这篇将作为我这一段时间以来结合项目、学习对于自我提升的过程中的一个技术性的经验总结。

现在大多数公司招人看中项目经验、工作经验,我也承认这些也确实非常重要。但是我时常会想,是否有一条捷径,可以让我们更快的强大起来、更快的走向成功?我也不确定,我也在摸索着前行...但我相信,站在巨人们的肩旁上,借鉴他们探索出的东西,加上自己的那一份努力,至少可以让自己少走一些弯路。
为什么会写这篇程序优化的总结,主要是面向如今这个大数据驱动的时代。如果没有大批量的数据让你去处理、如果没有大量业务需要你去书写,那么有必要去在乎那零点几毫秒的优化或是复用那些代码吗?
1. 选用恰当的数据结构
去重操作是我们日常会遇到的一个问题。我无数次遇到去重的问题的时候,可能大家想的都一样: 卧槽,也太简单了,给我两秒钟...然后做了如下操作:
ArrayList arr = new ArrayList(Arrays.asList(......)); //待去重数组
ArrayList arrTemp = new ArrayList();
for(String str: arr) {
if (!arrTemp.contains(str)) {
arrTemp.add(str);
// 处理操作
}
}
这是正常人的思路吧,使用一个临时数组来存放新的元素,然后便利的时候判断是否包含。嗯...功能实现了,但是这个待遍历的数组变成了几十万条数据...然后我按下了 run 跑程序并等待程序的结束,然后我在程序finish 之前陷入了长时间的沉思......然后到处找呀找,查阅资料和博客,最后发现了一种效率非常赞的数据结构 - HashSet, 我非常激动,MD太辛苦了找了辣磨久终于找到好的办法了,这个时候之前的程序运行结束了......
先想想为什么这种数组的方式会很慢。在我们每一次循环中,我们都会使用contains()去遍历整个arrTemp,随着数组越来越长,速度会越来越慢。接下来看看 HashSet 的存储结构示意图:
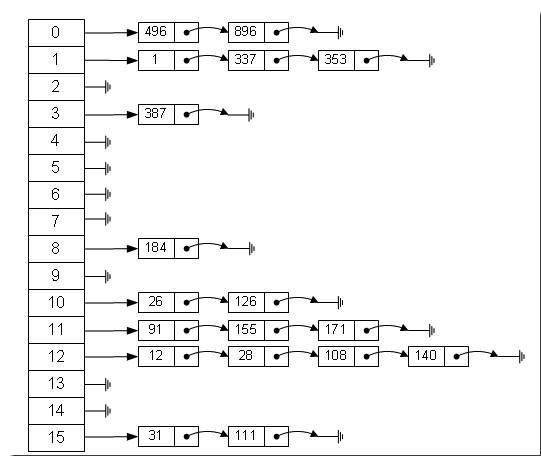
在HashSet中,每一个
key都对应着一个
hashcode,因此通过计算可以先找到是在数组中 0~15 的哪一个位置,然后再去寻找这条链上有没有这个对应的
key值。这么一来在速率上明显快了不上。
ArrayList arr = new ArrayList(Arrays.asList(......)); //待去重数组
HashSet set = new HashSet();
for (String str : arr) {
if (set.add(str)) {
// 没有重复元素
} else {
// 存在重复元素...
}
}
换了一种数据结构,在程序的执行效率上有了很大的改观。所以说,选择一种好的数据结构是很重要的~
2. 养成复用对象的好习惯
在程序的运行过程中,JVM堆上存放着活对象和程序无法再次引用的垃圾对象,当堆空间的空闲部分低于某个比例或者无法满足为新对象分配空间时,JVM都会触发一次垃圾收集(Garbage Collect,GC),触发gc时,JVM会暂停所有的用户线程。gc触发太过频繁或是时间过长,都会导致程序性能大大下降。
所以说,遇到此类问题我们应该怎么办呢? 我们需要尽量去重用对象,以减少gc的触发几率。比如说像这样:
String str = "";
for(...) {
str = ....;
str ......
}
顺便说一下,不只是对象的创建,循环里面最好别放一些没必要的操作,特别是耗时的操作。
3. 提高字符串拼接的效率
字符串的拼接是我们写程序的时候最最常见的情况了,我相信大家肯定都遇到过,并且以后也会继续和它打交道。对于文件IO读写而言,大家一定对于这句话并不陌生:
str += stringBuffer.readLine() + "\n";
我们在读取文件的我时候,经常会按行来读取,然后将其内容进行依次追加,最后将内容结果写出。
如果在循环次数不多的情况下,并且对效率的要求不高的话,为了图方便这么些没问题。但是,如果循环次数非常多的话,这种方式做字符串的拼接效率实在太低了。这里有一种更好的方式:使用 StringBuilder ,我们来看一个效率的对比结果吧。
首先我们假设有一个100000次的循环,每一次里面都会将内容"aaa123"追加到结果中。
long start = System.currentTimeMillis();
int size = 100000;
String result = "";
for (int i = 0; i < size; i++) {
result += "aaa123";
}
long end = System.currentTimeMillis();
System.out.println(end - start + "ms");

