阿里巴巴的 Kubernetes 应用管理实践经验与教训

作者 | 孙健波(天元) 阿里巴巴技术专家
导读:本文整理自孙健波在 ArchSummit 大会 2019 北京站演讲稿记录。首先介绍了阿里巴巴基于 Kubernetes 项目进行大规模应用实践过程中遇到的问题;随后会逐一介绍解决这些问题的现有实践及其本身存在的局限性;最后会介绍阿里巴巴目前正在进行的尝试和社区在这一领域的发展方向。
如今,阿里巴巴内部维护了数十个大规模的 K8s 集群,其中最大的集群约 1 万个节点,每个集群会服务上万个应用;在阿里云的 Kubernetes 服务 ACK 上,我们还维护了上万个用户的 K8s 集群。我们在一定程度上解决了规模和稳定性问题之后,发现其实在 K8s 上管理应用还有很大的挑战等着我们。
应用管理的两大难题
今天我们主要讨论这两个方面的挑战:
- 对应用研发而言,K8s API 针对简单应用过于复杂,针对复杂应用难以上手;
- 对应用运维而言,K8s 的扩展能力难以管理;K8s 原生的 API 没有对云资源全部涵盖。
总体而言,我们面临的挑战就是:如何基于 K8s 提供真正意义上的应用管理平台,让研发和运维只需关注到应用本身。
研发对应用管理的诉求
K8s all in one 的 YAML 文件
让我们来看一下这样一个 K8s 的 yaml 文件,这个 yaml 文件已经是被简化过的,但是我们可以看到它仍然还是比较长。

面对这样一个广受“复杂”诟病的 YAML 文件,我相信大家都会忍不住想该怎么简化。
自上而下,我们大致把它们分为三块:
- 一块是扩缩容、滚动升级相关的参数,这一块应该是应用运维的同学比较关心的;
- 然后中间一块是镜像、端口、启动参数相关的,这一块应该是开发的同学比较关心的;
- 最后一块大家可能根本看不懂,通常情况下也不太需要明白,可以把它们理解为 K8s 平台层的同学需要关心的。
看到这样一个 yaml 文件,我们很容易想到,只要把里面的字段封装一下,把该暴露的暴露出来就好了。确实,我们内部就有 PaaS 平台这么做。
只透出部分字段:简单却能力不足
内部的某个 PaaS 平台精心挑选了部分字段,并做了一个漂亮的前端界面给用户,只透出给用户 5 个左右的字段,大大降低了用户理解 K8s 的心智负担。然后底层实现用类似模板的方式把用户这五个字段渲染出来一个完整的 yaml 文件。突出的字段大概如下图所示:

不得不说这种方式是非常有效的,针对简单无状态的应用,精简 API 可以大大降低 K8s 的门槛,快速并且高效的对接用户,PaaS 平台也顺利让大家使用了起来。同时,我也从一些技术分享中了解到许多其他公司也是用这种类似的方式简化的 K8s API。
但是当用户的业务开始大规模对接以后,我们就会自然而然遇到有状态的复杂应用,用户就会开始抱怨 PaaS 平台能力不够了。比如我们的 Zookeeper 多实例选主、主从切换这些逻辑,在这五个字段里就很难展开了。
归根结底就是屏蔽大量字段的方式会限制基础设施本身的能力演进,但是 K8s 的能力是非常强大而灵活的。我们不可能为了简化而放弃掉 K8s 强大的能力。
就比如当前这个例子,我们很容易想到,针对复杂有状态的应用,应该通过 K8s 里面的 CRD 和 Operator 来解决。
、
CRD Operator: K8s 扩展能力强大却难以上手
确实,我们内部对接复杂应用云原生化的时候,也推荐他们编写 Operator,但是经常出现这样一段对话。
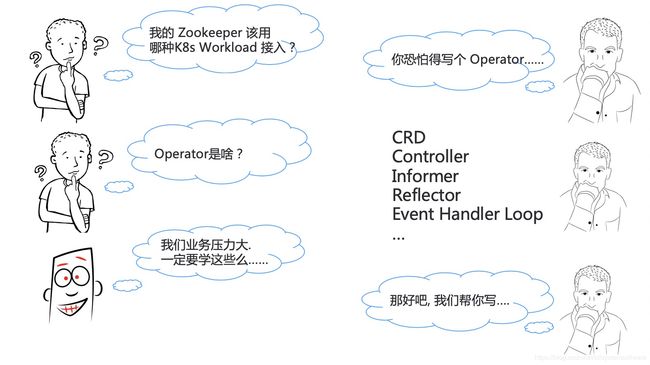
