这篇笔记,主要记录花书第四章关于数值计算知识的回顾。在机器学习中常常需要对模型进行优化,例如找到损失函数的最小值和线性方程组的求解。其中介绍的梯度下降、牛顿方法、约束优化等都是非常常见的优化方法。
上溢和下溢
上溢:当大量级的书被近似为∞或者-∞时,发生上溢,进一步的运算会导致结果变成非数字。
下溢:当接近零的数被四舍五入之后为零时,发生下溢。
病态条件
条件指数(Conditioning):条件指数市值函数相对于输入的微小变化而发生变化的快慢程度
病态矩阵(Poorly conditioned matrices):当输入被轻微的变化而导致输出结果发生很大变化的一个矩阵,称为病态矩阵。下面举了一个栗子:

梯度下降优化
梯度下降算法(gradient descent):简单的来说,梯度下降算法就是在f(x)导数的方向,每次移动一个足够小的一步,寻找局部的最小值的算法。是一种无约束优化算法。如下一个寻找梯度下降最小值的路径示意图:

最快下降的新的点为:

梯度下降的几个缺点:
1. 跟起始点的选择有关,不同的起始点可能会到达不同的局部最小值。
2. 步长的选择是关键,大了可能会跳过最小是,小了收敛速度很慢。
超越梯度:雅可比矩阵和海森矩阵
雅可比矩阵(Jacobian):有时候我们需要计算输入和输出都为向量的函数的所有偏导数。包含这样偏导数的矩阵称为雅可比矩阵。具体表示如下:

海森矩阵(Hessian): 一阶导数看单调性,二阶导数看凹凸性。有时候,我们可能会对二阶导数比较感兴趣。当我们的函数具有多维输入,二阶导数也有很多,我们可以对这些导数合并成一个矩阵,就是海森矩阵。具体表示如下:
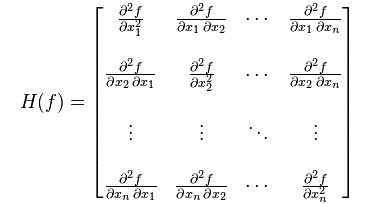

从矩阵的定义上来看,海森矩阵等价于梯度的雅可比矩阵。
我们通过二阶导数预期一个梯度下降步骤能表现得多好。我们在低昂前点x(0)出做函数f(x)的近似二阶泰勒级数:

如果我们的学习率ε,那么新的x将会是x(0)-εx。代入上述,得:
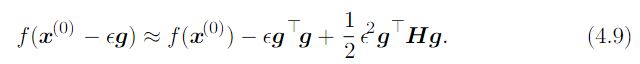
通过计算,使得近似泰勒级数下降最多的最优步长为:

牛顿方法(Newton's method):海森矩阵一个最主要的用途,就是牛顿方法。牛顿方法是一个基于二阶泰勒展开来近似x(0)附近的f(x)。同4.8类似,梯度展开表示。经过计算,得到函数临界点:
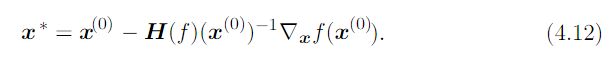
一阶优化算法(first-order optimization algorithms):仅使用梯度信息优化的算法称为一阶优化算法,如梯度下降算法。
二阶优化算法(second-order optimization algorithms):使用海森矩阵优化的算法称为二阶优化算法,如牛顿方法。
梯度下降算法和牛顿方法,在NG的视频中有详细的整个推导过程,有兴趣的童鞋可以去看一下。
约束优化
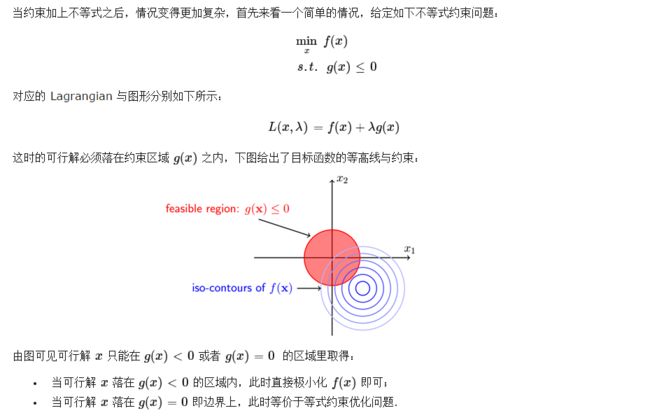
约束优化(constrained optimization):有时候x的所有可能值的最大化、最小化的一个函数f(x)不是我们所希望的。相反,我们可能希望在x的某些集合S中找到f(x)的最大值或者最小值。称为约束优化。集合S中的x称为可行(feasible)点。
这里不使用书中的概念说明,引用 http://www.cnblogs.com/ooon/p/5721119.html中 更为直观的说明(有图有真相)。由于中直接复制文字、图片排版会发生混乱,这里贴了图,建议直接查看上述链接博文。
等式约束(equality constraint):


不等式约束(inequality constraint):



实例:线性最小二乘
我们希望找到下式的最小化x值

平方导数下来乘以2,正好与1/2抵消:
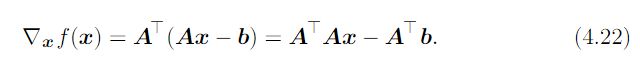
设步长ε,和容差δ是个小的正数,伪代码如下:

最小化同样的式子x值,但是收到如下约束:
很明显这是一个不等式约束条件下的优化问题。拉格朗日乘子式:
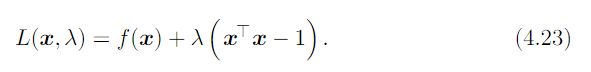


λ的选择必须使结果服从约束。我们可以关于λ进行梯度上升找到这个值。为了观察,我们可以对λ进行求偏导数。

观察可以看到,当x的范数超过1的时候,导数才是正数。迭代更新λ的值,知道x的范数具有正确的范数。
Q&A:
如果有兴趣相投的朋友,欢迎来http://www.jokls.com/提问或者解答其他小伙伴的提问。