caffe cnn提取各层特征并可视化结果(Python接口)
亲测有用,之前参考的薛开宇的学习笔记,部分代码需要修改,自己修改后的版本如下:
#caffe特征的可视化
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as ima
import os
import pickle
import cv2
caffe_root='/home/falingling/caffe/'
import sys
sys.path.insert(0, caffe_root+'python')
import caffe
#显示的图表大小为 10,图形的插值是以最近为原则,图像颜色是灰色
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
#'examples/imagenet/caffe_reference_imagenet_model'
model_file = caffe_root+'models/bvlc_reference_caffenet/deploy.prototxt'
pretrained = caffe_root+ 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
image_file = caffe_root+'examples/images/cat.jpg'
#image_file = caffe_root+'examples/_temp/baby_74.jpg'
npload = caffe_root+ 'python/caffe/imagenet/ilsvrc_2012_mean.npy'
#net=caffe.Classifier(caffe_root+'examples/imagenet/deploy.prototxt',caffe_root+'examples/imagenet/caffe_reference_imagenet_model')
net = caffe.Net(model_file,pretrained,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(npload).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
im=caffe.io.load_image(image_file)
net.blobs['data'].reshape(1,3,227,227)
net.blobs['data'].data[...] = transformer.preprocess('data',im)
# 因为参考模型本来频道是 BGR,所以要将 RGB 转换
#参考模型运行在【0,255】的灰度,而不是【0,1】
#net = caffe.Classifier(model_file, pretrained,image_dims=(256,256),mean=np.load(npload).mean(1).mean(1),channel_swap=(2,1,0),input_scale=255)
#scores=net.predict([caffe.io.load_image(image_file)])
#print scores,,显示图片
print [(k,v.data.shape) for k,v in net.blobs.items()]
#输出网络参数
print [(k,v[0].data.shape) for k,v in net.params.items()]
#predictions=out[self.outputs[0]].squeeze(axis=None)
# our network takes BGR images, so we need to switch color channels
# 网络需要的是 BGR 格式图片,所以转换颜色频道
def show_image(im):
if im.ndim==3:
m=im[:,:,::-1]
plt.imshow(im)
#显示图片的方法
plt.axis('off') # 不显示坐标轴
plt.show()
# 每个可视化的都是在一个由一个个网格组成
def vis_square(data,padsize=1,padval=0):
data-=data.min()
data/=data.max()
# force the number of filters to be square
n=int(np.ceil(np.sqrt(data.shape[0])))
padding=((0,n**2-data.shape[0]),(0,padsize),(0,padsize))+((0,0),)*(data.ndim-3)
data=np.pad(data,padding,mode='constant',constant_values=(padval,padval))
# 对图像使用滤波器
data=data.reshape((n,n)+data.shape[1:]).transpose((0,2,1,3)+tuple(range( 4,data.ndim+1)))
data=data.reshape((n*data.shape[1],n*data.shape[3])+data.shape[4:])