然后再来看一下改成StringBuilder之后的代码和运行结果:
long start = System.currentTimeMillis();
int size = 100000;
String result = "";
StringBuilder builder = new StringBuilder();
for (int i = 0; i < size; i++) {
builder.append("aaa123");
}
result = builder.toString();
long end = System.currentTimeMillis();
System.out.println(end - start + "ms");

这效率简直高了几个数量级了...为什么StringBuilder可以做到在这样多的循环次下达到这么高的效率呢?我大致解释下...
对于使用'' + ''号来追加的方式而言,String对象在赋值以后是没法改变的,所以这种使用'' + ''号的追加原理其实每一次都重新创建了一个String 对象,然后对其赋值。这样不断新建对象,就像之前我们所讲的那样,会频繁触发gc,而且会随着内容越来越多使得创建String对象的速度越来越慢。
然而对于StringBuilder 的 append追加方式,是将string 转换为一个char[] 数组,然后通过扩展数组的方式将追加内容放入原始数组中。
4. for循环的正确使用姿势
对于for循环的使用,我的建议是:
- 遍历数组使用基于索引的循环方式
- 遍历集合使用基于迭代器的循环方式
具体的怎么去使用,我在这里就不做过多说明了。
主要讲讲怎么进行循环的优化吧。
(1) ''外小内大''原则
for (int i = 0; i < 1000000 ; i++ ) {
for (int j = 0; j < 1000 ; j++ ) {
for (int k = 0 ; k < 10; k++) {
}
}
}

这是一个典型的循环嵌套的结构,但是呢for循环应该是要满足一个''外小内大''的模式。这是我们改良后的代码:
for (int i = 0; i < 10 ; i++ ) {
for (int j = 0; j < 1000 ; j++ ) {
for (int k = 0 ; k < 1000000; k++) {
}
}
}

结果很明显,运行效率上面快了不少。但是这还不是最完美的做法~
int i,j,k;
for (i = 0; i < 10 ; i++ ) {
for (j = 0; j < 1000 ; j++ ) {
for (k = 0 ; k < 1000000; k++) {
}
}
}
嗯,这样差不多就比较完美了
(2)避免没必要的操作
还是先来看一段原始代码:
for(int i = 0; i < list.size(); i++) {
i = i * a * b;
}
这段代码有两个问题:第一个问题是每次循环都会进行一次 list.size()的计算,第二个问题是每次都会进行 a * b的计算。这些都是只需要进行一次的操作,没必要每次都进行。
优化后的代码如下:
int c = a * b;
int len = list.size();
for(int i = 0; i < len; i++) {
i = i * c;
}