PyTorch(六)——梯度反向传递(BackPropogate)的理解
目录连接
(1) 数据处理
(2) 搭建和自定义网络
(3) 使用训练好的模型测试自己图片
(4) 视频数据的处理
(5) PyTorch源码修改之增加ConvLSTM层
(6) 梯度反向传递(BackPropogate)的理解
(7) 模型的训练和测试、保存和加载
(8) pyTorch-To-Caffe
(总) PyTorch遇到令人迷人的BUG
PyTorch的学习和使用(六)
多个网络交替情况
最近使用PyTorch搭一个对抗网络,由于对抗网络又两个网络组成,其参数的更新也涉及到两个网络的交替。简单如下:生成器(generator)生成新的数据,辨别器(discrimator)用于判断数据是真实的还是生成的。通过训练辨别器使辨别器可以准确的分辨数据的真伪,通过训练生成器使辨别器无法分辨真伪。详见Generative Adversarial Networks。
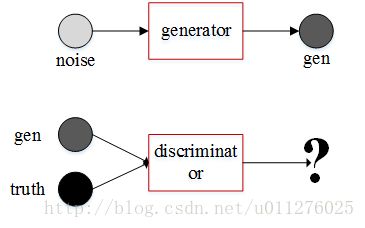
训练时先更新辨别器,然后在更新生成器:

PyTorch梯度传递
在PyTorch中,传入网络计算的数据类型必须是Variable类型, Variable包装了一个Tensor,并且保存着梯度和创建这个Variablefunction的引用,换句话说,就是记录网络每层的梯度和网络图,可以实现梯度的反向传递,网络图可以表示如下(图来自 Deep Learning with PyTorch: A 60 Minute Blitz):

则根据最后得到的loss可以逐步递归的求其每层的梯度,并实现权重更新。
在实现梯度反向传递时主要需要三步:
- 初始化梯度值:
net.zero_grad() - 反向求解梯度:
loss.backward() - 更新参数:
optimizer.step()
注意:对于一个输入input,经过网络计算得到output,在计算梯度是就是output–>input的递归过程,在递归完图后会释放图的缓存,因此在第二次使用outout进行梯度计算时会出现错,如下:
RuntimeError: Trying to backward through the graph second time, but the buffers have already been freed. Please specify retain_variables=True when calling backward for the first time.
现在看上面GAN网络更新权重的图,在1中需要使用真实数据和生成数据更新辨别器(discriminator), 但是生成数据由生成器(generator)得到,在传入到辨别器中进行计算,因此进行梯度反向计算时会同时计算出生成网络的梯度,并释放网络递归图的缓存,则在2中更新生成器时会出错。
在1中计算辨别器梯度时不需要计算生成器的梯度,因此在使用生成数据计算辨别器时使用gendata.detach()作为输入数据,这样就对当前图进行拆分,得到一个新的Variable变量。
网络测试
构建两个网络A和B,首先使用A网络的结果计算B网络,然后更新B网络,最后更新A网络,这种情况与对抗网络相似,B网络需要使用A网络的结果进行计算,如果更新B网络,则连带着A网络梯度也会计算,当最后更新B网络时,则会出错。代码如下:
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
class A(nn.Module):
def __init__(self):
super(A, self).__init__()
self.fc = nn.Linear(1, 10)
def forward(self, x):
return self.fc(x)
class B(nn.Module):
def __init__(self):
super(B, self).__init__()
self.fc = nn.Linear(10, 20)
def forward(self, x):
return self.fc(x)
a_net = A()
b_net = B()
criterion = nn.MSELoss()
optimizer_a = optim.Adam(a_net.parameters(), 0.1)
optimizer_b = optim.Adam(b_net.parameters(), 0.1)
input = torch.FloatTensor(2,1)
label = torch.FloatTensor(2, 10).fill_(1)
label2 = torch.FloatTensor(2, 20).fill_(1)
input = Variable(input)
label = Variable(label)
label2 = Variable(label2)
# update B net
b_net.zero_grad()
output1 = a_net(input)
loss1 = criterion(output1, label)
output2 = b_net(output1.detach())
loss2 = criterion(output2, label2)
loss2.backward()
optimizer_b.step()
# updata A net
a_net.zero_grad()
output3 = b_net(output1)
loss3 = criterion(output3, label2)
loss3.backward()
optimizer_a.step()
如果output2 = b_net(output1.detach())改为output2 = b_net(output1),则出现如下错误:
![]()
因此,反向求解梯度是根据输出的loss值递归到所有网络进行计算,在控制网络更新梯度时需要注意控制好传入Variable。
**注意:当使用loss3.backward()时,由于loss3经过A网络和B网络传递得到,因此A网络和B网络的梯度都会计算,使用optimizer_a.step()只跟新A网络的梯度。如果想要传递后的后向拓扑图保存,使用loss.backward(retain_graph)
###当使用同一个网络连续求多次梯度时和自定义权重初始化
- 当对同一个网络多次求取梯度时,网络最终的梯度为所有梯度之和。
- 可以使用
torch.nn.Moduleapply()进行权重的初始化。
以上2点详见PyTorch(总)——PyTorch遇到令人迷人的BUG与记录