中间件的工程师跟我们说,我这有个 Zookeeper 该用哪种 K8s 的 Workload 接入啊? 我们想了想,K8s 设计如此精妙,自然没有解决不了的问题,于是我们推荐他们使用 Operator。他们就懵了,说你们搞云原生的这几年造新词的能力绝对一流,之前都没听说过。
想想也是,业务方理解这些新概念不难,但是真的要自己去上手实现,还是非常困难的。我们自然也觉得业务方更应该专注于他们的业务本身,于是我们不得不帮他们一起写。
可以看到,我们亟需一个统一的模型去解决研发对应用管理的诉求。
运维对应用管理的诉求
除了研发侧的问题之外,我们在运维侧也遇到了很大的挑战。
运维能力众多却难以管理
K8s 的 CRD Operator 机制非常灵活而强大,不光是复杂应用可以通过编写 CRD Operator 实现,我们的运维能力也大量通过 Operator 来扩展,比如灰度发布、流量管理、弹性扩缩容等等。我们常常赞叹于 K8s 的灵活性,它让我们基础平台团队对外提供能力非常方便,但是对应用运维来说,他们要使用我们提供的这些运维能力,却变得有些困难。
比如我们上线了一个 CronHPA,可以定时设置在每个阶段会根据 CPU 调整实例数的范围。应用运维并不知道跟原生不带定时功能的 HPA 会产生冲突,而我们也没有一个统一的渠道帮助管理这么多种复杂的扩展能力,结果自然是引起了故障。这血的教训提醒我们要做事前检查,熟悉 K8s 的机制很容易让我们想到为每个 Operator 加上 admission webhook。
这个 admission webhook 需要拿到这个应用绑定的所有运维能力以及应用本身的运行模式,然后做统一的校验。如果这些运维能力都是一方提供的还好,如果存在两方,甚至三方提供的扩展能力,我们就没有一个统一的方式去获知了。事实上如果我们想的更远一些就会发现,我们需要一个统一的模型来协商并管理这些复杂的扩展能力。
云资源难以描述和统一交付
当我们把应用的 Operator 以及对应的运维能力都写好以后,我们很容易想到要打包交付这个应用,这样无论是公有云还是专有云都可以通过一个统一的方式去交互。社区的主流方式目前就是使用 Helm 来打包应用,而我们也采用了这样的方式给我们的用户交付,但是却发现我们的用户需求远不止于此。
云原生应用有一个很大的特点,那就是它往往会依赖云上的资源,包括数据库、网络、负载均衡、缓存等一系列资源。
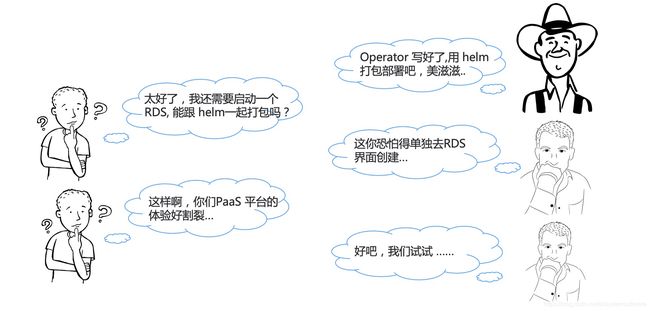
当我们使用 Helm 打包时,我们只能针对 K8s 原生 API,而如果我们还想启动 RDS 数据库,就比较困难了。如果不想去数据库的交互页面,想通过 K8s 的 API 来管理,那就又不得不去写一个 CRD 来定义了,然后通过 Operator 去调用实际云资源的 API。
这一整套交付物实际上就是一个应用的完整描述,即我们所说的“应用定义”。但事实上,我们发现“应用定义”这个东西,在整个云原生社区里其实是缺失的。这也是为什么阿里巴巴内部有很多团队开始尝试设计了自己的“定义应用”。
这种定义方式最终所有的配置还是会全部堆叠到一个文件里,这跟 K8s API all-in-one 的问题其实是一样的,甚至还更严重了。而且,这些应用定义最终也都成为了黑盒,除了对应项目本身可以使用,其他系统基本无法复用。自然就更无法使得多方协作复用了。
每个公司和团队都在自己定义应用
不光是阿里巴巴内部的团队需要应用定义,事实上几乎每个基于 K8s 管理应用的公司和团队都在自己定义应用。如下所示,我就搜到了两家公司的应用定义:

应用定义实际上是应用交付/分发不可或缺的部分。但是在具体的实践中,我们感受到这些内部的应用定义都面临着如下的问题:
- 定义是否足够开放,是否可以复用?
- 如何与开源生态协作?
