String的一些理解
进一步理解
很多想法来着:H神的博客
1 常量池与intern()

可以看到常量池中保存了 字面量和符号引用
对常量池的详细讲解参考自:Suntata博客JVM 之常量池
符号引用: 下面例子的 s1 s2 s3 引用了字面量
字面量: 下面例子的 "Str"
String s1 = "Str";
String s2 = new String("Str");
String s3 = new String("Str").intern();
System.out.println(s1 == s2); //False
System.out.println(s1 == s3); //True不是说每当我们使用new创建字符串的时候,都会到字符串池检查(查到就直接发返回,未查到就创建并返回),然后返回吗,那应该都是true才对啊?
在编译期 符号引用s1会和字面量Str一起加入Class常量池中 然后在类加载阶段会一起进入JVM的常量池.而在进入JVM常量池的时候 并不会直接把所有类中定义的常量全部都加载进来,而是会做个比较,如果需要加到字符串常量池中的字符串已经存在,那么就不需要再把字符串字面量加载进来了
所以 "若常量池中已经存在”Str”,则直接引用,也就是此时只会创建一个对象" 说的就是这个字符串字面量在字符串池中被创建的过程。
而在运行期,new String("Str")执行到的时候,是要在Java堆中创建一个字符串对象的,而这个对象所对应的字符串字面量是保存在字符串常量池中的。但是,String s = new String("Str"),对象的符号引用s是保存在Java虚拟机栈上的,他保存的是堆中刚刚创建出来的的字符串对象的引用。
其实很简单我们比较的s1和s2 并不是那个没有重新创建 在常量池中相同的字面量 而是在堆中创建出来的新地址 s1 s2 是两个不同的对象 肯定不相等了啊
到这里就不得不提起那个金典的面试题了,下面这行代码创建了几个对象.
String s = new String("Str");答案很简单就是如果常量池中已经有了Str 就创建一个对象 如果没有就是两个
new String() 无论如何肯定是创建了对象的
常量池中的“对象”是在编译期就确定好了的,在类被加载的时候创建的,如果类加载时,该字符串常量在常量池中已经有了,那这一步就省略了。堆中的对象是在运行期才确定的,在代码执行到new的时候创建的。
那intern()呢?
编译期生成的各种字面量和符号引用是运行时常量池中比较重要的一部分来源,但是并不是全部。那么还有一种情况,可以在运行期像运行时常量池中增加常量。那就是String的intern方法。
当一个String实例调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用;
盗图一张...下图就很清晰的说明了intern()的原理:
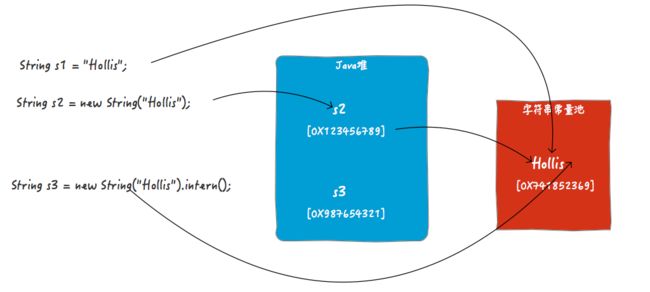
对于String s3 = new String("Hollis").intern(),在不调用intern情况,s3指向的是JVM在堆中创建的那个对象的引用的(如图中的s2)。但是当执行了intern方法时,s3将指向字符串常量池中的那个字符串常量。
由于s1和s3都是字符串常量池中的字面量的引用,所以s1==s3。但是,s2的引用是堆中的对象,所以s2!=s1。
而intern()的最主要的意义是在运行期将新创建(如拼接)的字符串加入常量池中,这样对于再次调用此字符串的情况就可以结束字符串的重复创建.
static final int MAX = 1000 * 10000;
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}在以上代码中,我们明确的知道,会有很多重复的相同的字符串产生,但是这些字符串的值都是只有在运行期才能确定的。所以,只能我们通过intern显示的将其加入常量池,这样可以减少很多字符串的重复创建。
再看几个例子:
加号拼接
String s1 = "1" + "23";
String s2 = "123";
String x = new StringBuffer().append("1").append("23").toString();
System.out.println(s1 == s2); //ture
System.out.println(x == s2); //false并不是我想象中的对于 + 拼接的处理是编程append的形式.
