pyMongo操作指南:增/删/改/查/合并/统计与数据处理
文章目录
- 1 mongodb安装
- 1.1 下载 MongoDB 镜像
- 1.2 运行 MongoDB 镜像
- 1.3 添加管理员账号
- 1.4 用新创建的 root 账户连接,测试一下
- 2 可视化界面Robo 3T
- 3 pymongo增删改查
- 3.1 数据库连接
- 3.2 建表collection
- 3.3 文档插入与删除
- 关于Unicode编码的字符串注意点
- 3.4 数据更新update
- 3.5 数据替换replace
- 3.6 查询
- 3.6.1 单条与多条查询
- 3.6.2 使用操作符指定条件查询
- 3.6.3 查询 - 逻辑与/非
- 3.6.4 "$in" - 判断键值是否为null
- 3.6.5 "$all" - 数组精确匹配
- 3.6.6 "$in"、"$nin"
- 3.6.7 "$and" - 选择出满足该数组中所有表达式的文档
- 3.6.8 "$nor" - 选择出都不满足该数组中所有表达式的文档
- 3.6.9 "$not" - 选择出不能匹配表达式的文档
- 3.6.10 "$or" - 选择出至少满足数组中一条表达式的文档
- 3.6.11 "$exists" - 选择存在该字段的文档
- 3.6.12 "$regex" - 对字符串的执行正则匹配
- 3.6.13 计数 聚集记录的总数
- 3.6.14 查询 - 排序
- 3.7 加索引
- 3.8 数据聚合
- 4 数据库备份与恢复
- 4.1 备份
- 4.2 导入
- 4.3 恢复
- 4.4 超大规模数据导出
- 延伸一:内存问题
- 延伸二:一开始占用内存到80%,后来一直上升,95%,再后来就OOM了
- 延伸三:BulkWriteError: batch op errors occurred
- 参考文献
1 mongodb安装
一文教你如何通过 Docker 快速搭建各种测试环境这篇超帅,教你阿里云服务器快速安装,redis、mysql、mongoDB、elesticsearch等,而且比较全,刚好满足最近笔者的所有需求。
1.1 下载 MongoDB 镜像
这里以 mongo 4 版本为例,下载镜像:
docker pull mongo:4
下载完成后,确认一下镜像是否下载成功:
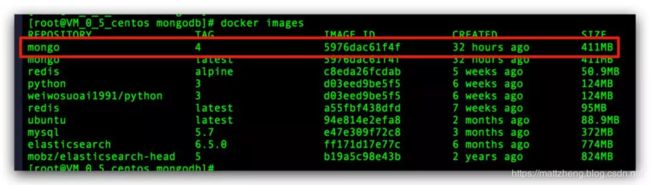
验证 MongoDB 镜像是否下载成功
1.2 运行 MongoDB 镜像
下载成功后,运行 MongoDB 镜像:
docker run -d \
--name mongo \
-v /etc/localtime:/etc/localtime:ro \
-v /home/docker/mongo/configdb:/data/configdb \
-v /home/docker/mongo/data:/data/db \
-p 27017:27017 \
mongo:4 \
--auth
其中,--auth的代表是否需要身份验证,其他相关参数:
- -d:以后台的方式运行;
- –name mongo:指定容器名称为 mongo;
- -v /usr/local/docker/mongo/configdb:/data/configdb:将容器中 /data/configdb 目录挂载到宿主机的 /usr/local/docker/mongo/configdb 目录下;
- -v /usr/local/docker/mongo/data:/data/db:将容器中 /data/db 数据目录挂载到宿主机的 /usr/local/docker/mongo/data 目录下;
- -p 27017:27017:将容器的 27017 端口映射到宿主机的 27017 端口;
执行命令完成后,查看下容器是否启动:

1.3 添加管理员账号
执行命令:
docker exec -it mongo mongo admin
然后,创建一个拥有最高权限 root 账号:
db.createUser({user:'admin',pwd:'qwer@1234',roles:[ {role:'root',db:'admin'} ]})
创建成功后,你会看到 Successfully added user:
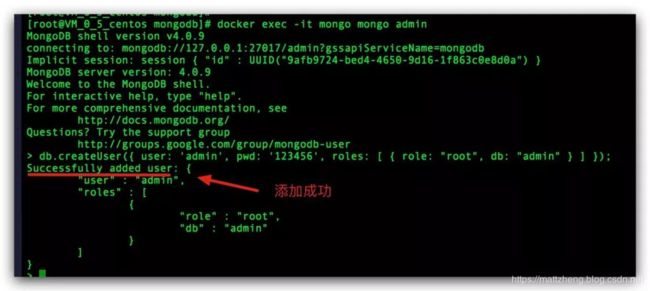
1.4 用新创建的 root 账户连接,测试一下
docker run -it --rm --link mongo:mongo mongo mongo -u admin -p qwer@1234 --authenticationDatabase admin mongo/admin
连接成功后,我们可以执行相关 SQL:
显示所有的数据库:
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
使用某个数据库:
use admin
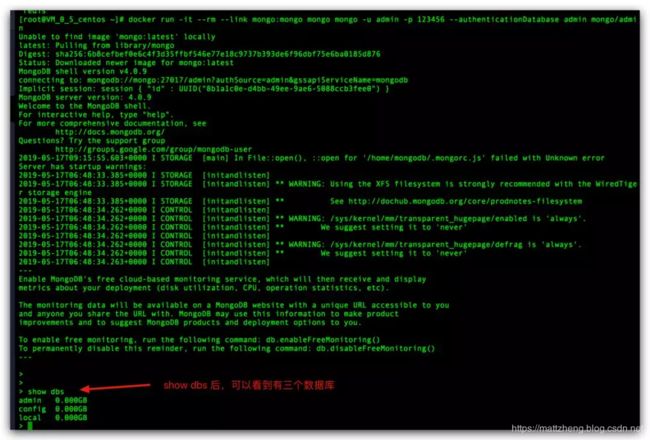
输入命令 exit,退出连接!
2 可视化界面Robo 3T
Studio 3T:专业人士使用的,需要付费。
Robo 3T:虽然免费,但是大部分功能都已经足够。
安装连接:
https://robomongo.org/download
可参考连接:MongoDB可视化工具–Robo 3T 使用教程

3 pymongo增删改查
Python driver for MongoDB
pymongo的安装:
pip3 install --pre pymongo -i https://pypi.tuna.tsinghua.edu.cn/simple
3.1 数据库连接
import urllib
from pymongo import MongoClient
#urllib.parse.quote_plus(user)
user = "admin"
password = "qwer@1234"
host = 'xxx.xxx.xxx.xxx'
port = 27017