- 如何迭代与演进?
这三个问题带来的挑战都是巨大的,我在上文已经提到,一个应用定义需要容易上手,但又不失灵活性,更不能是一个黑盒。应用定义同样需要跟开源生态紧密结合,没有生态的应用定义注定是没有未来的,自然也很难持续的迭代和演进。
区分使用者的分层模型与模块化的封装
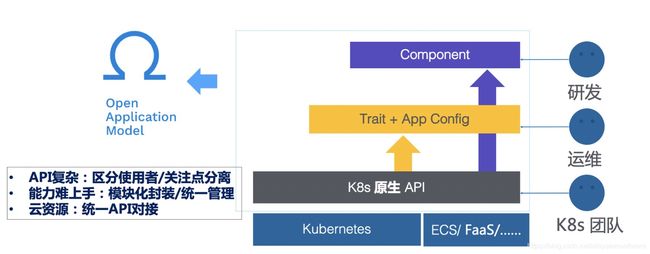
让我们回过头来重新审视我们面临的挑战,归根结底在于 K8s 的 All in One API 是为平台提供者设计的,我们不能像下图左侧显示的一样,让应用的研发、运维跟 K8s 团队一样面对这一团 API。
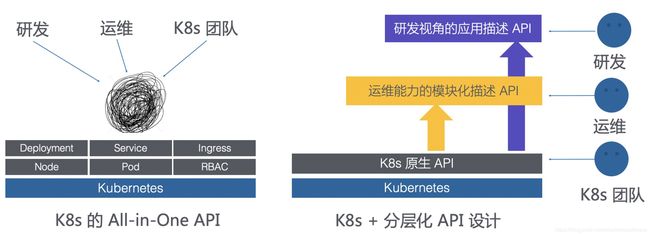
一个合理的应用模型应该具有区分使用者角色的分层结构,同时将运维能力模块化的封装。让不同的角色使用不同的 API,正如上图右侧部分。
OAM: 以应用为中心的 K8s API 分层模型
OAM(Open Application Model) 正是这样一个以应用为中心的 K8s API 分层模型:
- 从研发的角度,他操作和关注的 API 对象叫 Component;
- 从运维的角度,模块化的运维能力封装就是 Trait,而运维可以通过 App Config 将 Component 和 Trait 自由组合,最终实例化成一个运行的应用;
- K8s 团队本身则仍然基于 K8s 的原生 API 迭代这一层能力。
针对研发时常抱怨的 K8s API 太复杂,我们通过关注点分离,区分使用者面对的 API 来解决,同时提供了几种核心的 Workload,让研发只需要填写少数几个字段就可以完成组件的定义;针对复杂应用定义,我们通过扩展的 Workload,允许研发对接 CRD Operator 的方式对接自定义 Workload。
针对运维需要的模块化封装运维能力和全局管理的需求,OAM 模型通过 Trait 来提供。Trait 是运维能力的体现,不同的 Trait 也对应了不同类型的运维能力,如日志收集 Trait、负载均衡 Trait、水平扩缩容 Trait 等等;同时 OAM 本身就提供了一个全局管理的标准,OAM 模型的实现层可以轻松针对 OAM 定义里的种种 Trait 描述进行管理和检查。
针对云资源,OAM 向上也提供了统一的 API,也是通过关注点分为三类:
- 一类是研发关注的云资源,如数据库 RDS、对象存储 OSS 等,通过扩展 Workload 接入;
- 另一类是运维关注的云资源,如负载均衡 SLB 等,通过 Trait 接入;
- 最后一类也是运维关注的云资源,但是可能包含多个应用之间的联动关系,如虚拟专有网络 VPC 等,通过应用的 Scope 接入。Scope 则是 OAM 中管理多应用联动关系的概念。
可以看到,OAM 通过统一的一套标准,解决了我们今天提到的所有难题。让我们继续深入到 OAM 中看看不同的概念具体是什么。
OAM Component:研发关注的 API
Component 就是 OAM 模型提供给研发的API对象,如下所示:
apiVersion: core.oam.dev/v1alpha1
kind: Component
metadata:
name: nginx
annotations:
version: v1.0.0
description: >
Sample component schematic that describes the administrative interface for our nginx deployment.
spec:
workloadType: Server
osType: linux
containers:
- name: nginx
image:
name: nginx:1.7.9
digest:
env:
- name: initReplicas
value: 3
- name: worker_connections
fromParam: connections
workloadSettings:
...