而是JVM编译器对字符串做了优化,在编译时s1就已经被优化成“123”,s1和s2指向字符串常量池同一个字符串常量(字面量),所以==比较为true。
new String() + new String()
String s1 = new String("1") + new String("23");
String s2 = "123";
System.out.println(s1 == s2); //false这里返回false没毛病 而加上intern()试一下
String s1 = new String("1") + new String("23");
String x = s1.intern();
String s2 = "123";
System.out.println(s1 == s2); //true
System.out.println(x == s2); //true
这里 s1 == s2 返回的是ture,为什么呢?
x == s2 是因为intern方法会判断如果常量池中没有123就将其加入并返回常量池中的地址.x == s2 没毛病
但 s1 == s2 是因为JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
所以:s1.intern 发现常量池没有123这个常量对象 就把 s1的引用放进了常量池 , 然后s2 ="123" 发现已经常量池有123的引用了,就直接把123的引用给 s2了
对于将堆中的引用加入常量池,我们还可以看一个例子:
String s1 = new String("1");
String x1 = s1.intern();
System.out.println(x1 == s1); //false
String s2 = new String("2") + new String("3");
String x2 = s2.intern();
System.out.println(x2 == s2); //true这里我们发现X2==S2是因为直接放入的是引用 引用地址和S2地址一样, X1!=S1是因为在 String s1 = new String("1") 时除了在堆中新建对象,还会在常量池新建 1 对象,X1就是常量池中的1了
让我们再看一个示例:
String s2 = "123";
String s1 = new String("1") + new String("23");
String x = s1.intern();
System.out.println(s1 == s2); //false
System.out.println(x == s2); //true这里我们先创建了s2 执行到 s2="123" 就将其加入了常量池, 所以在s1.intern的时候发现常量池中有值就直接将其返回并没有把s1加入常量池,所以s1不等于s2
IDEA 字面量进入字符串常量池的时机 参考知乎
刚刚不是说在编译期就会把字面量加入常量池吗? 要是编译期已经加入了那么上面两个例子应该结果完全一样才对啊?
刚刚说的是:常量池中的“对象”是在编译期就确定好了的,在类被加载的时候创建的.
在类加载阶段, JVM会在堆中创建 对应这些 class文件常量池中的 字符串对象实例 并在字符串常量池中驻留其引用。具体在resolve阶段执行。这些常量全局共享。
对是在resolve阶段加入的,但是并不是立即就创建对象并且在字符串常量池中驻留了引用。 JVM规范里明确指定resolve阶段可以是lazy的。
一般是在第一次引用该项的ldc指令被第一次执行到的时候才会resolve. 那什么是Idc指令呢? 简单地说,它用于将int、float或String型常量值从常量池中推送至栈顶.而刚刚说在类加载阶段,这个 resolve 阶段( constant pool resolution )是lazy的。换句话说并没有真正的对象,字符串常量池里自然也没有,那么ldc指令还怎么把人推送至栈顶?或者换一个角度想,既然resolve 阶段是lazy的,那总有一个时候它要真正的执行吧,是什么时候?
执行ldc指令就是触发这个lazy resolution动作的条件
ldc指令是否需要创建新的String实例,全看在第一次执行这一条ldc指令时,StringTable是否已经记录了一个对应内容的String的引用。
2 视图与全拷贝
在之前学习asList()方法 和 Guava的不可变类的时候曾经觉得JDK的视图类的方法是一种非常好的处理方法
性能好,直接给数组赋值 数据还是原来数组的元素,并不是逐一拷贝。当然是直接赋值快了。
共享内部数组节约内存 还是使用的原理的数据
而在Java 7 之有很多String里面的方法都使用这种“性能好的、节约内存的”的方法。比如:substring、replace、concat、valueOf等方法
但是在Java 7中,substring已经不再使用这种“优秀”的方法了,为什么呢? 虽然这种方法有很多优点,但是他有一个致命的缺点,对于sun公司的程序员来说是一个零容忍的bug,那就是他很有可能造成内存泄露。 看一个例子,假设一个方法从某个地方(文件、数据库或网络)取得了一个很长的字符串,然后对其进行解析并提取其中的一小段内容,这种情况经常发生在网页抓取或进行日志分析的时候。下面是示例代码。
String aLongString = "...a very long string...";
String aPart = data.substring(20, 40);
return aPart;
在这里aLongString只是临时的,真正有用的是aPart,其长度只有20个字符,但是它的内部数组却是从aLongString那里共享的,因此虽然aLongString本身可以被回收,但它的内部数组却不能(如下图)。这就导致了内存泄漏。如果一个程序中这种情况经常发生有可能会导致严重的后果,如内存溢出,或性能下降。
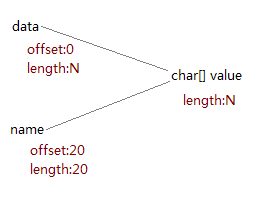
新的实现虽然损失了性能,而且浪费了一些存储空间,但却保证了字符串的内部数组可以和字符串对象一起被回收,从而防止发生内存泄漏,因此新的substring比原来的更健壮。
上图是JDK7中的实现方式,源码如下:
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}虽然substring方法已经为了其鲁棒性放弃使用这种share数组的方法,但是这种share数组的方法还是有一些其他方法在使用的,这是为什么呢?首先呢,这种方式构造对应有很多好处,其次呢,其他的方法不会将数组长度变短,也就不会有前面说的那种内存泄露的情况(内存泄露是指不用的内存没有办法被释放,比如说concat方法和replace方法,他们不会导致元数组中有大量空间不被使用,因为他们一个是拼接字符串,一个是替换字符串内容,不会将字符数组的长度变得很短!)
