Big Data Analysis Techniques
本章讲解大数据分析方法。分两种类型:一是对流数据的实时分析处理;二是对不断累积的数据的批量分析处理(非实时处理)。
数据分析的基本类型:
定量分析、定性分析、数据挖掘、统计分析、机器学习、语义分析、视觉分析。下面逐一详述。
1.定量分析(Quantitative Analysis)
定量分析指对数据中的特征或关联关系进行量化,基于统计方式,结果以数值的方式表达。分析结果可以涵盖较大数据集。
2.定性分析(Qualitative Analysis)
定性分析描述数据的特质,相对于定量分析,定性分析专注于更小的数据集,进行更加深入的分析,分析结果通常不可量化,不能通过数字表达。
3.数据挖掘(Data Mining)
数据挖掘是针对大数据集的专业数据分析方式,通常采用自动的基于软件编程实现的方式,挖掘大量数据集中数据的特征和趋势。数据挖掘是预测性分析和商业智能的基础。
4.统计分析(Statistical Analysis)
统计分析是基于数学公式对数据进行分析。统计分析通常是定量的,但也可以是定性的。统计分析通常通过总结的方式来描述数据集,采用平均值、中位数等统计描述方式来描述数据集,也可采用回归或关联性分析来描述数据的特征和关系。
书中详述了三种统计分析方式:A/B测试、相关性分析、回归性分析。
1)A/B测试(A/B Testing)
A/B测试,又被成为split testing或bucket testing,通常是指基于预定标准来对比两个版本的元素,判断哪个更优。这里的元素可以是某个网页,也可以是某个产品或某项服务等等。现有版本的元素称为control version,修改后的元素称为treatment,也就是modified version。
A/B测试可被应用于多种领域,最常用于市场类分析。
2)相关性分析(Correlation)
相关性分析用于分析两个变量是否相关,如果相关,会进一步分析相关方式和程度。相关性分析用于发现解释现象的某种关系,用于揭示数据集的本质或揭示某种现象的原因。
两个变量之间的相关系数在-1到1之间。相关系数为1时,两变量为强正相关;相关系数为0时,两变量不相关;相关系数为-1时,两变量为强负相关。

3)回归性分析(Regression)
回归性分析用于发现因变量(dependent variable)与自变量(independent variable)之间的关系,也就是明确因变量会与自变量存在怎样的关联。例如:当自变量增长时,因变量是否也增长?这种增长是线性的还是非线性的?

在一次回归性分析中可有多个因变量。通过回归性分析可更好的理解现象本质,也可对因变量进行预测性分析。
回归性分析与关联性分析不同,关联性分析不会明确因果关系,关联分析中假设两个变量独立。而回归性分析明确因果关系,这种因果关系可以是直接的或间接的。
在大数据分析中,可先进行关联性分析,确定变量之间的关联关系后,再进行回归性分析,用于发现变量之间是否存在因果关系。
5.机器学习(Machine Learning)
机器学习是将人类的认知能力与机器的快速处理能力相结合,使机器能够在无需人类干预的情况下对数据进行分析处理。
书中详述了几类机器学习:分类(Classification)、聚类(Clustering)、异常检测(Outlier Detection)、过滤(Filtering)。
1)分类(有监督的机器学习)
分类是一种有监督的机器学习方式,将数据分类至预先定义好的类别中。分两步:
步骤1:将已经分类或打标签的训练数据导入系统中,使该系统明确不同分类,具有对数据进行分类的能力;
步骤2:将未分类未打标签的数据导入系统中,系统对这些数据进行分类和打标签。

典型的应用场景是过滤垃圾邮件。
2)聚类(无监督的机器学习)
聚类是一种无监督的机器学习方式,将数据分类至不同的类别中,这些类别没有经过预先定义,同一类别中的数据有着相似的属性。数据如何分类取决于所采用的聚类算法,不同的聚类算法用不同的方式定义数据分类。
聚类分析用于理解给定数据集的属性,聚类后得到的分类可用于预测相似的数据集。
3)异常检测
异常检测用于发现那些明显不同于数据集中其他数据的数据。这种机器学习方式可发现异常、畸变、偏差,用于发现机会或定位风险。异常检测可基于监督的或无监督的机器学习,与分类和聚类相关。

