1*u2 -u2 * (h1 h2 h3 h4 h5 h6 h7 h8 h9)转置 = 0
h1~h9 9个变量一个尺度因子,相当于8个自由变量
一对点 2个约束
4对点 8个约束 求解8个变量
A*h = 0 奇异值分解 A 得到 单元矩阵 H
cv::SVDecomp(A,w,u,vt,cv::SVD::MODIFY_A | cv::SVD::FULL_UV);// 奇异值分解
H = vt.row(8).reshape(0, 3);// v的最后一列
单应矩阵恢复 旋转矩阵 R 和平移向量t
p2 = H21 * p1 = H21 * KP
p2 = K( RP + t) = KTP = H21 * KP
T = K 逆 * H21*K
本质矩阵F求解 变换矩阵[R t] p2转置 * F * p1 = 0
参考
基本矩阵的获得
空间点 P 两相机 像素点对 p1 p2 两相机 归一化平面上的点对 x1 x2 与P点对应
p1 = KP
p2 = K( RP + t)
x1 = K逆* p1 = P
x2 = K逆* p2 = ( RP + t) = R * x1 + t
消去t(同一个变量和自己叉乘得到0向量)
t 叉乘 x2 = t 叉乘 R * x1
再消去等式右边
x2转置 * t 叉乘 x2 = 0 = x2转置 * t 叉乘 R * x1
得到 :
x2转置 * t 叉乘 R * x1 = x2转置 * E * x1 = 0 , E为本质矩阵
也可以写成:
p2转置 * K 转置逆 * t 叉乘 R * K逆 * p1 = p2转置 * F * p1 = 0 , F为基本矩阵
几何知识参考
对极几何原理:
两个摄像机的光心C0、C1,三维空间中一点P,在两幅图像中的位置为p0、p1(相当于上面的 x1, x2)。
像素点 u1,u2
p0 = inv(K) * u0
p1 = inv(K) * u1
x0 (u0x - cx) / fx
p0 = y0 = (u0y - cy) / fy
1 1
x1 (u1x - cx) / fx
p1 = y1 = (u1y - cy) / fy
1 1
如下图所示:

由于C0、C1、P三点共面,得到:

这时,由共面得到的向量方程可写成:
p0 *(t 叉乘 R * p1)
其中,
t是两个摄像机光心的平移量;
R是从坐标系C1到坐标系C0的旋转变换,
p1左乘旋转矩阵R的目的是把向量p1从C1坐标系下旋转到C0坐标系下(统一表示)。
一个向量a叉乘一个向量b,
可以表示为一个反对称矩阵乘以向量b的形式,
这时由向量a=(a1,a2,a3) 表示的反对称矩阵(skew symmetric matrix)如下:
0 -a3 a2
ax = a3 0 -a1
-a2 a1 0

所以把括号去掉的话,p0 需要变成 1*3的行向量形式
才可以与 3*3的 反对称矩阵相乘
p0转置 * t叉乘 * R * P1
我们把 t叉乘 * R = E 写成
p0转置 * E * P1

本征矩阵E的性质:
一个3x3的矩阵是本征矩阵的充要条件是对它奇异值分解后,
它有两个相等的奇异值,并且第三个奇异值为0。
牢记这个性质,它在实际求解本征矩阵时有很重要的意义 .
计算本征矩阵E、尺度scale的来由:
将上述矩阵相乘的形式拆开得到 :

