[行为检测] CDC-Convolutional-De-Convolutional Networks for Precise Temporal Action Location
这篇文章是2017年ICCV的一篇文章《Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos》,下面是这篇文章的主要贡献点。
- 第一次将卷积、反卷积操作应用到行为检测领域,文章同时在空间下采样,在时间域上上采样。
- 利用CDC网络结果可以做到端到端的学习
- 这篇文章可以做到per-frame action lableling,也就是每一帧都可以做预测。而且取到了现在的state-of-art结果
一、网络结构
这篇文章的网络结构其实是比较简单的。假设都已经知道了C3D网络,不知道可以移步到:http://vlg.cs.dartmouth.edu/c3d/ 。这篇文章在C3D网络上做了改进,改进后的网络结构如下图所示。
![[行为检测] CDC-Convolutional-De-Convolutional Networks for Precise Temporal Action Location_第1张图片](http://img.e-com-net.com/image/info8/ef757da49a2948048aebeea161ebb352.jpg)
网络步骤如下所示。
- 输入的视频段是112x112xL,连续L帧112x112的图像
- 经过C3D网络后,时间域上L下采样到 L/8, 空间上图像的大小由 112x112下采样到了4x4
- CDC6: 时间域上上采样到 L/4, 空间上继续下采样到 1x1
- CDC7: 时间域上上采样到 L/2
- CDC8:时间域上上采样到 L,而且全连接层用的是 4096xK+1, K是类别数
- softmax层
二、设计细节
这里主要阐述作者对于CDC filter的设计,CDC filter要做到时间域上的上采样和空间域上的下采样。作者这里讨论了几种设计方案(主要是针对CDC6)。
2.1 Conv6 & deconv6
显然,我们首先想到的就是先做空间域上的下采样,然后再做时间域上的上采样。如下图所示。

2.2 CDC6
作者设计的CDC6联合操作,设计了两个独立的卷积核(上图中的红色和绿色),同时作用于112x112xL/8的特征图上。每个卷积核作用都会生成2个1x1的点,如上conv6,那么两个卷积核就生成了4个。相当于在时间域上进行了上采样过程。
2.3 Loss function
根据上述的网络结构图可以知道,经过softmax后会输出 (K+1, 1, 1),也就是说针对每一帧,都会有一个类别的打分输出。所以作者说做到了每帧标签。
假设总共有N个training segments,我们取出第n个training sample,那么经过网络后会得到(K+1, 1, 1),经过CDC8后的输出为On[t], 然后经过softmax层,针对这个样本的第t帧,我们能得到它对应的第i个类别的打分是:

总的Loss function为:
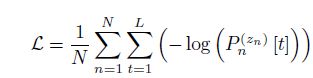
三、实验结果
3.1 Per-frame labeling
数据集:
作者在THUMOS’14上进行了测试,THUMOS’14包含20种行为动作,作者使用了2755个修剪的训练视频和1010个未修剪的测试视频(3007个instance)作为训练集。作者测试了213个视频,总计(3358)个instance。
测试尺度:
取每一帧的最高预测值所在类,作为结果类。然后取mAP。
测试结果如下所示。
![[行为检测] CDC-Convolutional-De-Convolutional Networks for Precise Temporal Action Location_第2张图片](http://img.e-com-net.com/image/info8/6c2293e95b154f17983b6fd7bac6f4e2.jpg)
3.2 Temporal action localization(时序行为检测)
评价尺度:
Localization同样也是用mAP来评估的。预测是正确的,如果预测正确的张数占ground truth的比例超过IOU threshold。
作者之后测试了不同阈值(IoU threshold)的结果图。
![[行为检测] CDC-Convolutional-De-Convolutional Networks for Precise Temporal Action Location_第3张图片](http://img.e-com-net.com/image/info8/ad9f29c635174bfd9a0e68217127383f.jpg)
吐槽/比较:
- 传统方法不太好:因为他们没有直接定位到temporal localization问题(时间域行为定位)。
- iDTF不好:因为没有学习到 空间-时间 关系
- RNN不好:unable to explicitly capture motion information
beyond temporal dependencies - S-CNN:能捕捉到 空间-时间 关系,但是对于边界的调整能力不好。也就是定位不太准确。
3.3 性能
On a **NVIDIA Titan
X GPU** of 12GB memory, the speed of a CDC network is
around 500 Frames Per Second (FPS)。
参考文献
[1] Shou Z, Chan J, Zareian A, et al. CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos[J]. arXiv preprint arXiv:1703.01515, 2017.
[2] Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 4489-4497.
<个人网页blog已经上线,一大波干货即将来袭:https://faiculty.com/>
/* 版权声明:公开学习资源,只供线上学习,不可转载,如需转载请联系本人 .*/