MXNet: A Flexible and Efficient Machine LearningLibrary for Heterogeneous Distributed Systems
https://www.researchgate.net/publication/286134669_MXNet_A_Flexible_and_Efficient_Machine_Learning_Library_for_Heterogeneous_Distributed_Systems
MXnet:一个灵活、高效的异构分布式系统机器学习库。
摘要
MXnet是一个多语言机器学习(ML)库,用于简化ML算法的开发,特别是对于深度神经网络。它嵌入在宿主语言中,将声明性符号表达式与命令式张量计算混合在一起。它提供自动微分来推导梯度。MXnet具有计算和内存效率,可以在各种异构系统上运行,从移动设备到分布式GPU集群。
本文描述了MXNET的API设计和系统实现,并解释了如何统一处理符号表达式和张量运算的嵌入。我们的初步实验表明,在使用多个GPU机器的大规模深度神经网络应用中,有着很好的结果。
1 引言
机器学习(ML)算法的规模和复杂性越来越大。几乎所有最近的ImageNet挑战[12]的获奖者都使用具有很深层次的神经网络,需要数十亿次浮点运算来处理一个样本。结构和计算复杂度的提高对ML系统的设计和实现提出了有趣的挑战。大多数ML系统将域SPECI C语言(DSL)嵌入到宿主语言(例如Python、Lua、C++)中。可能的编程范例包括命令式的,在命令式的,用户指定确切的“如何”计算需要执行,以及声明式的,在声明式的,用户指定的重点。
关于“要做什么”。命令式编程的例子包括numpy和matlab,而caffe、cxxnet等包在层定义上进行抽象并隐藏实际实现的内部工作。二者之间的分界线有时可能是模糊的,像theano和最近的张量流这样的框架也可以看作两者的混合物,它们声明了一个计算图,但图中的计算必须是特定的。
与编程范式问题相关的是如何进行计算。执行可以是具体的,结果立即在同一线程上返回,或者异步或延迟执行,在将语句发布到可用设备之前,首先将其收集并转换为数据流图作为中间表示。这两个执行模型对如何发现固有的并行性有不同的含义。具体执行是限制性的(例如并行矩阵乘法),而异步/延迟执行则会自动识别数据流图实例范围内的所有并行性。
编程范式和执行模型的结合产生了一个很大的设计空间,其中一些空间比其他空间更有趣(也更有效)。事实上,我们的团队和社区其他人一样,已经集体完成了一些任务。例如,Minerva[14]将命令式编程与异步执行结合起来。虽然Theano采用声明性方法,但它支持更全局的图形感知优化。在嘌呤2[10]中采用了类似的学科。相反,cxnet采用声明式编程(过度张量抽象)和具体的执行,类似于caffe[7]。表1给出了更多的例子。
| - | 命令式程序 | 声明性程序 |
|---|---|---|
| 执行a = b+1 | 计算结果并将其存储在a上,就像b的类型一样。 | 返回计算图;将数据绑定到b并稍后进行计算。 |
| 优势 | 概念简单,通常与宿主语言的内置数据结构、函数、调试器和第三方库无缝工作。 | 在执行前获取整个计算图,有利于优化性能和内存利用率。也便于实现加载、保存和可视化等功能。 |
表1:比较域特定语言的命令式和声明式。
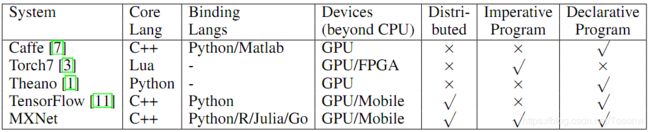
表2:与其他流行的开放源码ML库比较
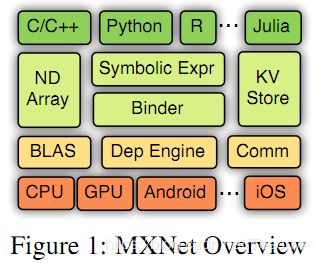
我们的合并新的努力导致了MXnet(或“混合网”),打算混合不同方法的优势。声明式编程在全局计算图上提供了清晰的边界,发现了更多的优化机会,而命令式编程提供了更多的灵活性。在深入学习的环境中,声明式编程在神经网络配置中指定计算结构时很有用,而命令式编程对于参数更新和交互式调试更为自然。我们还努力将其嵌入到多个宿主语言中,包括C++、Python、R、Go和Julia。
尽管支持多种语言和不同编程范式的组合,我们还是能够将执行融合到同一个后端引擎。引擎跟踪计算图和命令式操作之间的数据依赖性,并有效地联合调度它们。我们积极减少内存占用,尽可能执行就地更新和内存空间重用。最后,我们设计了一个紧凑的通信API,使得MXnet程序可以在多台机器上运行,而不会发生任何变化。
与其他开放源码ML系统相比,MXnet为Torch7[3]、Theano[1]、Chainer[5]和Caffe[7]提供了超集编程接口,并支持更多系统,如GPU集群。MXnet与TensorFlow[11]很接近,但可以另外嵌入命令式张量操作。MXNet是轻量级的,例如预测代码T到单个50K行C++源代码中,没有其他依赖性,并且有更多的语言支持。更详细的比较如表2所示。
