快速入门Flink (4) —— Flink的DataSource和DataSink,你都掌握了吗?
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
相信经过前面几篇 Flink 文章的学习,大家对于Flink的代码书写一定非常期待。本篇博客,我们就来扒一扒关于Flink的DataSet API的开发。
文章目录
- 1、DataSet API 开发
- 1.1 入门案例
- 1.1.1 Flink 批处理程序的一般流程
- 1.1.2 示例
- 1.1.3 步骤
- 1.1.4 实现
- 1.1.5 参考代码
- 1.1.6 将程序打包,提交到yarn
- 1.2 输入数据集 Data Sources
- 1.2.1 基于本地集合的 source(Collection-based-source)
- 1.2.2 基于文件的 source(File-based-source)
- 1.2.2.1 读取本地文件
- 1.2.2.2 读取 HDFS 数据
- 1.2.2.2 读取 CSV 数据
- 1.2.2.4 读取压缩文件
- 1.2.2.5 基于文件的 source(遍历目录)
- 1.3 数据输出 Data Sinks
- 1.3.1 基于本地集合的 sink(Collection-based-sink)
- 1.3.2 基于文件的 sink(File-based-sink)
- 1.3.1 将数据写入本地文件
- 1.3.2 将数据写入 HDFS
- 小结
1、DataSet API 开发
1.1 入门案例
1.1.1 Flink 批处理程序的一般流程
- 获取 Flink 批处理执行环境
- 构建 source
- 数据处理
- 构建 sink
1.1.2 示例
编写 Flink 程序,用来统计单词的数量。
1.1.3 步骤
- IDEA 创建项目
- 导入 Flink 所需的 Maven 依赖
- 创建 scala 单例对象,添加 main 方法
- 获取 Flink 批处理运行环境
- 构建一个 collection 源
- 使用 flink 操作进行单词统计
- 打印
1.1.4 实现
- 在 IDEA 中创建 flink-base 项目
- 导入 Flink Maven 依赖
- 分别在 main 和 test 目录创建 scala 文件夹
- 添加 main 方法
- 获取批处理运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
- 构建一个 collection 源
val wordDataSet = env.fromCollection {
List("hadoop hive spark", "flink mapreduce hadoop hive", "flume spark spark hive")
}
- 导入 Flink 隐式参数
import org.apache.flink.api.scala._
- 使用 flatMap 操作将字符串进行切割后扁平化
val words: DataSet[String] = wordDataSet.flatMap(_.split(" "))
- 使用 map 操作将单词转换为,(单词,数量)的元组
val wordNumDataSet: DataSet[(String, Int)] = words.map(_ -> 1)
- 使用 groupBy 操作按照第一个字段进行分组
val wordGroupDataSet: GroupedDataSet[(String, Int)] = wordNumDataSet.groupBy(0)
- 使用 sum 操作进行分组累加统计
val wordCountDataSet: AggregateDataSet[(String, Int)] = wordGroupDataSet.sum(1)
- 打印
wordCountDataSet.print()
- 运行测试
1.1.5 参考代码
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/*
* @Author: Alice菌
* @Date: 2020/7/20 15:55
* @Description:
编写Flink程序,统计单词
*/
object BatchWordCount {
def main(args: Array[String]): Unit = {
// 1、创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 2、接入数据源
val testDataSet: DataSet[String] = env.fromCollection(List("hadoop spark hive","hadoop hadoop spark"))
// 3、进行数据处理
// 切分
val wordDataSet: DataSet[String] = testDataSet.flatMap(_.split(" "))
// 每个单词标记1
val wordAndOneDataSet: DataSet[(String, Int)] = wordDataSet.map((_,1))
// 按照单词进行分组
val groupDataSet: GroupedDataSet[(String, Int)] = wordAndOneDataSet.groupBy(0)
// 对单词进行聚合
val sumDataSet: AggregateDataSet[(String, Int)] = groupDataSet.sum(1)
// 4、数据保存或输出
sumDataSet.writeAsText("./ResultData/BatchWordCount")
//sumDataSet.print()
env.execute("BatchWordCount")
}
}
执行完上面的代码,我们会在指定的输出路径下,看到一共生成了12个文件,其中有的是空文件,有的则保存着对应的结果数据。为什么是12个,而不是其他个数?其实这个跟电脑配置的核数相关。默认电脑是几核,就会有多少个线程参与工作。
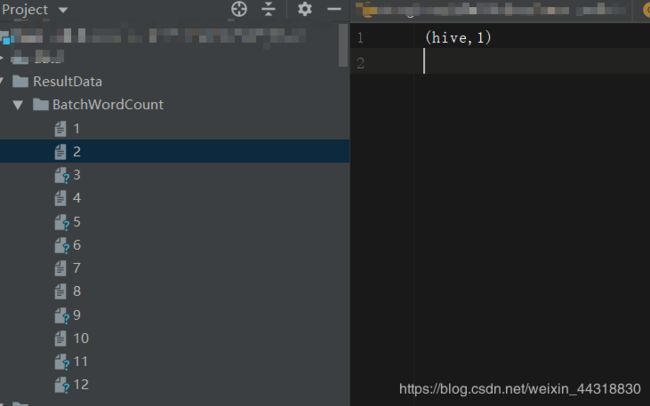
关于Execute更多的知识,博主在借鉴了其他大大之后,得到了如下经验。

特别注意:
1、execute方法调用会因为应用的类型有所不同,DataStream流式应用需要显示指定execute()方法运行程序,如果不调用则Flink流式程序不会执行。
2、对于DataSet API输出算子中已经包含了对execute()方法的调用,不需要显式调用execute()方法,否则程序会出异常。
对于不相信第二点的朋友,可以把上面代码示例中的sumDataSet.print()代码注释解开来试试~
1.1.6 将程序打包,提交到yarn
添加 maven 打包插件
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>2.5.1version>
<configuration>
<source>${maven.compiler.source}source>
<target>${maven.compiler.target}target>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.18.1version>
<configuration>
<useFile>falseuseFile>
<disableXmlReport>truedisableXmlReport>
<includes>
<include>**/*Test.*include>
<include>**/*Suite.*include>
includes>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.czxy.batch.Test01.wordCount.StreamWorldCountmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
需要注意,需要把这里的路径,更改成自己的类文件路径

上传 jar 包到服务器上,然后执行程序:
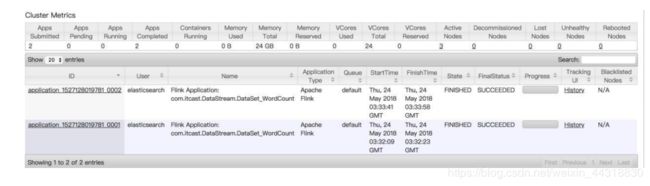
bin/flink run -m yarn-cluster -yn 2 /export/servers/flink-1.7.2/jar/day01-1.0-SNAPSHOT.jar cn.czxy.batch.BatchWordCount
在 yarn 的 8088 页面可以观察到提交的程序:
1.2 输入数据集 Data Sources
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源。
Flink作为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。 flink 在批处理中常见的 source 主要有两大类。
- 基于本地集合的 source(Collection-based-source)
- 基于文件的 source(File-based-source)
1.2.1 基于本地集合的 source(Collection-based-source)
在 flink 最常见的创建 DataSet 方式有三种。
1) 使用 env.fromElements(),这种方式也支持 Tuple,自定义对象等复合形式。
2) 使用 env.fromCollection(),这种方式支持多种 Collection 的具体类型
3) 使用 env.generateSequence() 方法创建基于 Sequence 的 DataSet

下面展示的代码,一共用到了17种方式,其中就包括上述的3种。感兴趣的朋友们可以借鉴一下代码写法。
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import scala.collection.mutable
/**
* 读取集合中的批次数据
*/
object BatchFromCollectionDemo {
def main(args: Array[String]): Unit = {
// 获取 flink 执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 导入隐式转换
import org.apache.flink.api.scala._
// 0. 用 element 创建DataSet(fromElements)
val ds0: DataSet[String] = env.fromElements("spark","flink")
ds0.print()
// 1. 用 Tuple 创建DataSet(fromElements)
val ds1: DataSet[(Int, String)] = env.fromElements((1,"spark"),(2,"flink"))
ds1.print()
// 2. 用 Array 创建DataSet
val ds2: DataSet[String] = env.fromCollection(Array("spark","flink"))
ds2.print()
// 3. 用 ArrayBuffer 创建DataSet
val ds3: DataSet[String] = env.fromCollection(ArrayBuffer("spark","flink"))
ds3.print()
// 4. 用 List 创建DataSet
val ds4: DataSet[String] = env.fromCollection(List("spark","flink"))
ds4.print()
// 5. 用 ListBuffer 创建DataSet
val ds5: DataSet[String] = env.fromCollection(ListBuffer("spark","flink"))
ds5.print()
// 6. 用 Vector 创建 DataSet
val ds6: DataSet[String] = env.fromCollection(Vector("spark","flink"))
ds6.print()
// 7. 用 Queue 创建DataSet
val ds7: DataSet[String] = env.fromCollection(mutable.Queue("spark","flink"))
ds7.print()
// 8. 用 Stack 创建DataSet