再来看一下Jdk6的实现就很清楚了
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
3 不可变性
如果字符串可变的话,当两个引用指向指向同一个字符串时,对其中一个做修改就会影响另外一个。
特别要注意的是,String类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。
缓存Hashcode
Java中经常会用到字符串的哈希码(hashcode)。例如,在HashMap中,字符串的不可变能保证其hashcode永远保持一致,这样就可以避免一些不必要的麻烦。这也就意味着每次在使用一个字符串的hashcode的时候不用重新计算一次,这样更加高效。
在String类中,有以下代码:
private int hash;//this is used to cache hash code.以上代码中
hash变量中就保存了一个String对象的hashcode,因为String类不可变,所以一旦对象被创建,该hash值也无法改变。所以,每次想要使用该对象的hashcode的时候,直接返回即可。
安全性
String被广泛的使用在其他Java类中充当参数。比如网络连接、打开文件等操作。如果字符串可变,那么类似操作可能导致安全问题。因为某个方法在调用连接操作的时候,他认为会连接到某台机器,但是实际上并没有(其他引用同一String对象的值修改会导致该连接中的字符串内容被修改)。可变的字符串也可能导致反射的安全问题,因为他的参数也是字符串。
代码示例:
boolean connect(string s){
if (!isSecure(s)) {
throw new SecurityException();
}
//如果s在该操作之前被其他的引用所改变,那么就可能导致问题。
causeProblem(s);
}线程安全
因为不可变对象不能被改变,所以他们可以自由地在多个线程之间共享。不需要任何同步处理。
4 equals() & hashcode()
所有Java类的父类——java.lang.Object中定义了两个重要的方法
public boolean equals(Object obj)
public int hashCode()我们都知道重写其中之一的时候必须重写另一个 那是为什么呢?
只重写equals方法
import java.util.HashMap;
public class Apple {
private String color;
public Apple(String color) {
this.color = color;
}
public boolean equals(Object obj) {
if(obj==null) return false;
if (!(obj instanceof Apple))
return false;
if (obj == this)
return true;
return this.color.equals(((Apple) obj).color);
}
public static void main(String[] args) {
Apple a1 = new Apple("green");
Apple a2 = new Apple("red");
//hashMap stores apple type and its quantity
HashMap m = new HashMap();
m.put(a1, 10);
m.put(a2, 20);
System.out.println(m.get(new Apple("green"))); //null
}
} 上面的代码执行过程中,先是创建个两个Apple,一个green apple和一个red apple,然后将这来两个apple存储在map中,存储之后再试图通过map的get方法获取到其中green apple的实例。数据结果为null。也就是说刚刚通过put方法放到map中的green apple并没有通过get方法获取到。你可能怀疑是不是green apple并没有被成功的保存到map中,但是,通过debug工具可以看到,它已经被保存成功了。
没有重写hashcode()的原因
造成以上问题的原因其实比较简单,是因为代码中并没有重写hashcode方法。hashcode和equals的约定关系如下:
1、如果两个对象相等,那么他们一定有相同的哈希值(hash code)。
2、如果两个对象的哈希值相等,那么这两个对象有可能相等也有可能不相等。(需要再通过equals来判断)
在Map中,首先使用key的哈希码定位数组中位置。之后通过使用equals方法进行线性搜索的方式来查找对象。
其实,一个哈希码可以映射到一个桶(bucket)中,hashcode的作用就是先确定对象是属于哪个桶的。如果多个对象有相同的哈希值,那么他们可以放在同一个桶中。如果有不同的哈希值,则需要放在不同的桶中。至于同一个桶中的各个对象之前如何区分就需要使用equals方法了。
hashcode方法的默认实现会为每个对象返回一个不同的int类型的值。所以,上面的代码中,第二个apple被创建出来时他将具有不同的哈希值。可以通过重写hashCode方法来解决。
public int hashCode(){
return this.color.hashCode();
}在判断两个对象是否相等时,不要只使用equals方法判断。还要考虑其哈希码是否相等。尤其是和hashMap等与hash相关的数据结构一起使用时。