2 编程接口
2.1 符号:声明性符号表达式
MXNet 使用多输出符号表达式,符号,声明计算图。符号由运算符组成,例如简单的矩阵运算(例如“+”)或复杂的神经网络层(例如卷积层)。一个运算符可以接受多个输入变量,生成多个输出变量,并具有内部状态变量。变量可以是自由的,稍后我们可以用值绑定它,也可以是另一个符号的输出。图2显示了通过链接一个变量(显示输入数据)和多个层操作符来构造多层感知符号。
using MXNet
mlp = @mx.chain mx.Variable(:data) =>
mx.FullyConnected(num_hidden=64) =>
mx.Activation(act_type=:relu) =>
mx.FullyConnected(num_hidden=10) =>
mx.Softmax()
图2:Julia中的符号表达式构造。
>>> import mxnet as mx
>>> a = mx.nd.ones((2, 3), mx.gpu())
>>> print (a * 2).asnumpy()
[[ 2. 2. 2.]
[ 2. 2. 2.]]
图3:python中的ndarray接口
为了评估一个符号,我们需要用数据绑定自由变量并声明所需的输出。除了评估(“forward”),符号还支持自动符号区分(“backward”)。还为符号提供了其他功能,如加载、保存、内存估计和可视化。
2.2 NDArray:命令张量计算
MXnet提供了带强制张量计算的ndarray,以弥补声明性符号表达式和宿主语言之间的差距。图3显示了一个在GPU上执行矩阵常量乘法,然后按numpy.ndarray打印结果的示例。
ndarray抽象与符号声明的执行无缝工作,我们可以将前者的命令张量计算与后者混合。例如,给出一个符号神经网络和权重更新函数,例如w = w - ng,然后我们可以通过
while(1) { net.foward_backward(); net.w -= eta * net.g };
上述方法与使用单一但非常复杂的符号表达式的实现同样有效。原因是MXnet使用了延迟的ndarray计算,后端引擎可以正确地解决两者之间的数据依赖关系。
2.3 KVStore:设备上的数据同步
KVStore是一个分布式的键值存储,用于在多个设备上进行数据同步。它支持两个原语:将一个键-值对从设备推到存储,并从存储中提取键的值。此外,用户定义的更新程序可以指定如何合并推送的值。最后,通过一致性模型[8]控制模型发散。目前,我们支持顺序和最终的一致性。
下面的例子通过数据并行实现了分布式梯度下降。
while(1){ kv.pull(net.w); net.foward_backward(); kv.push(net.g); }
当权重更新函数注册到kvstore时,每个工作人员重复地从该存储中提取最新的权重,然后推出本地计算的梯度。
与单个声明性程序相比,上面的混合实现具有相同的性能,因为实际的数据推送和拉取是由延迟评估执行的,后者和其他的一样由后端引擎调度。
2.4其他模块
MXnet 附带工具,可以将任意大小的示例打包到单个紧凑文件中,以方便顺序搜索和随机搜索。还提供了数据迭代器。数据预取和预处理是多线程的,减少了由于可能的远程文件存储读取和/或图像解码和转换而产生的开销。
训练模块实现了常用的优化算法,如随机梯度下降。它在给定的符号模块和数据迭代器上训练模型,如果提供了额外的kvstore,则可以选择分布式。
3 实施
3.1 计算图
将一个绑定的符号表达式表示为一个计算图进行计算。图4显示了图2中MLP符号向前和向后图形的一部分。在评估之前,MXNET转换图形以优化效率并将内存分配给内部变量。
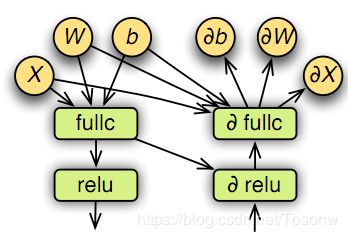
图4:向前和向后的计算图。
图形优化: 我们将探讨以下简单的优化。我们首先注意到,只需要获得绑定期间指定输出所需的子图。例如,在预测中,只需要前向图,而从内部层提取特征时,可以跳过最后一层。其次,可以将运算符分组为单个运算符。例如,a x b +1 被单个BLAS或GPU调用替换。最后,我们手工实现了优化的“big”操作,如神经网络中的一个层。
内存分配: 请注意,每个变量的生命周期,即创建和最后一次之间的时间段,将用于计算图。因此,我们可以为不相交的变量重用内存。然而,理想的分配策略需要 O(n2) 时间复杂性,其中n是变量数。
