Flink在滴滴的应用与实践进化版
本文整理自Flink Forward 全球在线会议 ,分享者薛康,滴滴实时平台负责人,主要是是从以下四个方面介绍,flink在滴滴的应用与实践:
Flink服务概览
StreamSQL实践
实时计算平台建设
挑战与规划
1. Flink服务概览
1.1 滴滴实时计算发展史
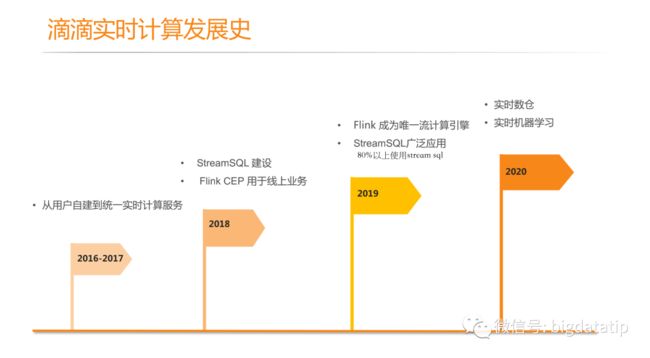
2016引入实时计算引擎,但是主要是用户自建集群,而且引擎也很杂,包括flink,storm,spark streaming。
2017年 有团队提供统一的实时计算引擎,主要是flink 和spark streaming。
2018年 滴滴实时计算应用更加广泛,新用户不了解flink table api,但是sql开发就简单很多,所以为了节省使用成本,进行StreamSQL建设,目的是降低普通用户使用门槛。
2018年 Flink CEP用于线上业务,实时生效动态规则,用于线上个性化营销业务。
2019年Flink成为唯一流计算引擎,只有少量残留业务未使用StreamSQL,streamSQL 占比到了80%。
2020年开始建设实时数仓(2019下半年已经开始建设)和实时机器学习内容。
1.2 规模

1.3 业务场景
1.4 多集群架构
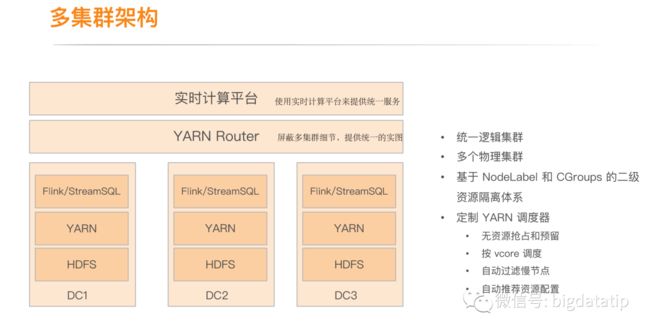
实时计算平台提供统一的服务入口,不提供其他形式提交flink任务,屏蔽底层集群架构细节。
YARN Router 用来完成实时计算平台生成任务,提交到不同的集群 的路由工作。
资源隔离是基于 NodeLabel 和 CGroups 的二级资源隔离体系,nodelabel将重要任务与普通任务划分开来,不同任务使用不同nodelabel的yarn节点资源,进而避免集群资源争抢。同一节点使用cgroups限制隔离cpu使用。
定制了yarn的调度器。默认yarn的调度器,有FIFO Scheduler ,Capacity Scheduler,Fair shceduler 。刚开始离线和实时任务都是采用Fair shceduler,离线任务具有资源抢占及资源预留机制,而实时任务资源不满足任务需求,无法启动任务 ,所以必须保证实时任务资源充足。
实时任务,对cpu和sys load(系统负载)比较敏感,内存刚性限制,超出会被杀死或者自己挂掉,而vcore是虚拟的数值,cpu型任务会抢占cpu,而增加系统负载,影响其他任务调度。
滴滴是按vcore调度,改进算法之后,可以实现节点之间任务调度均衡,实际上是按照逻辑资源调度,可能存在某些节点虽然vcore有剩余,但是机器cpu等负载已经很高,不适合继续增加执行任务了。所以又增加了自动过滤慢节点功能,思路是采集物理资源使用情况,负载高到某一个阈值,不再往该节点调度。
自动资源推荐,主要是思路是任务启动时用户给定一个资源,让任务跑起来,通过采集物理资源使用情况,与用户申请的逻辑资源的比对,来计算合理的资源推荐值,下次启动时使用新的资源申请配置。
2. streamsql实践
2.1 为何建设StreamSQL
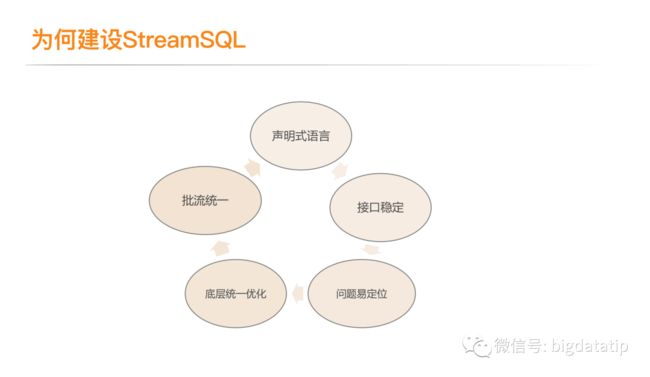
声明式语言,用户只需要关系业务逻辑,尤其是数据导入导出,完全不care底层技术实现,完成功能即可,所以使用sql更加友好方便。
接口稳定,提供sql开发业务,底层引擎升级,只要sql语法保证不变,用户就无感知了,不需要关注版本问题。
问题易定位,用户上传jar,出问题只能通过执行日志看任务,编码问题等定位比较麻烦。sql使用sql,除了udf之外,可以获得所有业务逻辑,更容易定位-sql编辑器直接支持语法校验等。
底层统一优化,sql会经过实时平台,所以可以实现统一优化sql,假如用户使用低阶 API,优化要从用户编码层开始,要频繁与用户交互,比较繁琐。
流批统一,提供统一sql视图,从平台的来实现流批统一。
2.2 优化内容
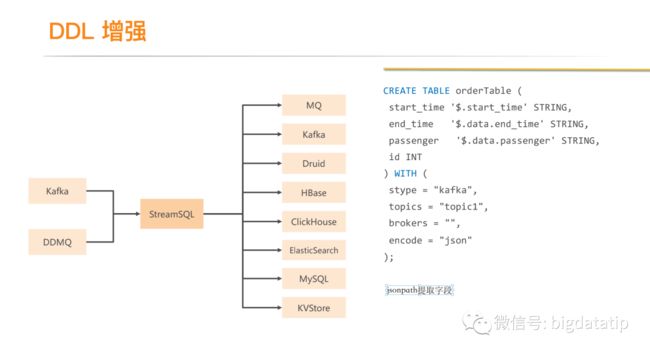
定义了各种connector,支持滴滴所有的读取,写入场景。通过DDL描述语句来定义connector的 schema,描述数据源及sink。
json类型数据字段解析是通过JSONPath来实现字段提取。