上面这个方程左边进行任意缩放都不会影响方程的解:
(x0x1 x0y1 x0 y0x1 y0y1 y0 x1 y1 1)*E33(E11/E33 ... E32/E33 1) = 0
所以E虽然有9个未知数,但是有一个变量E33可以看做是缩放因子,
因此实际只有8个未知量,这里就是尺度scale的来由,后面会进一步分析这个尺度。
AX=0,x有8个未知量,需要A的秩等于8,所以至少需要8对匹配点,应为有可能有两个约束是可以变成一个的,
点可能在同一条线上,或者所有点在同一个面上的情况,这时候就存在多解,得到的值可能不对。
对矩阵A进行奇异值SVD分解,可以得到A
p2转置 * F * p1 = 0 8点对8个约束求解得到F
* f1 f2 f3 u1
* (u2 v2 1) * f4 f5 f6 * v1 = 0
* f7 f8 f9 1
按照矩阵乘法展开:
a1 = f1*u2 + f4*v2 + f7;
b1 = f2*u2 + f5*v2 + f8;
c1 = f3*u2 + f6*v2 + f9;
得到:
a1*u1+ b1*v1 + c1= 0
展开:
f1*u2*u1 + f2*u2*v1 + f3*u2 + f4*v2*u1 + f5*v2*v1 + f6*v2 + f7*u1 + f8*v1 + f9*1 = 0
写成矩阵形式:
[u1*u2 v1*u2 u2 u1*v2 v1*v2 v2 u1 v1 1]*[f1 f2 f3 f4 f5 f6 f7 f8 f9]转置 = 0
f 9个变量,1个尺度因子,相当于8个变量
一个点对,得到一个约束方程
需要8个点对,得到8个约束方程,来求解8个变量
A*f = 0
所以F虽然有9个未知数,但是有一个变量f9可以看做是缩放因子,
因此实际只有8个未知量,这里就是尺度scale的来由,后面会进一步分析这个尺度。
上面这个方程的解就是矩阵A进行SVD分解A=UΣV转置 后,V矩阵是最右边那一列的值f。
另外如果这些匹配点都在一个平面上那就会出现A的秩小于8的情况,这时会出现多解,会让你计算的E/F可能是错误的。
A * f = 0 求 f
奇异值分解F 基础矩阵 且其秩为2
需要再奇异值分解 后 取对角矩阵 秩为2 后在合成F
cv::Mat u,w,vt;
cv::SVDecomp(A,w,u,vt,cv::SVD::MODIFY_A | cv::SVD::FULL_UV);// A = w * u * vt
cv::Mat Fpre = vt.row(8).reshape(0, 3);// F 基础矩阵的秩为2 需要在分解 后 取对角矩阵 秩为2 在合成F
cv::SVDecomp(Fpre,w,u,vt,cv::SVD::MODIFY_A | cv::SVD::FULL_UV);
w.at(2)=0;// 基础矩阵的秩为2,重要的约束条件
F = u * cv::Mat::diag(w) * vt;// 在合成F
从基本矩阵恢复 旋转矩阵R 和 平移向量t
F = K转置逆 * E * K逆
本质矩阵 E = K转置 * F * K = t 叉乘 R
从本质矩阵恢复 旋转矩阵R 和 平移向量t
恢复时有四种假设 并验证得到其中一个可行的解.
本质矩阵E = t 叉乘 R 恢复变换矩阵R,t的时候,有四种情况,但是只有一种是正确的。
而判断正确的标准,
就是按照这个R,t 计算出来的深度值(两个坐标系下的三维坐标的Z值)都是正值,
因为相机正前方为Z轴正方向。
三角变换计算三维坐标可按后面的方法计算。
本征矩阵的性质:
一个3x3的矩阵是本征矩阵的充要条件是对它奇异值分解后,
它有两个相等的奇异值,
并且第三个奇异值为0。
牢记这个性质,它在实际求解本征矩阵时有很重要的意义。
计算本征矩阵E的八点法,大家也可以去看看wiki的详细说明
本征矩阵E的八点法
有本质矩阵E 恢复 R,t
从R,T的计算公式中可以看到R,T都有两种情况,
组合起来R,T有4种组合方式。
由于一组R,T就决定了摄像机光心坐标系C的位姿,
所以选择正确R、T的方式就是,把所有特征点的深度计算出来,
看深度值是不是都大于0,深度都大于0的那组R,T就是正确的。