client = MongoClient('mongodb://{0}:{1}@{2}:{3}'.format(urllib.parse.quote_plus(user),urllib.parse.quote_plus(password),host,port))
db = client.mydb
因为是阿里云上的服务器,又需要验证,之前一直报错:
pymongo.errors.OperationFailure: Authentication failed.
这网上一大堆解决教程,真尼玛都是哪个版本的解决方案。。后面,找到这个上面的方式联通了。。
3.2 建表collection
# 创建聚集 - 相当于建表
collection = db.my_collection
# posts = db.posts 可以随意取名字
# 所有聚集的名称
db.collection_names()
>>> ['my_collection']
查询集合中文档并返回结果为游标的文档集合:
# 方法一
db.getCollection(cname).find(query, projection)
# 方法二
db.cname.find(query, projection)
3.3 文档插入与删除
import datetime
# 单条信息插入
collection.insert({"key1":"value1","key2":"value2"})
# 多条插入
# 可以插入不等长的dict形式数据
new_posts = [{"author": "Mike",
"text": "Another post!",
"tags": ["bulk", "insert"],
"date": datetime.datetime(2009, 11, 12, 11, 14)},
{"author": "Eliot",
"title": "MongoDB is fun",
"text": "and pretty easy too!",
"date": datetime.datetime(2009, 11, 10, 10, 45)}]
collection.insert(new_posts)
可以支持不定长插入。
# 删除记录
collection.remove() # 删除collection
result = collection.delete_many({}) # 删除collection中所有
# 销毁一个集合
collection.drop()
# 按条件删除
result = collection.remove({"key1":"value1"})
result.deleted_count # 被删除的个数
下面的操作将删除所有复合条件的文档。
批量插入:insertMany
result=col_python.insert_many(data,ordered=False) #ordered设为False
当使用db.collection.insertMany()插入多文档时,使用ordered: false 选项跳过插入错误的文档,不中断插入操作。
其中:
- ordered = True,遇到错误 break, 并且抛出异常
- ordered = False,遇到错误 continue, 循环结束后抛出异常
关于Unicode编码的字符串注意点
你可能已经注意到了我们之前存储的通常的Python字符串和我们从服务器上获取到的不一样(u’Mike’而不是’Mike’)。做个简短的解释。
MongoDB使用BSON格式存储数据。BSON字符串是UFT-8编码的,所以PyMongo必须确保它保存的任何字符串只包含正确的UTF-8数据。通常的字符串(以单引号包裹的)被验证之后便不加改动得存储起来。而Unicode字符串会被先编码成UTF-8格式。在我们的例子中,Python命令行中的字符串,像u’Mike’替代了’Mike’这样的原因是,PyMongo将每个BSON字符串都解码成了Unicode,而不是常规字符串
3.4 数据更新update
# 单文档更新
# 将更新第一个符合name等于Juni这个条件的文档。使用$set操作符更新cuisine字段且将lastModified修改为当前日期。
updateFilter = {'_id': item['_id']}
updateRes = db.restaurants.update_one(filter = updateFilter,
update = {'$set': dict(item)},
upsert = True)
#要查看符合筛选器条件的文档数目,通过访问UpdateResult对象的matched_count属性。
result.matched_count
#要查看更新操作中被修改的文档数目,通过访问UpdateResult对象的modified_count属性。
result.modified_count
如果找不到符合条件的记录,就插入这条记录(upsert = True)
更新的时候会返回一些字段内容,其中:
1、updatedExisting:false,表示没有修改到document
2、n:0, 表示修改到数据为0
正常修改到数据会返回一个value,这个value为被修改的document
# 多文档更新
result = db.restaurants.update_many(
{"address.zipcode": "10016", "cuisine": "Other"},
{
"$set": {"cuisine": "Category To Be Determined"},
"$currentDate": {"lastModified": True}
}
)
result.matched_count
#要查看符合筛选器条件的文档数目,通过访问UpdateResult对象的matched_count属性。
result.modified_count
#要查看更新操作中被修改的文档数目,通过访问UpdateResult对象的modified_count属性。
其中,部分字段更新:
# 根据筛选条件,更新部分字段:i是原有字段,isUpdated是新增字段
filterArgs = {'date':'2017-10-10'}
updateArgs = {'$set':{'isUpdated':True, 'i':100}}
updateRes = db_coll.update_many(filter = filterArgs, update = updateArgs)
print(f"updateRes: matched_count={updateRes.matched_count}, "
f"modified_count={updateRes.modified_count} modified_ids={updateRes.upserted_id}")
# 结果:updateRes: matched_count=8, modified_count=8 modified_ids=None
3.5 数据替换replace
result = db.restaurants.replace_one(
{"restaurant_id": "41704620"},
{
"name": "Vella 2",
"address": {
"coord": [-73.9557413, 40.7720266],
"building": "1480",
"street": "2 Avenue",
"zipcode": "10075"
}
}
)
result.matched_count # 匹配到的对象
result.modified_count # 修改的对象```
替换文档:
在更新之后,该文档将只包含替代文档的字段。
被修改的文档将只剩下_id、name和address字段。该文档将不再包含restaurant_id、cuisine、grades以及borough字段。
3.6 查询
值得注意的是,在数据库数量非常庞大的时候,如千万、亿级别,最好不要使用大的偏移量来查询数据,很可能会导致内存溢出,
可以使用类似find({'_id': {'$gt': ObjectId('593278c815c2602678bb2b8d')}})这样的方法来查询,记录好上次查询的_id。
3.6.1 单条与多条查询
# 单条查询
collection.find_one()
# 根据_id来进行查询 - 第一种方式
collection.find_one({"_id": collection.find_one()['_id'] })
# 根据_id来进行查询-第二种方式
from bson.objectid import ObjectId
collection.find_one({"_id": ObjectId('5d53be07b20329241578685a') })
#查询多条记录:find()不带参数返回所有记录,带参数按条件查找返回
collection.find_one({"tags":["bulk", "insert"]})
查询一条记录:find_one()不带任何参数返回第一条记录.带参数则按条件查找返回
#查看聚集的多条记录
for item in collection.find():
print (item)
用列表指定要显示哪几个字段
# select _id,key,date from galance20170801
queryArgs = {}
projectionFields = ['key','date'] # 用列表指定,结果中一定会返回_id这个字段
searchRes = db_coll.find(queryArgs, projection = projectionFields)
# 结果{'_id': 'B01EYCLJ04', 'date': '2017-08-01', 'key': 'pro audio'}
# 示例二:用字典指定要显示的哪几个字段
# select _id,key from galance20170801
queryArgs = {}
projectionFields = {'_id':True, 'key':True} # 用字典指定
searchRes = db_coll.find(queryArgs, projection = projectionFields)
# 结果{'_id': 'B01EYCLJ04', 'key': 'pro audio'}
# 示例三:用字典指定去掉哪些字段
queryArgs = {}
projectionFields = {'_id':False, 'key':False} # 用字典指定
searchRes = db_coll.find(queryArgs, projection = projectionFields)
# 结果{'activity': False, 'avgStar': 4.3, 'color': 'Yellow & Black', 'date': '2017-08-01'}
3.6.2 使用操作符指定条件查询
from datetime import datetime
result = collection.insert_one(
{
"address": {
"street": "2 Avenue",
"zipcode": "10075",
"building": "1480",
"coord": [-73.9557413, 40.7720266]
},
"borough": "Manhattan",
"cuisine": "Italian",
"grades": [
{
"date": datetime.strptime("2014-10-01", "%Y-%m-%d"),
"grade": "A",
"score": 11
},
{
"date": datetime.strptime("2014-01-16", "%Y-%m-%d"),
"grade": "B",
"score": 17
}
],
"name": "Vella",
"restaurant_id": "41704620"
}
)
cursor = collection.find({"grades.score": {"$gt": 30}})