source层面内置许多格式解析,通过ddl里的encode函数来进行匹配路由,主要是支持binlog和business log。
假如是json格式,可以通过jsonpath解析,jsonpath在数据量大的情况下,性能比较低下。可以利用社区的计算列来实现优化解析过程。
特殊数据的格式,无法通过上面三种格式解析,需要在ddl定义schema的时候使用一个字段,然后在dml中使用自定义udf解析。
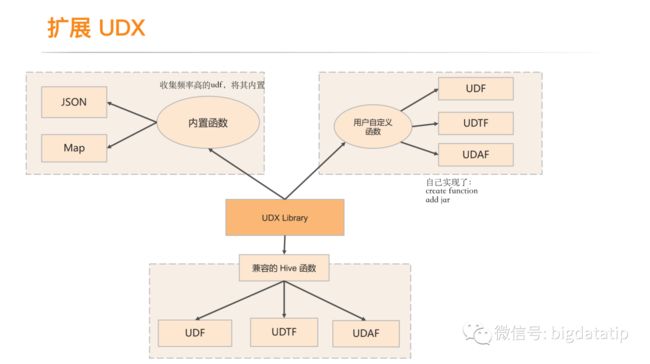
udf扩展优化:
a. 收集用户使用频率高的udf,将其内置,避免重复开发。
b. 增加了addjar和create function来方便的实现自定义udf。
c. 兼容hive的udf,公司内部的hive用户积累了大量的udf,在业务迁移到实时streamsql的时候,兼容hive的udf,那么离线转实时业务不需要重新开发,减少了迁移成本。

双流join:
比如在滴滴内部场景,订单监控,业务上是三个表,采集后是三条流,由于滴滴内部只需要关心最新的数据,而社区的join,重复的key会产生重复数据,所以滴滴内部内置了自定义的双流join实现,将两条流数据存储到带ttl的state里,假如存在相同的key有多条数据,比如订单重复数据,新的订单数据覆盖掉相同key的老订单数据即可。
维表join:
主要是支持内部kv,mysql,hbase均支持,主要是利用异步IO及LRU,提升qps,降低外部存储的压力。