以上的解法 在 orbslam2中有很好的代码解法
orbslam2 单目初始化
3. 地图生成
地图生成的一般流程

地图生成模块将世界表示成稠密(直接)或稀疏(间接)的点云。
系统将2D兴趣点三角化成3D路标,并持续跟踪3D坐标,然后定位相机,这就是量度地图(pose + point)。
但是,相机在大场景运行时,量度地图的大小就会无限增大,最终导致系统失效
拓扑地图(pose-graph)可以减少这一弊端,它尽量将地图中的量度信息最小化,
减少几何信息(尺度,距离和方向)而采用连接信息。
视觉SLAM中,拓扑地图是一个无向图,节点通常表示关键帧,关键帧通过边连接,节点之间存在相同的数据关联
拓扑地图与大场景的尺度比较吻合,为了估计相机位姿,也需要量度信息;
从拓扑地图到量度地图的变化并不是一件容易的事情,因此,最近的视觉 SLAM 系统都采用混合地图,局部量度地图和全局拓扑地图。
地图制作过程会处理新路标将其添加到地图中,还检测和处理离群点。
图标点的添加可以通过三角化,或者滤波实现的位置估计(一般是逆深度,加上一个概率分布),
收敛到一定的程度就可以加入到地图中。
单目极线搜索匹配点三角化计算初始深度值
用单应变换矩阵H或者本质矩阵E 求解得到相邻两帧的变换矩阵R,t后就可是使用类似双目的
三角测距原理来得到深度。
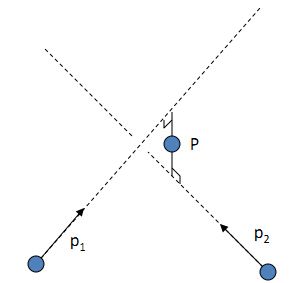
上图中的物理物理中的点 P =[X,Y,Z,1]
在两相机归一化平面下的点 x1 x2 [x,y,z]
在两相机像素平面上的点 p1, p2,匹配点对 [u,v,1]
p1 = k × [R1 t1] × P
左乘 k逆 × p1 = [R1 t1] × P
得到 x1 = T1 × P
计算 x1叉乘x1 = x1叉乘T1 × P = 0
这里 T1 = [I, 0 0 0] 为单位矩阵。
p2 = k × [R2 t2] × P
左乘 k逆 × p2 = [R2 t2] × P
得到 x2 = T2 × P
消去 x2叉乘x2 = x2叉乘T2 × P = 0
式中:
x1 = k逆 × p1 ,
x2 = k逆 × p2 ,
T2= [R, t]为帧1变换到帧2的 已知
得到两个方程
x1叉乘T1 × P = 0
x2叉乘T2 × P = 0
写成矩阵形式 A*P = 0
A = [x1叉乘T1; x2叉乘T2]
这又是一个要用最小二乘求解的线性方程方程组 ,和求本征矩阵一样,
计算矩阵A的SVD分解,然后奇异值最小的那个奇异向量就是三维坐标P的解。
P是3维齐次坐标,需要除以第四个尺度因子 归一化.
[U,D,V] = svd(A);
P = V[:,4] 最后一列
P = P/P(4);// 归一化
以上也是由本质矩阵E = t 叉乘 R 恢复变换矩阵R,t的时候,有四种情况,但是只有一种是正确的。
而判断正确的标准,就是按照这个R,t 计算出来的深度值都是正值,因为相机正前方为Z轴正方向。
概率方法更新矫正 深度值
我们知道通过两帧图像的匹配点就可以计算出这一点的深度值,
如果有多幅匹配的图像,那就能计算出这一点的多个深度值。
一幅图像对应另外n幅图像,可以看作为n个深度传感器,
把得到点的深度信息的问题看作是有噪声的多传感器数据融合的问题,
使用Gaussian Uniform mixture model(高斯均值混合模型)来对这一问题进行建模,
假设好的测量值符合正态分布,好的测量值的比例为pi,
噪声符合均匀分布,噪声比例为1-pi 使用贝叶斯方法不断更新这个模型,
让点的深度(也就是正态分布中的均值参数)和好的测量值的比例pi收敛到真实值。
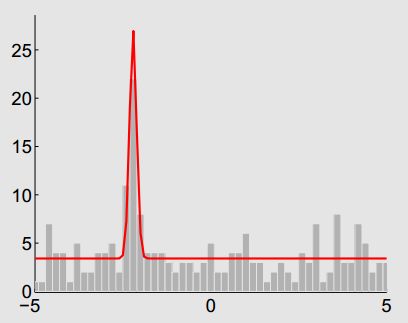
好的测量值符合正态分布
噪声符合均匀分布,
使用贝叶斯方法(最大后验概率)更新,这是SVO中深度滤波的部分。
好的测量值和噪声均符合高斯分布,使用卡尔曼滤波来进行深度测量值的滤波
这就像对同一个状态变量我们进行了多次测量,
因此,可以用贝叶斯估计来对多个测量值进行融合,
使得估计的不确定性缩小。
如下图所示:
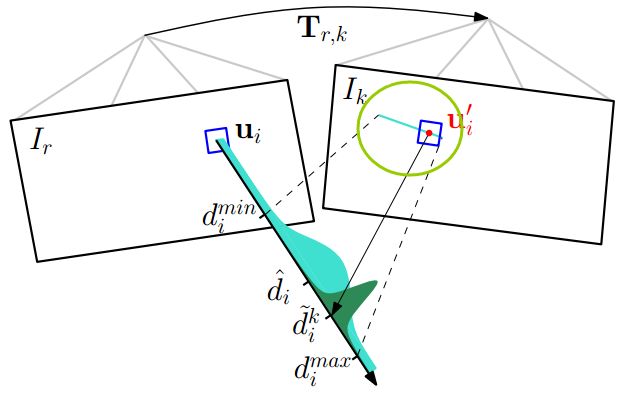
一开始深度估计的不确定性较大(浅绿色部分),
通过三角化得到一个深度估计值以后,
能够极大的缩小这个不确定性(墨绿色部分)。
4. 地图维护