for document in cursor:
print(document)
其中,
- $ne:不等于(not equal)
- $gt:大于(greater than)
- $lt:小于(less than)
- $lte:小于等于(less than equal)
- $gte:大于等于(greater than equal)
3.6.3 查询 - 逻辑与/非
# 查询 - 逻辑与/非
# 你可以使用逻辑与(AND)或者逻辑或(OR)组合多个查询条件。
# https://blog.csdn.net/zahuopuboss/article/details/53046524
cursor = collection.find({"cuisine": "Italian", "address.zipcode": "10075"})
for document in cursor:
print(document)
cursor = collection.find(
{"$or": [{"cuisine": "Italian"}, {"address.zipcode": "10075"}]})
for document in cursor:
print(document)
3.6.4 “$in” - 判断键值是否为null
如何检索出sex键值为null的文档,我们使用"in"、"where"操作符
" i n " 判 断 键 值 是 否 为 n u l l " in"判断键值是否为null " in"判断键值是否为null"exists"判定集合中文档是否包含该键
测试文档如下:
# 返回文档中存在sex键,且值为null的文档
# ----------------------------------
# 方法一,建议使用
db.users.find({sex:{$in:[null],$exists:true}})
# 结果为:
"_id" : ObjectId("596c5e351109af023057952b")
# 方法二,慎用:因为null不仅仅匹配自身,而且匹配键“不存在的”文档!
db.users.find({sex:null})
# 结果为:
"_id" : ObjectId("596c5e351109af0230579529")
"_id" : ObjectId("596c5e351109af023057952b")
3.6.5 “$all” - 数组精确匹配
$all: 匹配那些指定键的键值中包含数组,而且该数组包含条件指定数组的所有元素的文档,数组中元素顺序不影响查询结果。
数组中使用:
#查询出在集合inventory中 tags键值包含数组,且该数组中包含appliances、school、 book元素的所有文档:
db.inventory.find({tags:{$all:["appliances","school","book"]}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
非数组使用
文档中键值类型不是数组,也可以使用$all操作符进行查询操作
# 查询结果是相同的,匹配amount键值等于50的文档
db.inventory.find({amount: {$all:[50]}})
db.inventory.find({amount: 50})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795b9")
指定数组位置的元素
则需使用key.index语法指定下标,例如下面查询出tags键值数组中第2个元素为"school"的文档:
# 数组下标都是从0开始的,所以查询结果返回数组中第2个元素为"school"的文档:
db.inventory.find({"tags.1":"school"})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
3.6.6 “ i n " 、 " in"、" in"、"nin”
- [匹配键值等于、匹配键不等于或者不存在]指定数组中任意值的文档
# 查询出amount键值为16或者50的文档:
db.inventory.find({amount: {$in: [16, 50]}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
# 查询出amount键值不为16或者50的文档
db.inventory.find({amount: {$nin: [16, 50]}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795bd")
# 查询出qty键值不为16或50的文档,由于文档中都不存在键qty,所以返回所有文档
db.inventory.find({qty:{$nin:[16,50]}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
# 查询结果是相同的,匹配amount键值等于50的文档,只有一个值与all的操作是一样的
db.inventory.find({amount: {$in: [50]}})
db.inventory.find({amount: 50})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795b9")
3.6.7 “$and” - 选择出满足该数组中所有表达式的文档
指定一个至少包含两个表达式的数组,选择出满足该数组中所有表达式的文档
#查询name键值为“t1”,amount键值小于51的文档:
db.inventory.find({$and: [{name: "t1"},{amount: {$lt: 51}}]})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
#对于下面使用逗号分隔符的表达式列表,MongoDB会提供一个隐式的$and操作:
db.inventory.find({name:"t1",amount:{$lt: 50}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
3.6.8 “$nor” - 选择出都不满足该数组中所有表达式的文档
# 查询name键值不为“t1”,amount键值不小于50的文档:
db.inventory.find({$nor: [{name: "t1"},{qty: {$lt: 50}}]})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
# 若是文档中不存在表达式中指定的键,表达式值为false; false nor false 等于 true,所以查询结果返回集合中所有文档:
db.inventory.find({$nor: [{sale: true},{qty: {$lt: 50}}]})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
3.6.9 “$not” - 选择出不能匹配表达式的文档
# 查询amount键值不大于50(即小于等于50)的文档数据
db.inventory.find({amount: {$not: {$gt: 50}}}) # 等同于db.inventory.find({amount:{$lte:50}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
# 查询条件中的键gty,文档中都不存在无法匹配表示,所以返回集合所有文档数据。
db.inventory.find({gty: {$not: {$gt: 50}}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
3.6.10 “$or” - 选择出至少满足数组中一条表达式的文档
执行逻辑OR运算,指定一个至少包含两个表达式的数组,选择出至少满足数组中一条表达式的文档。
# 查询集合中amount的键值大于50或者name的键值为“t1”的文档:
db.inventory.find({$or: [{amount: {$gt: 50}}, {name: "t1"}]})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
3.6.11 “$exists” - 选择存在该字段的文档
如果 e x i s t s 的 值 为 t r u e , 选 择 存 在 该 字 段 的 文 档 ; 若 值 为 f a l s e 则 选 择 不 包 含 该 字 段 的 文 档 ( 我 们 上 面 在 查 询 键 值 为 n u l l 的 文 档 时 使 用 " exists的值为true,选择存在该字段的文档;若值为false则选择不包含该字段的文档(我们上面在查询键值为null的文档时使用" exists的值为true,选择存在该字段的文档;若值为false则选择不包含该字段的文档(我们上面在查询键值为null的文档时使用"exists"判定集合中文档是否包含该键)。
{
"_id" : ObjectId("596c6d761109af02305797a2"),
"name" : "t4",
"amount" : null,
"tags" : ["bag", "school", "book"]
}
# 查询不存在qty字段的文档(所有文档)
db.inventory.find({qty: {$exists: false}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
"_id" : ObjectId("596c6d761109af02305797a2")
# 查询amount字段存在,且值不等于16和58的文档
db.inventory.find({amount: {$exists: true, $nin: [16, 58]}})
如果该字段的值为null,$exists的值为true会返回该条文档,false则不返回。
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c6d761109af02305797a2")
# 0条数据
db.inventory.find({amount:{$exists:false}})
# 结果为: Fetched 0 record(s) in 1ms
# 所有的数据
db.inventory.find({amount:{$exists:true}})
# 结果为:
"_id" : ObjectId("596c605b1109af02305795b9")
"_id" : ObjectId("596c605b1109af02305795bb")
"_id" : ObjectId("596c605b1109af02305795bd")
"_id" : ObjectId("596c6d761109af02305797a2")
3.6.12 “$regex” - 对字符串的执行正则匹配
操作符查询中可以对字符串的执行正则匹配。 MongoDB使用Perl兼容的正则表达式(PCRE)库来匹配正则表达式。
语法:# options(使用options(使用regex )
i 如果设置了这个修饰符,模式中的字母会进行大小写不敏感匹配。
m 默认情况下,PCRE 认为目标字符串是由单行字符组成的(然而实际上它可能会包含多行).如果目标字符串 中没有 "\n"字符,或者模式中没有出现“行首”/“行末”字符,设置这个修饰符不产生任何影响。
s 如果设置了这个修饰符,模式中的点号元字符匹配所有字符,包含换行符。如果没有这个修饰符,点号不匹配换行符。
x 如果设置了这个修饰符,模式中的没有经过转义的或不在字符类中的空白数据字符总会被忽略,并且位于一个未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。 这个修饰符使被编译模式中可以包含注释。 注意:这仅用于数据字符。 空白字符 还是不能在模式的特殊字符序列中出现,比如序列 。
注:JavaScript只提供了i和m选项,x和s选项必须使用$regex操作符。
