我的PaddlePaddle学习之路——Ubuntu安装PaddlePaddle
目录
一、安装Vmware+Ubuntu
二、确认Ubuntu的Python版本
1.列出python版本号
2.配置默认解释器
3.验证python版本
三、安装pip
四、安装PaddlePaddle
五、训练与预测
一、安装Vmware+Ubuntu
Vmware14.0 提取码:9473
Ubuntu16.04.5 提取码:yyqo
过程就不详细叙述了,详情请点击链接,大抵相同~
二、确认Ubuntu的Python版本
使用update-alternatives 来为整个系统更改Python默认版本
1.列出python版本号
sudo update-alternatives --list python输入密码后,起始会显示 update-alternatives:错误:无python的候选项。
这说明Python 的替代版本尚未被 update-alternatives 命令识别。
想解决这个问题,我们需要更新一下替代列表:
ls -l /usr/bin/python /usr/bin/python3 ![]()
将python2.7和python3.5放入其中,使用如下命令将python2.7和python3.5加入到python列表中:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 1
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.5 2列出python版本号:
sudo update-alternatives --list python 
2.配置默认解释器
sudo update-alternatives --config python 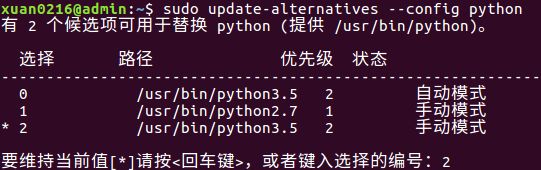
选择编号2,选择python3.5。
3.验证python版本
python 
三、安装pip
如果你还没有在pip命令的话,首先要安装pip,安装pip命令如下:
sudo apt install python-pip安装之后,还有看一下pip的的版本:
pip --version如果版本低于9.0.0,那要先升级pip,否则可能无法安装paddlepaddle。先要下载一个升级文件,命令如下:
wget https://bootstrap.pypa.io/get-pip.py下载完成之后,可以使用这个文件安装最新的pip了:
python get-pip.py
四、安装PaddlePaddle
使用pip安装paddlepaddle:
pip install --user paddlepaddle测试看看paddlepaddle有没有,在python的命令终端中试着导入paddlepaddle包:
import paddle.fluid as fluid 
如果没有报错的话就证明paddlepaddle安装成功啦~
五、训练与预测
新建test.py:
# Include libraries.
import paddle
import paddle.fluid as fluid
import numpy
import six
# Configure the neural network.
def net(x, y):
y_predict = fluid.layers.fc(input=x, size=1, act=None)
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_cost = fluid.layers.mean(cost)
return y_predict, avg_cost
# Define train function.
def train(save_dirname):
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
y_predict, avg_cost = net(x, y)
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_cost)
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.uci_housing.train(), buf_size=500),
batch_size=20)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
def train_loop(main_program):
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
exe.run(fluid.default_startup_program())
PASS_NUM = 1000
for pass_id in range(PASS_NUM):
total_loss_pass = 0
for data in train_reader():
avg_loss_value, = exe.run(
main_program, feed=feeder.feed(data), fetch_list=[avg_cost])
total_loss_pass += avg_loss_value
if avg_loss_value < 5.0:
if save_dirname is not None:
fluid.io.save_inference_model(
save_dirname, ['x'], [y_predict], exe)
return
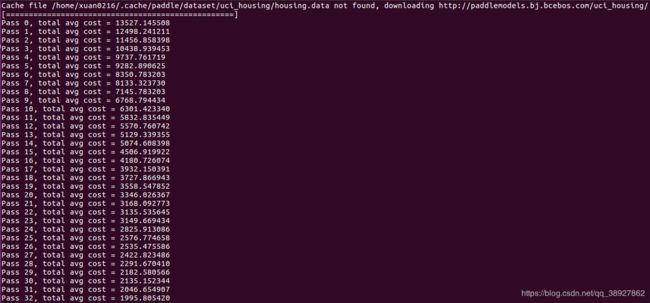
print("Pass %d, total avg cost = %f" % (pass_id, total_loss_pass))
train_loop(fluid.default_main_program())
# Infer by using provided test data.
def infer(save_dirname=None):
place = fluid.CPUPlace()
exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):
[inference_program, feed_target_names, fetch_targets] = (
fluid.io.load_inference_model(save_dirname, exe))
test_reader = paddle.batch(paddle.dataset.uci_housing.test(), batch_size=20)
test_data = six.next(test_reader())
test_feat = numpy.array(list(map(lambda x: x[0], test_data))).astype("float32")
test_label = numpy.array(list(map(lambda x: x[1], test_data))).astype("float32")
results = exe.run(inference_program,
feed={feed_target_names[0]: numpy.array(test_feat)},
fetch_list=fetch_targets)
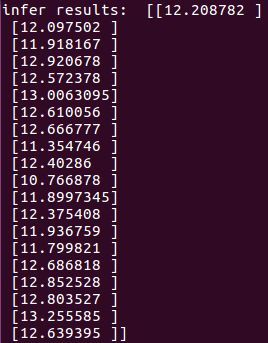
print("infer results: ", results[0])
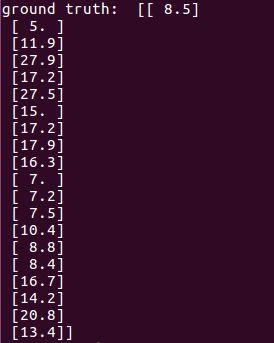
print("ground truth: ", test_label)
# Run train and infer.
if __name__ == "__main__":
save_dirname = "fit_a_line.inference.model"
train(save_dirname)
infer(save_dirname)编译运行python文件:
python test.py运行结果:
参考资料
https://blog.csdn.net/qq_33200967/article/details/79071926#pip_147
http://www.paddlepaddle.org/