tensorflow-keras-fasttext模型构建训练
from data_analysis import get_data_label
from tensorflow.keras.preprocessing.text import Tokenizer
# from sklearn.externals import joblib
import joblib
from tensorflow.keras.preprocessing import sequence
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import GlobalAveragePooling1D
import matplotlib.pyplot as plt
from tensorflow.keras.models import load_model
def word_map(data_path, tokenizer_path, cut_num):
train_data, train_label = get_data_label(data_path)
train_data = train_data[:-cut_num]
train_label = train_label[:-cut_num]
t = Tokenizer(num_words=None, char_level=False)
t.fit_on_texts(train_data)
joblib.dump(t, tokenizer_path)
x_train = t.texts_to_sequences(train_data)
y_labels = train_label
return x_train, y_labels
def padding(x_train, cutlen):
return sequence.pad_sequences(x_train, cutlen)
max_features = 28000
# n-gram特征的范围,一般选择为2
ngram_range = 2
def create(input_list, ngram_value=2):
return set(zip(*[input_list[i:] for i in range(ngram_value)]))
def get_ti_and_nmf(x_train, ti_path, ngram_range):
ngram_set = set()
for input_list in x_train:
for i in range(2, ngram_range + 1):
set_of_gram = create(input_list, ngram_value=i)
ngram_set.update(set_of_gram)
ngram_set.discard(tuple([0] * ngram_range))
start_index = max_features + 1
token_indice = {v: k + start_index for k, v in enumerate(ngram_set)}
# 将token_indice写入文件以便预测时使用
with open(ti_path, "w") as f:
f.write(str(token_indice))
# token_indice的反转字典,为了求解新的最大特征数
indice_token = {token_indice[k]: k for k in token_indice}
# 获得加入n-gram之后的最大特征数
new_max_features = np.max(list(indice_token.keys())) + 1
return token_indice, new_max_features
def add_ngram(sentence, token_indice, ngram_range=2):
new_sentence = []
for input_list in sentence:
new_list = input_list[:].tolist()
for ngram_value in range(2, ngram_range + 1):
for i in range(len(new_list) - ngram_value + 1):
ngram = tuple(new_list[i:i + ngram_value])
if ngram in token_indice:
new_list.append(token_indice[ngram])
new_sentence.append(new_list)
return np.array(new_sentence)
def align(x_train):
max_len = max(list(map(lambda x: len(x), x_train)))
print(max_len)
x_train = padding(x_train, max_len)
return x_train, max_len
new_max_features = 128070
embedding_dim = 60
maxlen = 119
def built_model(maxlen, new_max_features):
model = Sequential()
model.add(Embedding(new_max_features, embedding_dim, input_length=maxlen))
model.add(GlobalAveragePooling1D())
model.add(Dense(1, activation='sigmoid'))
return model
def compile_model(model):
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
batch_size = 32
epochs = 40
def fit_model(model, x_train, y_train):
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.2)
return history
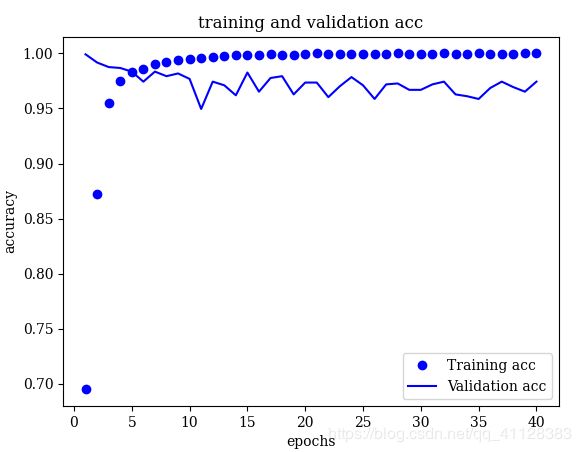
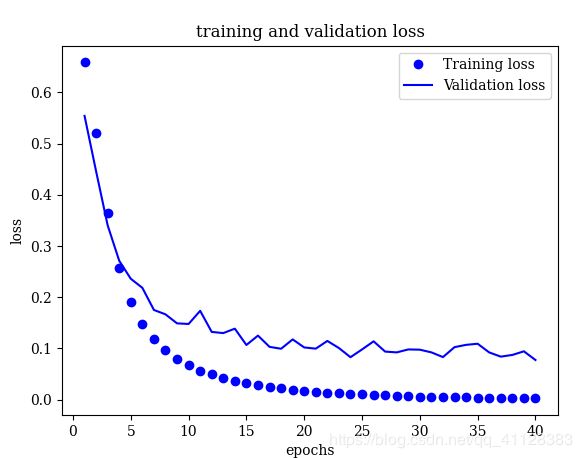
def plot_loss_acc(history, acc_pn_path, loss_pn_path):
history_dict = history.history
print(history_dict)
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('training and validation acc')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.savefig(acc_pn_path)
plt.clf()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('training and validation loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.savefig(loss_pn_path)
def model_save(save_model_path,model):
model.save(save_model_path)
return
def load_models(save_model_path,sample):
model=load_model(save_model_path)
res=model.predict(sample)
return res
if __name__ == '__main__':
data_path = '/data/django-uwsgi/text_labeled/model_train/movie/sample.csv'
cut_num = 2367
cutlen = 60
tokenizer_path = './movie/Tokenizer'
x_train, y_labels = word_map(data_path, tokenizer_path, cut_num)
x_train = padding(x_train, cutlen)
ti_path = "./movie/token_indice"
token_indice, new_max_features = get_ti_and_nmf(x_train, ti_path, ngram_range)
print(new_max_features)
new_list = add_ngram(x_train, token_indice, ngram_range=2)
x_tt, ax_len = align(new_list)
acc_pn_path = './movie/acc.png'
loss_pn_path = './movie/loss.png'
built_model = built_model(maxlen, new_max_features)
model = compile_model(built_model)
history = fit_model(model, x_train, y_labels)
plot_loss_acc(history, acc_pn_path, loss_pn_path)
save_model_path='./movie/'
model_save(save_model_path,model)
sample = np.array([x_train[0]])
res=load_models(save_model_path,sample)
print(res)
accuracy
loss
模型保存输出
[root@bhs movie]# pwd
/data/django-uwsgi/text_labeled/model_train/movie
-rw-r--r-- 1 root root 74139 Jun 19 18:42 saved_model.pb
drwxr-xr-x 2 root root 4096 Jun 19 18:42 variables