我们提出了两种具有线性时间复杂性的启发式算法。第一个调用inplace,模拟遍历图的过程,并保留到目前为止尚未使用的依赖节点的引用计数器。如果计数器达到零,内存将被回收。第二个名为co-share,它允许两个节点共享一段内存,前提是它们不能并行运行。探索共同共享会施加一个额外的依赖约束。特别是,每次调度时,在图中的挂起路径中,我们都会确定最长的路径并执行所需的内存分配。
3.2 依赖引擎
在MXnet中,每个源单元,包括ndarray、随机数生成器和时间空间,都用一个唯一的标记注册到引擎中。然后,任何操作(如矩阵操作或数据通信)都会被推送到引擎中,并指定所需的资源标记。如果解决了依赖关系,引擎会连续调度推送的操作以供执行。由于通常存在多个计算资源,如CPU、GPU和内存/PCIe总线,因此该引擎使用多个线程来调度操作,以获得更好的资源利用率和并行化。
与大多数数据流引擎不同[14],我们的引擎将突变操作作为一个现有的资源单元进行跟踪。也就是说,我们的支持一个操作除了读取之外还将写入的标记的特定化。这使得可以像numpy和其他张量库那样调度数组突变。它还可以通过将参数更新表示为参数数组的变化,更容易地实现参数的内存重用。它还使一些特殊操作的调度变得更容易。例如,当生成具有相同随机种子的两个随机数时,我们可以通知引擎它们将写入种子,这样它们就不应该并行执行。这有助于再现性。
3.3 数据通信
我们基于参数服务器[8,9,4]实现了kvstore(图5)。它与以前的工作在两个方面有所不同:第一,我们使用引擎来调度kvstore操作和管理数据一致性。该策略不仅使数据同步与计算无缝结合,而且大大简化了实现过程。第二,我们采用两级结构,一级服务器管理单台机器内设备之间的数据同步,二级服务器管理机器间的同步。来自一级服务器的出站数据可以聚合,从而减少带宽需求;机器内和机器间的同步可以使用不同的一致性模型(例如,内部是连续的,最终是内部的)。
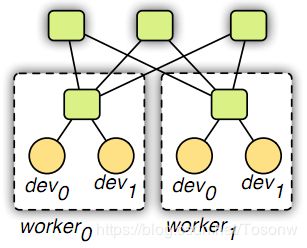
图5:通信。
4 评价
原始性能: 我们在流行的“convnet基准”上最能将mxnet与torch7、caffe和tensorflow进行比较[2]。所有这些系统都是用CUDA7.5和CUDNN3编译的,除了TensorFlow,它只支持CUDA7.0和CUDNN2。我们对所有网络使用批量大小32,并在单个Nvidia GTX 980卡上运行实验。结果如图6所示。正如预期的那样,MXnet的性能与Torch7和Caffe相似,因为大多数计算都花费在CUDA/CUDNN内核上。TensorFlow总是慢2倍,这可能是因为它使用了较低的CUDN版本。

图6:将MXnet与其他MXnet在单个前向后退性能上进行比较。
图7:mxnet在各种分配策略下的内部内存使用情况,只针对批大小为64的正向(左)和正向(右)。
内存使用情况: 图7显示了除输出外的内部变量的内存使用情况。可以看出,“inplace”和“co-share”都可以有效地减少内存占用。在模型训练过程中,将它们组合在一起可使所有网络减少2倍,并进一步提高到4倍以进行模型预测。例如,即使是最昂贵的VGG网络,培训也需要不到16MB的额外空间。
可扩展性: 我们在AmazonEC2G2.8x实例上运行了这个实验,每个实例都附带了四个Nvidia GK104 GPU和10G以太网。我们在由130万张图像和1000个类组成的ILSVRC12数据集[13]上使用批标准化[6]对Googlenet进行培训。我们将学习率固定为:05,动量固定为:9,重量衰减为0:05,并在一批中为每个GPU提供36个图像。
收敛结果如图8所示。可以看出,与单台机器相比,分布式训练在开始时收敛较慢,但在10次数据传递之后表现更好。在一台机器和10台机器上,数据传递的平均成本分别为14K和1.4K秒。因此,本实验揭示了超线性加速。
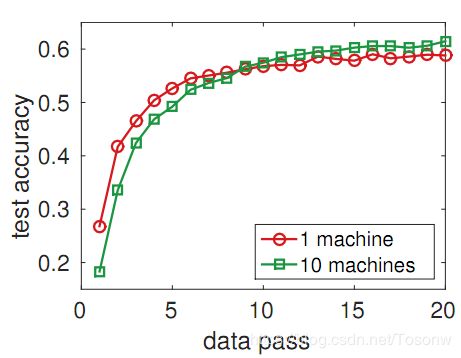
图8:1台和10台机器上的ILSVRC12数据集上的Googlenet进度。
5 结论
MXnet是一个机器学习库,将符号表达式与张量计算结合起来,以最大限度地提高效率和灵活性。它是轻量级的,嵌入多种主机语言,并且可以在分布式设置中运行。实验结果令人鼓舞。虽然我们继续探索新的设计选择,但我们相信它已经有利于相关的研究团体。这些代码可在 http://dmlc.io 上找到。
文献
- [1] Fr´ed´eric Bastien, Pascal Lamblin, Razvan Pascanu, James Bergstra, Ian Goodfellow, Arnaud
Bergeron, Nicolas Bouchard, David Warde-Farley, and Yoshua Bengio. Theano: new features