# 查询name键值以“4”结尾的文档
db.inventory.find({name: /.4/i});
db.inventory.find({name: {$regex: '.4', $options: 'i'}});
# 结果为:
"_id" : ObjectId("596c6d761109af02305797a2")
3.6.13 计数 聚集记录的总数
print( collection.find().count())
3.6.14 查询 - 排序
collection.find().sort("key1") # 默认为升序
collection.find().sort("key1", pymongo.ASCENDING) # 升序
collection.find().sort("key1", pymongo.DESCENDING) # 降序
collection.find().sort([("key1", pymongo.ASCENDING), ("key2", pymongo.DESCENDING)])#多列上排序
时间 + 排序的方式:
# 按时间排序
# 我们使用这个特殊的“$it”操作符来执行范围查询,同时调用sort()来对结果进行排序(以author为排序字段)
d = datetime.datetime(2009, 11, 12, 12)
for ccc in collection.find({"date": {"$lt": d}}).sort("author"):
print(ccc)
3.7 加索引
# 被创建的索引的名字
from pymongo import ASCENDING, DESCENDING
collection.create_index([("date", DESCENDING), ("author", ASCENDING)])
collection.create_index([("cuisine", pymongo.ASCENDING)])
#u'date_-1_author_1'
# 创建一个复合索引
# 该索引将先对cuisine的值输入一个升序的命令,然后对address.zipcode的值输入一个降序命令。
collection.create_index([
("cuisine", pymongo.ASCENDING),
("address.zipcode", pymongo.DESCENDING)
])
添加索引可以加速特定的查询,同时也能用来查询和排序。在本例中,我们将演示如何在一个键上创建唯一的索引,该索引排除了索引中已存在该键的值的文档。
首先,我们需要先创建索引:
>>> result = db.profiles.create_index([('user_id', pymongo.ASCENDING)], unique=True)
>>> sorted(list(db.profiles.index_information()))
[u'_id_', u'user_id_1']
请注意,我们现在有两个索引:一个是针对_id的索引(这是MongoDB自动创建的),另一个就是我们刚刚对user_id创建的索引。
现在让我们添加一些用户数据:
>>> user_profiles = [
... {'user_id': 211, 'name': 'Luke'},
... {'user_id': 212, 'name': 'Ziltoid'}]
>>> result = db.profiles.insert_many(user_profiles)
索引阻止我们插入那些user_id已经存在于Collection中的Document。
>>> new_profile = {'user_id': 213, 'name': 'Drew'}
>>> duplicate_profile = {'user_id': 212, 'name': 'Tommy'}
>>> result = db.profiles.insert_one(new_profile) # This is fine.
>>> result = db.profiles.insert_one(duplicate_profile)
Traceback (most recent call last):
DuplicateKeyError: E11000 duplicate key error index: test_database.profiles.$user_id_1 dup key: { : 212 }
3.8 数据聚合
cursor = db.restaurants.aggregate(
[
{"$group": {"_id": "$borough", "count": {"$sum": 1}}}
]
)
# $group操作符去利用一个指定的键进行分组
# $borough - borough的key
# $sum累加器进行文档的统计计算
for document in cursor:
print(document)
# 筛选并分组文档
cursor = db.restaurants.aggregate(
[
{"$match": {"borough": "Queens", "cuisine": "Brazilian"}},
{"$group": {"_id": "$address.zipcode", "count": {"$sum": 1}}}
]
)
for document in cursor:
print(document)
4 数据库备份与恢复
导出mongoexport
导入mongoimport
MongoDB中的mongoexport可将集合导出为JSON或CSV格式的文件,指的注意的CSV文件对于大部分的关系型数据库而言是支持的。
$ mongoexport -d db -c collection -o outfile --type json/csv -f fields
-h, --host 远程连接的数据库地址,默认连接本地Mongo数据库。
--port 远程连接的数据库的端口,默认为27017.