地图维护通过捆集调整(Bundle Adjustment)或位姿图优化(Pose-Graph)来优化地图。
地图扩展的过程中,新的3D路标基于相机位姿估计进行三角化。经过一段时间的运行,由于相
机累积误差增加,相机位姿错误,系统出现漂移(scale-drift)。
位姿图优化相比全局捆集调整返回较差的结果。
原因是位姿图优化只用于关键帧位姿优化,
(要是路标相对于的是关键帧表示,而不是世界下的表示,会相应地调整路标的3D结构);
全局捆集调整都优化关键帧位姿和3D结构。
地图维护也负责检测和删除地图中的由于噪声和错误特征匹配的离群点。
丢失后闭环检测
视觉词袋BOVM(orb-slam2)
或者 高斯小图 块匹配(ptam)
思考
感觉一般的slam按照上面的8个部分,想一遍要能想通,原理上面一般就算是可以了。就剩下代码实践了。
系统有没有特定的要求,大范围的可以吗,室内还是室外,
是直接法还是间接法,对应的就是稀疏地图还是(半)稠密地图,优化的是几何误差还是光度误差。
需不需要初始化,需要人工的干预,非2维平面可以吗,对应的就是计算本征矩阵还是单应矩阵。
还是基于滤波的方法,不需要初始化,后续优化就可以。
然后就是tracking,因为视觉slam是一个非凸函数,需要一个初始值,
对应的就是你的prior是什么,恒速运动模型还是高速相机,把前一帧的位姿当做初始值。
追踪的过程的优化函数是什么,是光度不变,还是几何误差,就是g2o中边,顶点的构造。
当然还要维护地图,地图中的点是怎么表示,基于逆深度,还是欧式几何表示,camera-anchor的表示。
地图维护中要进行BA,还是Pose-Graph的优化,还是杂交。
然后就是闭环的检测,基于视觉词带,还是随机取一些帧进行Image Alignment。
当然这其中还有无数细节,运动快,模糊是怎么处理的(加大搜索范围,从金字塔coarse-fine的搜索),
Tracking lost在什么情况下发生,怎么进行重定位。
最小二乘法要做几次,怎么时候收敛,要不要给他设个时间约束,权重怎么设置等等。