val ds8: DataSet[String] = env.fromCollection(mutable.Stack("spark","flink"))
ds8.print()
// 9. 用 Stream 创建 DataSet (Stream相当于 lazy List,避免在中间过程中生成不必要的集合)
val ds9: DataSet[String] = env.fromCollection(Stream("spark","flink"))
ds9.print()
// 10. 用 Seq 创建 DataSet
val ds10: DataSet[String] = env.fromCollection(Seq("spark","flink"))
ds10.print()
// 11. 用 Set 创建 DataSet
val ds11: DataSet[String] = env.fromCollection(Set("spark","flink"))
ds11.print()
// 12. 用 Iterable创建DataSet
val ds12: DataSet[String] = env.fromCollection(Iterable("spark","flink"))
ds12.print()
// 13. 用 ArraySeq 创建 DataSet
val ds13: DataSet[String] = env.fromCollection(mutable.ArraySeq("spark","flink"))
ds13.print()
// 14. 用 ArrayStack 创建 DataSet
val ds14: DataSet[String] = env.fromCollection(mutable.ArrayStack("spark","flink"))
ds14.print()
// 15. 用 Map 创建 DataSet
val ds15: DataSet[(Int, String)] = env.fromCollection(Map(1 -> "spark",2 -> "flink"))
ds15.print()
// 16. 用 Range 创建 DataSet
val ds16: DataSet[Int] = env.fromCollection(Range(1,9))
ds16.print()
// 17. 用 FromElements 创建 DataSet
val ds17: DataSet[Long] = env.generateSequence(1,9)
ds17.print()
}
}
1.2.2 基于文件的 source(File-based-source)
Flink基于文件的source主要有下列几种方法。
- 读取本地文件
- 读取HDFS数据
- 读取CSV数据
- 还包括一些特殊的文件格式,例如读取压缩文件数据,或者基于文件的 source (遍历目录)
针对上述陈述的几种方式,下面将一一展示代码的书写。
1.2.2.1 读取本地文件
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
//从本地文件构建数据集
object BatchFromLocalFileSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从本地文件构建数据集
val localFileSource: DataSet[String] = env.readTextFile("day02/data/input/wordcount.txt")
//3.打印输出
localFileSource.print()
}
}
1.2.2.2 读取 HDFS 数据
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object BatchFromHDFSFileSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从HDFS文件构建数据集
val hdfsFileSource: DataSet[String] = env.readTextFile("hdfs://node01:8020/test/input/wordcount.txt")
//3.输出打印
hdfsFileSource.print()
}
}
1.2.2.2 读取 CSV 数据
import org.apache.flink.api.scala.ExecutionEnvironment
object BatchFromCSVFileSource {
// 定义一个样例类,用于封装数据
case class Subject(id:Int,name:String)
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从csv文件构建数据集
import org.apache.flink.api.scala._
val csvDataSet: DataSet[Subject] = env.readCsvFile[Subject]("day02/data/input/subject.csv")
//3.输出打印
csvDataSet.print()
}
}
1.2.2.4 读取压缩文件
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object BatchFromCompressFileSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从压缩文件中构建数据集
val compressFileSource: DataSet[String] = env.readTextFile("data/input/wordcount.txt.gz")
//3.输出打印
compressFileSource.print()
}
}
1.2.2.5 基于文件的 source(遍历目录)
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.configuration.Configuration
object BatchFromFolderSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.如果需要读取包含指定目录下的子目录里的文件内容,则必须开启recursive.file.enumeration