3. 实时计算平台建设
3.1 StreamSQL IDE
滴滴内部提供了streamsql的IDE。
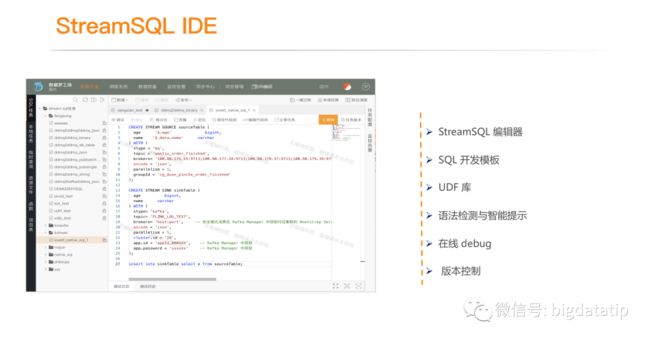
ide支持 sql编辑器,支持常用的sql开发模板和udf库,同时支持sql语法检测及智能提示。
ide也支持通过提供小量数据文件来实现在线debug,用户采集小量数据写入文件,然后导入ide,ide会拦截用户的sql语句,在debug的时候,将source置换为数据文件,将sink置换为console,然后就完成了debug功能。
ide也会记录历史版本,支持升级之后回滚到历史版本上。
3.2 任务管理模块
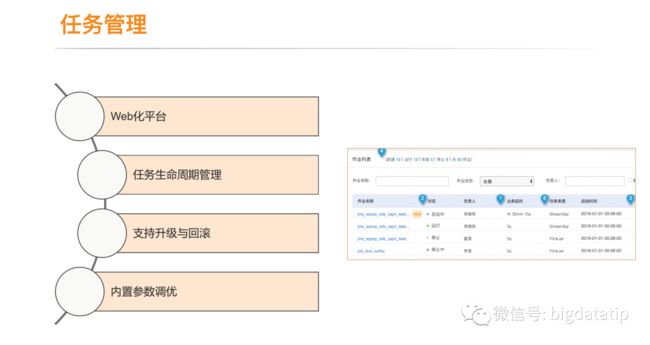
3.3 任务运维

采集展示了算子数据流入流出,状态大小等flink任务指标,方便用户定位性能问题。
flink的所有日志采集到es里,提供统一的日志查询界面,方便用户定位问题。同时支持只查看异常日志及通过关键字检索。
血缘关系,实时链路每个应用都会有上游和下游,如果改了某个应用的逻辑,修改的逻辑可能影响该应用的下游,假如没有血缘关系就很难知道去通知谁,只能等待下游使用人员因故障来追溯到你。
所以支持了血缘关系,方便发现变更影响范围,及时通知相关负责人。实现思路也很简单,主要是利用connector上报的实时表数据,后台完成实时表依赖关系的串联过程,以此实现血缘关系。
3.4 引入meta管理
平台层面加入了meta化建设,来复用及优化一些操作。比如,下图的kafka到流表,引入了meta schema,这样只需要dml,没必要ddl操作了,尤其是很多业务都要用到该topic的时候避免了很多的ddl操作。
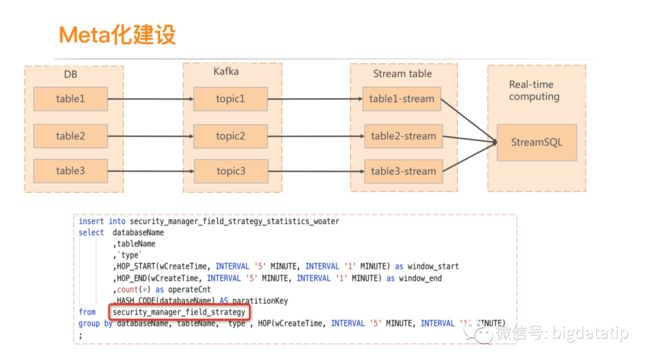
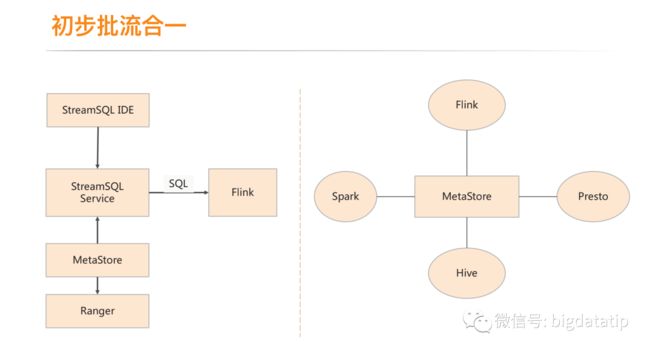
3.5 初步的流批统一
平台层面实现了批流统一,引擎层面的流批统一,等待整合社区完善版本。
离线和实时的meta数据 全部存储到hive的metastore,同时打通了ranger,用来鉴权。
4.挑战与规划

挑战1 大状态支持:
滴滴的订单允许延迟付款,所以要在应用中存储大量的状态,状态太大内存压力比较大,即使用磁盘存储状态,也会checkpoint扫全量大状态数据,导致磁盘io高影响其他任务,另外本身checkpoint容易失败。此外,CEP场景数据回溯时间也比较长,states状态大,也会引起一系列问题。所以需要更好的大状态支持。
挑战2 服务高可用
线上业务升级不重启升级,快速诊断错误。
资源不重启扩容,比如流量徒增,如何自适应流量,动态调整资源。
挑战3 多语言支持
支持 PyFLink及pyhton UDF。

规划1 :服务高可用
规划2 :实时数仓完善发展
规划3 : 实时机器学习,滴滴内部更多体现在特征提取,模型训练等线上场景比较少,ALink整合探索落地。
推荐阅读:
微博基于Flink的实时计算平台建设
Flink通过异步IO实现redis维表join
Flink异步IO第一讲