parameters:
- name: connections
description: "The setting for worker connections"
type: number
default: 1024
required: false
可以看到 Component 本身就是一个 K8s 的CRD,spec 字段里面的部分就是 Component 具体的定义。其中第一个重要的字段就是 workloadType,这个决定了应用的运行模式。
针对简单应用,OAM 提供了 6 种核心 Workload,如下表所示:
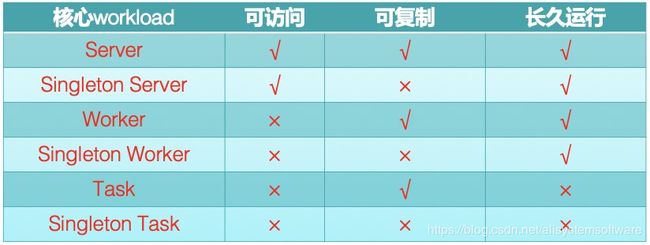
主要通过是否可访问、是否可复制、是否长久运行来区分。如 Server,就代表了大家最常用的 K8s 里面 Deployment Service 的组合。
填写了核心 workloadType 的 Component,只需要定义 Container 里的注入镜像、启动参数等字段,就如我们最开始所说的屏蔽掉大量字段的 PaaS 一样,为用户大大降低了门槛。
而针对复杂的有状态应用,OAM 则允许通过扩展 Workload 来实现,如下图所示,我们可以定义一个新的叫 openfaas 的 WorkloadType,它的定义实际上完全等价于一个 CRD 定义。
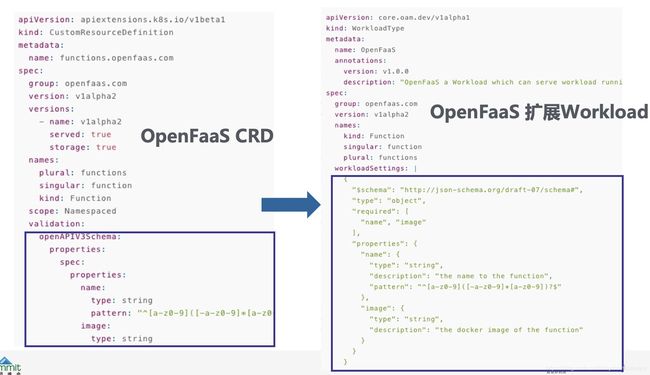
OAM 模型中,使用自定义的 Workload 也是通过 Component,只是 WorkloadType 改为你自定义的 WorkloadType 名称。
OAM Trait:可发现、可管理的运维能力
Trait 就是模块化的运维能力,我们能通过命令行工具发现一个系统里支持哪些 Traits(运维能力)。
$ kubectl get traits
NAME AGE
autoscaler 19m
ingress 19m
manual-scaler 19m
volume-mounter 19m
这时候,运维要查看具体的运维能力该怎么使用,是非常简单的:
$ kubectl get trait ingress -o yaml
apiVersion: core.oam.dev/v1alpha1
kind: Trait
metadata:
name: cron-scaler
annotations:
version: v1.0.0
description: "Allow cron scale a workloads that allow multiple replicas."
spec:
appliesTo:
- core.oam.dev/v1alpha1.Server
properties: |
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"required": [
"schedule"
],
"properties": {
"schedule": {
"type": "array",
"description": "CRON expression for a scaler",
"item": {
"type": "string"
}
},
"timezone": {
"type": "string",
"description": "Time zone for this cron scaler."
},
"resource":{
"type": "object"
"description": "Resources the cron scaler will follow",
"properties": {
"cpu": {
type: "object"
...