val configuration: Configuration = new Configuration()
configuration.setBoolean("recursive.file.enumeration", true)
//3.根据遍历多级目录来构建数据集
val result: DataSet[String] = env.readTextFile("day02/data/input/a").withParameters(configuration)
result.print()
}
}
1.3 数据输出 Data Sinks
既然上边都谈到了Flink的输入,那怎么能没有输出呢~Flink 在批处理中常见的 输出 sink 有以下两种。
- 基于本地集合的 sink(Collection-based-sink)
- 基于文件的 sink(File-based-sink)
1.3.1 基于本地集合的 sink(Collection-based-sink)
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/*
* @Author: Alice菌
* @Date: 2020/7/9 15:15
* @Description:
*/
object BatchSinkCollection {
def main(args: Array[String]): Unit = {
// 1、 创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 2、 构建数据集
val source: DataSet[(Int, String, Double)] = env.fromElements((19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8))
// 3、 数据打印
source.print()
//(19,zhangsan,178.8)
//(17,lisi,168.8)
//(18,wangwu,184.8)
//(21,zhaoliu,164.8)
println(source.collect())
//Buffer((19,zhangsan,178.8), (17,lisi,168.8), (18,wangwu,184.8), (21,zhaoliu,164.8))
source.printToErr()
//(19,zhangsan,178.8)
//(17,lisi,168.8)
//(18,wangwu,184.8)
//(21,zhaoliu,164.8)
}
}
1.3.2 基于文件的 sink(File-based-sink)
flink 支持多种存储设备上的文件,包括本地文件,hdfs 文件等。
flink 支持多种文件的存储格式,包括 text 文件,CSV 文件等。
其中需要用到一个方法,writeAsText():TextOuputFormat - 将元素作为字符串写入行。字符串是通过调用每个元 素的 toString()方法获得的。
1.3.1 将数据写入本地文件
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.api.scala._
/*
* @Author: Alice菌
* @Date: 2020/7/9 16:09
* @Description:
*/
// 基于文件的sink
object BatchSinkFile {
def main(args: Array[String]): Unit = {
// 1、 创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 2、 构建数据集
val source: DataSet[(Int, String, Double)] = env.fromElements(
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
)
// 保存到本地文件(这里设置了数据覆写并指定了分区数为1)
source.writeAsText("hdfs://node01:8020/test/output/sinkHDFSFile0708",WriteMode.OVERWRITE).setParallelism(1)
env.execute(this.getClass.getSimpleName)
}
}
1.3.2 将数据写入 HDFS
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.api.scala._
/*
* @Author: Alice菌
* @Date: 2020/7/25 23:49
* @Description:
*/
object BatchSinkHDFSFile {
def main(args: Array[String]): Unit = {
// 1、 创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 2、 构建数据集
val source: DataSet[(Int, String, Double)] = env.fromElements(
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
)
// 保存到本地文件(这里设置了数据覆写并指定了分区数为1)
source.writeAsText("hdfs://node01:8020/test/output/sinkHDFSFile0708",WriteMode.OVERWRITE).setParallelism(1)
env.execute(this.getClass.getSimpleName)
}
}
小结
本篇博客博主先为大家介绍了Flink批处理的一般流程,然后为大家详细介绍了Flink的数据输入DataSource和输出DataSink的多种方式。因为所涉及到的种类比较多,希望大家好好巩固,勤加练习。下一篇博客,我们将学习Flink中的 Transformation 转换算子,敬请期待|ू・ω・` )
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