and speed improvements. arXiv preprint arXiv:1211.5590, 2012. - [2] Soumith Chintala. Easy benchmarking of all public open-source implementations of convnets,
- https://github.com/soumith/convnet-benchmarks.
- [3] Ronan Collobert, Koray Kavukcuoglu, and Cl´ ement Farabet. Torch7: A matlab-like envi-
ronment for machine learning. In BigLearn, NIPS Workshop, number EPFL-CONF-192376,
- [4] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. Le, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and A. Ng. Large scale distributed deep networks. In Neural Information Processing Systems, 2012.
- [5] Chainer Developers. Chainer: A powerful, flexible, and intuitive framework of neural networks, 2015. http://chainer.org/.
- [6] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
- [7] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, pages 675–678. ACM, 2014.
- [8] M. Li, D. G. Andersen, J. Park, A. J. Smola, A. Amhed, V. Josifovski, J. Long, E. Shekita, and B. Y. Su. Scaling distributed machine learning with the parameter server. In OSDI, 2014.
- [9] M. Li, D. G. Andersen, A. J. Smola, and K. Yu. Communication efficient distributed machine learning with the parameter server. In Neural Information Processing Systems, 2014.
- [10] Min Lin, Shuo Li, Xuan Luo, and Shuicheng Yan. Purine: A bi-graph based deep learning framework. arXiv preprint arXiv:1412.6249, 2014.
- [11] Abadi Martn, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah,Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viegas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. Tensorflow: Large-scale machine learning on heterogeneous systems. 2015.
- [12] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
- [13] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, pages 1–42, 2014.
- [14] Minjie Wang, Tianjun Xiao, Jianpeng Li, Jiaxing Zhang, Chuntao Hong, and Zheng Zhang. Minerva: A scalable and highly efficient training platform for deep learning, 2014.