}
}
}
}
}
可以看到,他可以在 Trait 定义里清晰的看到这个运维能力可以作用于哪种类型的 Workload,包括能填哪些参数、哪些必填/选填、参数的作用描述是什么。 你也可以发现,OAM 体系里面,Component 和 Trait 这些 API 都是 Schema,所以它们是整个对象的字段全集,也是了解这个对象描述的能力“到底能干吗?”的最佳途径。
事实上,大家可能已经发现,Trait 的定义和 CRD 是对等的,而你完全也可以通过 Operator 实现 Trait。

所以** OAM 事实上将原本散乱的 Operator 通过不同的角色有机的管理起来了**。
OAM Application Config:组装 Component 和 Trait,应用实例化运行
Component 和 Trait 最终通过 Application Configuration 结合,并真实运行起来。
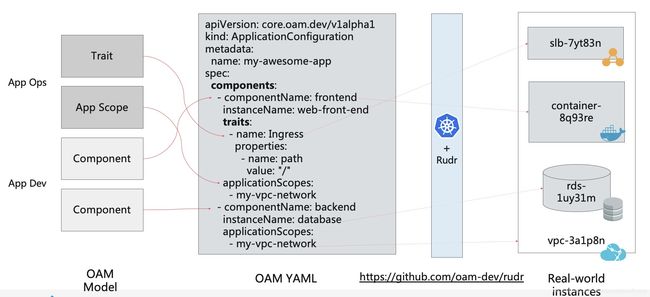
更重要的是,这个 OAM 应用描述文件是完全自包含的,也就是说通过 OAM YAML,作为软件分发商,我们就可以完整地跟踪到一个软件运行需要的所有资源和依赖。这就使得现在对于一个应用,大家只需要一份 OAM 的配置文件,就可以快速、在不同运行环境上把应用随时运行起来,把这种自包含的应用描述文件完整地交付到任何一个运行环境中。
而我们图中的 Rudr 项目就是 OAM 的一个实现,也可以理解为 OAM 的一个解释器,将 OAM 的统一描述转换为背后众多的 Operator。同时 Rudr 也是一个统一管理的媒介,如果 Application Configuration 中出现了一个 Component 绑定 2 个 Trait 并且互相冲突的情况,就可以快速被检验并发现问题,如下图所示。

同样,包括复杂应用的编排、云资源的拉起、Workload 与 Trait 交互等等,都可以在这个 OAM 解释器中实现。
大家可以通过 Rudr 项目中的教程文档体验 OAM 的这些交互过程。
OAM 加持下的 Kubernetes PaaS
事实上,OAM 加持下的 PaaS 基于 Kubernetes,将众多 Operator 分层的管理了起来。
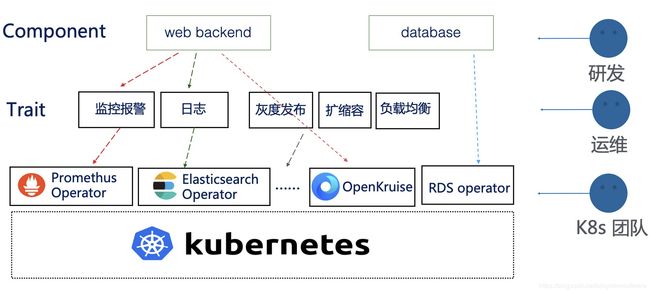
对于研发,通常他关心的应用可能是一个由 web 和数据库组合而成的应用,数据库组件的背后可能是一个 RDS Operator 实现。而 web 应用背后,则可以是我们开源的 K8s 原生 StatefulSet的增强项目 OpenKruise,OpenKruise 中提供的包括原地升级等增强能力则通过 Trait 的方式去配置。而额外的一些监控报警、日志等能力,则由一个个独立的 Operator 去实现,由运维在第二层去关注和管理。
最终 K8s 团队联合各种基础软件的提供商,围绕 K8s 原生 API,以 Operator 的形式不断提供扩展能力,通过 OAM 这样统一的规范和标准向外标准化输出。
更重要的是,OAM 的统一描述大大提高了 Operator 的复用能力,使得 Operator 的编写主需要关注业务逻辑本身。比如原先你写一个 Zookeeper Operator,你需要写实例的服务发现、需要写升级时主备切换的编排逻辑、需要写实例备份的逻辑,而这一切在 OAM 的标准化下,你将可以轻松在社区找到类似组成部分。
OAM 加持下的 Kubernetes PaaS,使得不同的 Operator 可以像乐高积木一样灵活组装,使得应用定义成为了社区共同建设的项目,使得应用管理变得统一,功能却更加强大!
最后
最后,给大家分享一下 OAM 项目近期的计划,OAM 是一个完全属于社区的应用定义模型,我们非常希望大家都能参与进来。
- 钉钉扫码进入 OAM 项目中文讨论群

- 通过 Gitter 直接参与讨论:https://gitter.im/oam-dev/
我们会集成 OpenFaaS、Terraform、Knative,支持不同的 Workload,让 OAM 可以对接不同的实现;我们会针对 K8s Operator 提供一键接入的转换方式,让现在的 Operator 快速融入OAM。
我们也会开源一个 oam-framework 项目,这个项目可以快速构建一个 OAM 的实现,类似 kubebuilder、Operator-sdk 快速构建 Operator 一样,oam-framework 会帮助你快速构建 OAM 实现。
我们还会构建一个 CRD (traits/workloads) Registry 项目,可以让大家注册自己的 OAM 实现、自定义 Workload、Trait 等等资源,以便最大程度的实现社区中大家的协作与复用。
- OAM 规范地址:https://github.com/oam-dev/spec
- OAM 开源实现地址:https://github.com/oam-dev/rudr
期待大家的参与!
关注阿里巴巴云原生公众号回复应用即可下载本文 PPT!
“> 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”