-u, --username 连接远程数据库的账户,若数据库设置了认证,需指定账户。
-p, --password 连接远程数据库账户对应的密码
--authenticationDatabase 认证的数据库
-d, --db 数据库名称
-c, --collection 集合名称
-o, --out 导出的文件名
--type 导出的文件格式,默认为JSON,可选CSV、JSON。
-f, --fields 导出的字段,多字段以逗号分隔,当输出格式为CSV是必须指定输出的字段,CSV大部分关系型数据库都支持。
-q, --query 查询条件
--skip 跳过指定数量的数据
--limit 读取指定数量的数据记录
--sort 对数据进行排序,可指定排序的字段,使用1为升序-1为降序,如 sort({key:1})。
4.1 备份
mongodump -h dbhost -d dbname -o dbdirectory
-h:MongDB所在服务器地址,例如:127.0.0.1,(我这里是阿里云服务器地址)
-d:需要备份的数据库实例
-o:备份的数据存放目录,系统自动在转储目录下建立一个备份的数据库名称的目录,这个目录里面存放该数据库实例的备份数据
例子1:
首先在阿里云服务器上备份mongodb的数据(将阿里云服务器的数据库数据备份成JSON文件)

例子2:
指定查询条件导出bike集合数据为CSV
mongoexport -p 27030 -u sa -p sa -d map -c bike -f id,lat,lng,created_at,source -o bike.csv --query='{"source":"ofo"}' --limit=1
# 导出集合
$ mongoexport --host 127.0.0.1 --port 27017 --username sa --password sa --authenticationDatabase game --db game --collection ap_user --type json --out ./ap_user.json
# 简化方式
$ mongoexport -d game -c tf_game -o ./tf_game.json
例子3:
#导出表
mongoexport --port 30000 --db news_novel --collection Chapter_news --out Chapter_news.json
4.2 导入
$ mongoimport --host 127.0.0.1 --port 27017 --username sa --password sa --authenticationDatabase game --db game --collection ap_user --file ./tf_game.json
# 导入表
mongoimport -h X.X.X.X:10000 -d news_novel --colleciton Chapter_news --file Chapter_news.json
4.3 恢复
mongorestore -h dbhost -d dbname -directoryperdb dbdirectory
-h:MongoDB中的所在服务器地址
-d:需要恢复的数据库实例
-directoryperdb:备份数据所在位置
例子:
解压缩(省略)然后恢复数据(前提是要在本地创建同名数据库)

4.4 超大规模数据导出
有个业务需求只需迁移单个collection,但是collection的数据量达到了110G,时长太长。
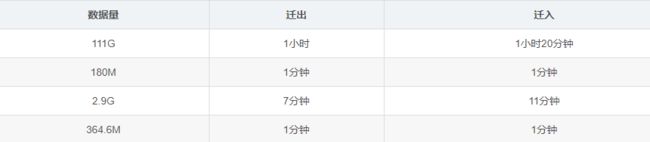
解决方案
-
- mongosync工具
使用360的这个开源工具,按道理是能解决问题,但是因为make过程中,服务器yum无注册,依赖项太多,放弃。
- mongosync工具
-
- 使用mongoexport命令的 q参数,添加了查询,分批次导入
查看了大表中的每一个document,发现没个document中存在入库时间字段,因此根据做了时间分割,写服务暂停之前,先把当日之前的数据导出,减少写服务暂停时间。
- 使用mongoexport命令的 q参数,添加了查询,分批次导入
mongoexport --port 30000 --db recom --collection news4recom --query ' {dateTs:{$gt:1519747200000}}' --out /mnt/mongo/news4recom.json
dateTs:入库时间字段
mongoexport导出的表无索引
发现直接导表未将索引导出,需要在新表中重建索引。
延伸一:内存问题
爬虫时,如果不使用pymongo的close方法,python xxx.py内存会一点一点的上涨,最开始900多M,慢慢的就1个多G,快到2G了。但是速度快,在tail -f log的时候,基本看不清输出信息。
如果使用了close方法,内存稳定在500M左右,但是读和取数据库速度慢,在tail log的时候,能看到正在保存哪个URL,正在获取哪个URL。
#-*-coding:utf-8-*-
import logging
import setting
import time,datetime
from setting import mongo_host,mongo_port,mongo_db_name_data,mongo_db_name_linkbase,mongo_db_name_task
import pymongo
logging.basicConfig(filename='log',level=logging.INFO)
class Connect_mongo(object):
def __init__(self):
self.mongo_host = mongo_host
self.mongo_port = mongo_port
self.conn()
def conn(self):
self.client = pymongo.MongoClient(host=self.mongo_host,port=self.mongo_port)
self.db_data = self.client[mongo_db_name_data]