如上图,在对数据进行分类或聚类的基础上,发现异常数据。
4)过滤
过滤是在众多数据中找出所需数据的自动过程。过滤方式可基于单个用户行为或多用户行为,对应两种不同的过滤方式:content-based filtering(基于内容的过滤)和collaborative filtering(协同过滤)。
例如网购中常见的推荐系统:
基于内容的过滤是基于单个用户行,关注用户与商品的关联性,先根据用户过去的购买行为对其进行用户行为分析,形成用户画像,再基于此对商品进行过滤,将过滤结果推荐给用户。
协同过滤是基于多用户行为,关注用户与其他用户的相似性,先根据用户过去的购买行为找出其他与之相似的用户,再依据其他用户的行为对商品进行过滤,将过滤结果推荐给用户。
6.语义分析
语言片段在不同的语境中可有不同的含义,语义分析是使机器能够像人类一样分辨这些不同含义,从文本或语音中提取信息。
书中详述三种语义分析:自然语言处理、文本分析、情感分析。
1)自然语言处理(Natural Language Processing)
自然语言处理是指计算机能够理解人类的文本或语言,是实现人与计算机之间用自然语言进行有效通信的方法。自然语言处理使计算机能够进行诸如全文检索之类的多种工作。自然语言处理能力的获取同样需要训练数据,训练数据越多,自然语言处理结果越准确。
2)文本分析(Text Analysis)
相对于结构化数据,非结构化的文本数据通常难以分析和检索。文本分析是通过数据挖掘、机器学习和自然语言处理进行的对文本数据的专业分析,提取非结构化文本中的信息。
3)情感分析(Sentiment Analysis)
情感分析是文本分析的一种,专注分析用户的情感、偏见或情绪等等,是在自然语言的上下文中,通过对本文的分析来获取用户的态度。情感分析不仅分析用户的感受,也分析用户感受的强烈程度。商家通常通过对用户的情感分析来定位产品,进行辅助决策。
7.视觉分析
视觉分析是利用图表来表达数据,以触发或增强用户的视觉感知。相对于文本和数据,图表表达的信息往往能够更加直观地被用户感知,故视觉分析是大数据领域中重要的分析方式。(小编注:从这个角度来讲,数据可视化,也就是这里所说的视觉分析,属于大数据分析领域。)
书中详述几种视觉分析方法:热点图、时间序列图、网络图、空间数据制图。
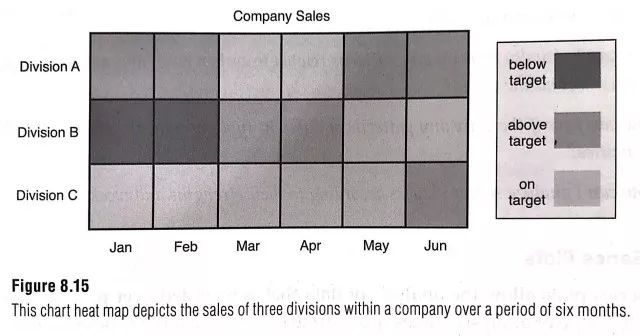
1)热点图(Heat Maps)
热点图可以是图表形式的或者是地图形式的,用于显示和表达整体中个体的不同。

2)时间序列图(Time Series Plots)
时间序列图用于展示数据随时间的变化,常用于进行趋势预测。

3)网络图(Network Graphs)
网络图用于展示多个数据个体之间的联系,这种联系可以是单一的或是多重的。

4)空间数据制图(Spatial Data Mapping)
空间数据制图是结合地理信息,对数据进行基于地图的可视化展示。
(小编注:数据可视化的方式还有很多,不只书中提到的这几种,但万变不离其宗,无非是数据、设计、表达、逻辑关系的不同排列组合)
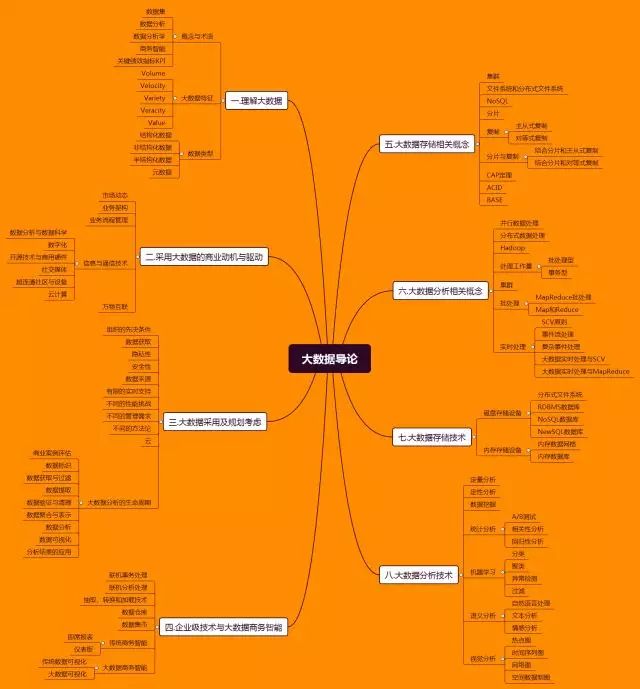
这是《大数据导论》读书笔记系列的最后一篇,奉上配图两张,分别是:《大数据导论》全书的章节结构,以及读书笔记系列下一篇的预告。(微信公众号后台回复“大数据导论”获取高清版图片)

相关文章:
《大数据导论》读书笔记——Chapter 1
《大数据导论》读书笔记——Chapter 2
Big Data Adoption and Planning Consideration
《大数据导论》读书笔记——Chapter 4
《大数据导论》读书笔记——Chapter 5
《大数据导论》读书笔记——Chapter 6
《大数据导论》读书笔记——Chapter 7(1)
《大数据导论》读书笔记——Chapter 7(2)
慢火烹茶看图说话——铁路&民航
慢火烹茶看图说话——国语&粤语
慢火烹茶看图说话——2018北京春夏赏花小贴士
END

