文本无关的说话人识别综述(一)----简介
本文是读书笔记。个人比较浅显的理解,其中有一些专业词汇也是个人自己的翻译,如果有不对的希望大家指正。
来自论文《An overview of text-independent speaker recognition: From features to supervectors》的第一章节和第二章节。
一 引言
说话人识别简介:也叫做声纹识别,通过声音识别说话的人是谁。(注意跟语音识别的区别)
说话人识别的可行性:
1、物理层面(先天因素):每个人的声道形状,咽喉(larynx)尺寸等发声器官都是不一样的。
2、心理层面(后天因素):每个人的说话习惯是不同的,例如重音、节奏、语气、发音模式、口头禅等。
说话人识别的分类:文本无关和文本相关。(其中文本无关的说话人识别难度更大)
文本无关(text-independent):识别与说话的内容无关(即不管说话内容是什么,都可以识别出说话人)、
文本相关(text-dependent):识别的语句是固定的,预先知道的。
session variability:同一个说话人两段语音之间的不同。导致这些不同的原因也可以分为两大类:
1、声学环境和技术的变化。
2、说话人自身差异(with-speaker variation):健康、情绪、年级的不同,会导致session variability。
二 基础知识
下图为自动说话人识别系统的框图。

图上半部分为注册过程,下半部分为识别过程。特征提取模块将信号(raw singal)转换为特征矢量(feature vectors)。
在注册过程,使用目标说话人(target speaker)的特征矢量训练说话人模型(speaker model)。在识别过程,未知说话人的特征矢量会跟系统数据库中的模型进行比较,得到一个分数。决策模型将使用这个分数做出最后的判断。
2.1 特征的选择 selection of features
一个理想的特征应该具有以下特性:
- 不同人之间区别大,同一个人区别小
- 对噪声和失真的鲁棒性强
- 在语音中周期自然地出现
- 易于从语音信号中提取
- 难于模仿
- 不会因为说话人的健康状况或长时间的变化而变化
同时,特征的数量应该尽可能少。传统的统计模型(例如高斯混合模型 Gaussian mixture model)不能处理高维数据(high-dimensional)。
维度诅咒(the curse of dimensionality):训练样本数目会随着特征的数目的增长而指数增长。
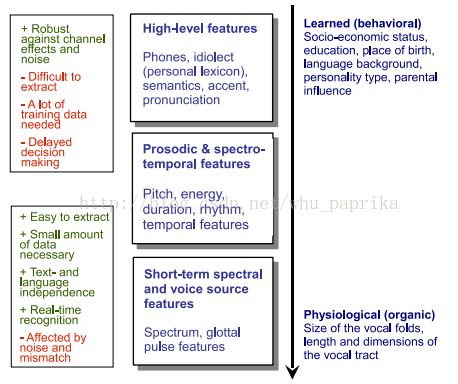
特征的分类:根据特性的物理含义我们可以将它们分成五大类。
(1) short-termspectral features 短时谱特征:一般由20-30ms的短帧中计算,主要描述短时谱包络中的音色、共鸣
(2) voice source features, 声源特征:用于描述声源(声门波)的特性
(3) spectro-temporal features, 谱-时间特征:
(4) prosodic features 韵律特征:超过几十或者几百毫秒,通常包含声调(intonation)和节奏(rhythm)
(5)high-level features 高级特性:主要捕捉个人的说话特征,例如习惯用语(uh-huh,you know, oh yeah)
2.2 说话人模型(Speaker model)
使用已知说话人的语句(training utterances)提取特征矢量,训练说话人模型并存入系统数据库。
典型的说话人模型可以分为两种:template model和 stochastic model,即模板模型和随机模型。也称作非参数模型和参数模型。
模板模型将训练特征参数和测试的特征参数进行比较,两者之间的失真(distortion)作为相似度。例如VQ(Vector quantization矢量量化)模型和DTW(dynamic time warping)模型
随机模型用一个概率密度函数来模拟说话人,训练过程用于预测概率密度函数的参数,匹配过程通过计算相应模型的测试语句的相似度来完成。例如(GMM和HMM)高斯混合模型和隐马尔科夫模型。
根据测试用例,模型也可以分为generative model和discriminativemodel。前者主要有:GMM和VQ模型,后者主要有:ANNs人工神经网络和SVMs支持向量机。前者主要针对个人差异(within each speaker),后者主要针对人与人之间的差异(boundary between speakers)。