self.db_linkbase = self.client[mongo_db_name_linkbase]
self.db_linkbase_collection = self.db_linkbase.linkbase
self.db_task = self.client[mongo_db_name_task]
def insert_db(self,item):
setting.my_logger.info('当前插入数据库的最终数据为%s'%item)
self.db_data.xxx_data.update({"car_id":item['car_id']},item,True)
self.client.close()
def save_linkbase(self,response_result,spider_name,hash_url,item_type):
if item_type == 'carinfo_item':
linkinfo = {}
linkinfo['status'] = response_result.status_code
linkinfo['url'] = response_result.url
linkinfo['spider_name'] = spider_name
linkinfo['hash_url'] = hash_url
#保存到linkbase
self.db_linkbase_collection.update({"status":linkinfo['status'],"hash_url":hash_url},linkinfo,True)
self.client.close()
else:
self.db_linkbase_collection.create_index([("over_time", pymongo.ASCENDING)], expireAfterSeconds=7200)
linkinfo = {}
linkinfo['status'] = response_result.status_code
linkinfo['url'] = response_result.url
linkinfo['spider_name'] = spider_name
linkinfo['hash_url'] = hash_url
linkinfo['over_time'] = datetime.datetime.utcnow()
#保存到linkbase
self.db_linkbase_collection.update({"status":linkinfo['status'],"hash_url":hash_url},linkinfo,True)
self.client.close()
def save_task(self,task):
setting.my_logger.info('当前插入数据库的task信息为%s'%task)
self.db_task.xxx_task.update({'url':task['url']},task,True)
self.client.close()
def get_task(self,max_requests=10):
task = []
for i in range(max_requests):
result = self.db_task.xxx_task.find_one_and_delete({})
task.append(result)
return task
def duplicate_removal(self,hash_data):
result = self.db_linkbase.linkbase.find_one({'hash_url':hash_data})
if result == None:
return True
else:
return False
mongo_insert = Connect_mongo()
一些大神回复:
内存占用跟你取出来的数据是如何缓存,以及你是否释放了内存有关。
举个例子,一次性取出5万条记录,然后存在一个list中,如果取多了,不停往list中添加,内存占用自然就大了,因为本身内存中存的数据就这么大,你都要用到,这是没办法解决的问题。除非你扩内存条。
而如果是另一种情况,你每次都实例化一个MongoClient,查询出来的task没有删掉,就会导致无用的result还缓存着数据,没有被回收,导致内存成倍增长。此时,只要在你不用这些数据的时候del
task一下就OK了。 你如何使用的,如何导致内存增长的得自己看。
连接资源一定要及时释放(不然长时间运行会出大问题的比如可能会出现大量的closed_wait连接),
思考的方向是如何避免频繁的建立连接,使用连接池会是个不错的选择,pymongo 应该是有连接池的支持的
延伸二:一开始占用内存到80%,后来一直上升,95%,再后来就OOM了
https://www.ipcpu.com/2017/01/mongodb-oom/
延伸三:BulkWriteError: batch op errors occurred
在mongodb进行数据库操作的时候触发异常
pymongo Error: pymongo.errors.BulkWriteError: batch op errors occurred
这种问题出现在调用insert_many方法,原因可能有两种:
1. 数据库某个字段被设置成了unique,在插入的时候这个字段出现了重复;
2. insert_many使用时所插入的文档列表中存在指向同一个对象的多个元素,这个本质上跟第一种情况是一样的,因为每个元素被插入之后都会被添加了一个_id字段,而相同的指向相当于同一个_id被插入了两次,就会出现上述的问题。
解决办法是对这些unique字段预先进行判断,这是pymongo与mongoengine的区别,mongoengine是在建模的时候就会设置好,但pymongo除非报错,否则很难知道这个问题。
参考:pymongo.errors.BulkWriteError错误排解
参考文献
Introduction to MongoDB
PyMongo是MongoDB数据库的python模板
mongodb数据库备份与恢复(数据库数据迁移)
MongoDB数据迁移
MongoDb数据迁移(一)
PyMongo初级使用教程
python使用pymongo访问MongoDB的基本操作,以及CSV文件导出
MongoDB - 查询