#show_image(data)
plt.imshow(data)
# plt.axis('off') # 不显示坐标轴
plt.show()
out = net.forward()
#image=net.blobs['data'].data[4].copy()
#show_image(image.transpose(1,2,0))
#image-=image.min()
#image/=image.max()
#show_image(image.transpose(1,2,0))
#网络提取conv1的卷积核
#filters = net.params['conv1'][0].data
#vis_square(filters.transpose(0, 2, 3, 1))
#过滤后的输出,96 张 featuremap
feat =net.blobs['conv1'].data[0,:40]
vis_square(feat,padval=1)
#第二个卷积层,我们只显示前面 48 个滤波器,每一个滤波器为一行。
filters = net.params['conv2'][0].data
#vis_square(filters[:48].reshape(48**2, 5, 5))
#第二层输出 256 张 feature,这里显示 20 张。
feat = net.blobs['conv2'].data[0, :20]
#vis_square(feat, padval=1)
#第三个卷积层:全部 384 个 feature map
feat = net.blobs['conv3'].data[0]
#vis_square(feat, padval=0.5)
#第四个卷积层:全部 384 个 feature map
feat = net.blobs['conv4'].data[0]
#vis_square(feat, padval=0.5)
#第五个卷积层:全部 256 个 feature map
feat = net.blobs['conv5'].data[0]
#vis_square(feat, padval=0.5)
#第五个 pooling 层
feat = net.blobs['pool5'].data[0]
#vis_square(feat, padval=1)
#第六层输出后的直方分布
feat=net.blobs['fc6'].data[0]
#plt.subplot(2,1,1)
#plt.plot(feat.flat)
#plt.subplot(2,1,2)
#_=plt.hist(feat.flat[feat.flat>0],bins=100)
#显示图片的方法
#plt.axis('off') # 不显示坐标轴
#plt.show()
#第七层输出后的直方分布
feat=net.blobs['fc7'].data[0]
#plt.subplot(2,1,1)
#plt.plot(feat.flat)
#plt.subplot(2,1,2)
#_=plt.hist(feat.flat[feat.flat>0],bins=100)
#plt.show()
#对后输出后的直方分布
#feat=net.blobs['prob'].data[0]
#plt.subplot(2,1,1)
#plt.plot(feat.flat)
#plt.show()
#看标签
#执行测试
image_labels_filename=caffe_root+'data/ilsvrc12/synset_words.txt'
#try:
labels=np.loadtxt(image_labels_filename,str,delimiter='\t')
top_k=net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
#print labels[top_k]
for i in np.arange(top_k.size):
print top_k[i], labels[top_k[i]]
每次只能显示一张特征图,可以去掉对应的图片显示的代码的注释#,来显示所需要的某层的图像。
显示的网络结构信息如图:
参数信息如图:
卷积层1的过滤器可视化为:
第一个卷积层过滤后的输出,显示96 张(代码中写的是40,可自行修改) :
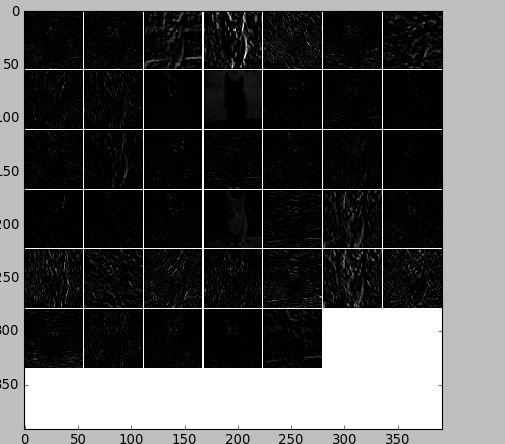
第二层输出 256 张 feature,这里显示 20 张:

第三个卷积层:全部 384 个 feature map:

第四个卷积层:全部 384 个 feature map:
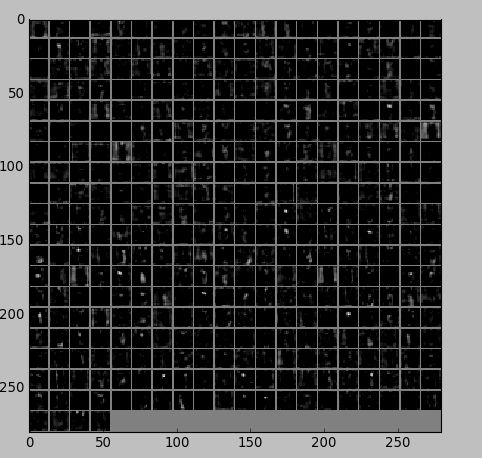
第五个卷积层:全部 256 个:
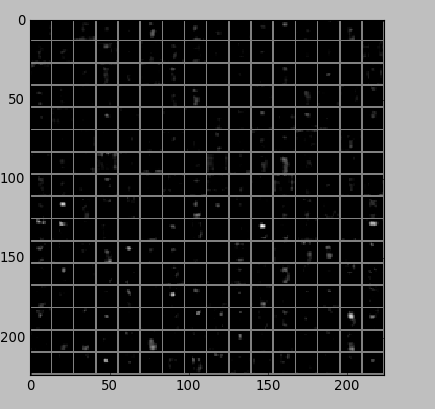
第五个 pooling 层:
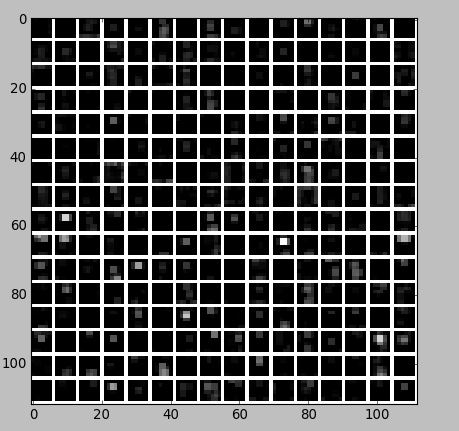
第六层输出后的直方分布: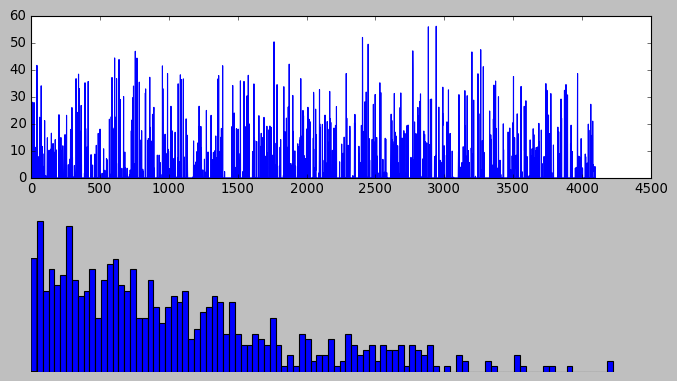
第七层输出后的直方分布:
对后输出后的直方分布: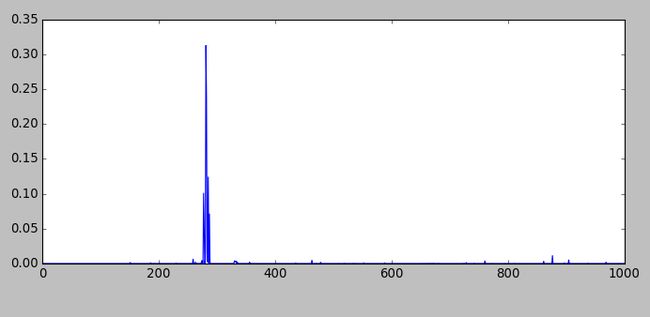
最终的分类结果显示:
结果可以看出确定是正确的分类。