#{tweet.text}
Node.js简单介绍并实现一个简单的Web MVC框架
Node.js是什么
Node让你可以用javascript编写服务器端程序,让javascript脱离web浏览器的限制,像C#、JAVA、Python等语言 一样在服务器端运行,这也让一些熟悉Javascript的前端开发人员进军到服务器端开发提供了一个便利的途径。 Node是基于Google的V8引擎封装的,并提供了一些编写服务器程序的常用接口,例如文件流的处理。Node的目的是提供一种简单的途径来编写高性 能的网络程序。
(注:1、本文基于Node.js V0.3.6; 2、本文假设你了解JavaScript; 3、本文假设你了解MVC框架;4、本文示例源代码:learnNode.zip)
Node.js的性能
hello world 测试: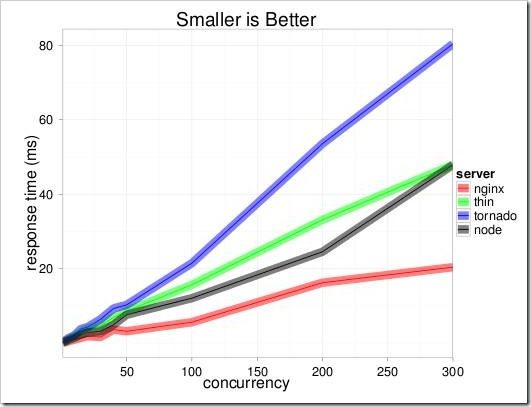
300并发请求,返回不同大小的内容:
为什么node有如此高的性能?看node的特性。
Node.js的特性
1. 单线程
2. 非阻塞IO
3. Google V8
4. 事件驱动
更详细的了解node请看淘宝UED博客上的关于node.js的一个幻灯片:http://www.slideshare.net/lijing00333/node-js
你好,世界
这,当然是俗套的Hello World啦(hello_world.js):
var http = require('http'); http.createServer(function (req, res) { res.writeHead(200, {'Content-Type': 'text/plain'}); res.end('Hello World\n'); }).listen(8124, "127.0.0.1"); console.log('Server running at http://127.0.0.1:8124/');
require类似于C#的using、Python的import,用于导入模块(module)。node使用的是CommonJS的模块系 统。http.createServer 的参数为一个函数,每当有新的请求进来的时候,就会触发这个函数。最后就是绑定要监听的端口。
怎么运行?
当然,是先安装node.js啦。到http://nodejs.org/下载并编译,支持Linux、Mac,也支持windows下的Cygwin。具体的安装说明见:http://howtonode.org/how-to-install-nodejs 装好node后,就可以运行我们的hello world了:
$ node hello_world.js
Server running at http://127.0.0.1:8124/

编程习惯的改变?
我们来写一个读取文件内容的脚本:
//output_me.js var fs = require('fs'), fileContent = 'nothing'; fs.readFile(__filename, "utf-8", function(err, file) { if(err) { console.log(err); return; } fileContent = file; console.log('end readfile \n'); }); console.log('doSomethingWithFile: '+ fileContent +'\n');
这个脚本读取当前文件的内容并输出。__filename是node的一个全局变量,值为当前文件的绝对路径。我们执行这个脚本看一下: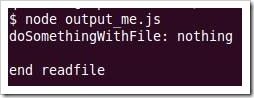
有没发现结果不对呢?打印的fileContent并不是读取到的文件内容,而是初始化的时候赋值的nothing,并且‘end readfile’最后才打印出来。前面我们提到node的一个特性就是非阻塞IO,而readFile就是异步非阻塞读取文件内容的,所以后面的代码并 不会等到文件内容读取完了再执行。请谨记node的异步非阻塞IO特性。所以我们需要将上面的代码修改为如下就能正常工作了:
//output_me.js var fs = require('fs'), fileContent = 'nothing'; fs.readFile(__filename, "utf-8", function(err, file) { if(err) { console.log(err); return; } fileContent = file; //对于file的处理放到回调函数这里处理 console.log('doSomethingWithFile: '+ fileContent +'\n'); }); console.log('我们先去喝杯茶\n');
写个Web MVC框架试试
下面我们用node来写一个小玩具:一个Web MVC框架。这个小玩具我称它为n2Mvc,它的代码结构看起来大概如下: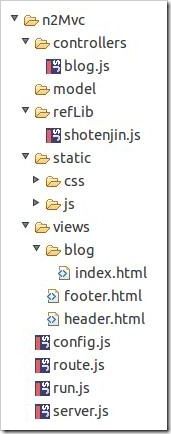
和hello world一样,我们需要一个http的服务器来处理所有进来的请求:
var http = require('http'), querystring = require("querystring"); exports.runServer = function(port){ port = port || 8080; var server = http.createServer(function(req, res){ var _postData = ''; //on用于添加一个监听函数到一个特定的事件 req.on('data', function(chunk) { _postData += chunk; }) .on('end', function() { req.post = querystring.parse(_postData); handlerRequest(req, res); }); }).listen(port); console.log('Server running at http://127.0.0.1:'+ port +'/'); };
这里定义了一个runServer的方法来启动我们的n2Mvc的服务器。有没注意到runServer前面有个exports?这个 exports相当于C#中的publish,在用require导入这个模块的时候,runServer可以被访问到。我们写一个脚本来演示下node 的模块导入系统:
//moduleExample.js var myPrivate = '艳照,藏着'; exports.myPublish = '冠西的相机'; this.myPublish2 = 'this也可以哦'; console.log('moduleExample.js loaded \n');
执行结果:
从结果中我们可以看出exports和this下的变量在外部导入模块后,可以被外部访问到,而var定义的变量只能在脚本内部访问。 从结果我们还可以看出,第二次require导入moduleExample模块的时候,并没有打印“moduleExample.js loaded”,因为require导入模块的时候,会先从require.cache 中检查模块是否已经加载,如果没有加载,才会从硬盘中查找模块脚本并加载。 require支持相对路径查找模块,例如上面代码中require(‘./moduleExample’)中的“./”就代表在当前目录下查找。如果不 是相当路径,例如 require(‘http’),node则会到require.paths中去查找,例如我的系统require.paths为: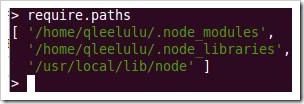
当require(‘http’)的时候,node的查找路径为:
1、/home/qleelulu/.node_modules/http 2、/home/qleelulu/.node_modules/http.js 3、/home/qleelulu/.node_modules/http.node 4、/home/qleelulu/.node_modules/http/index.js 5、/home/qleelulu/.node_modules/http/index.node 6、/home/qleelulu/.node_libraries/http 7、/home/qleelulu/.node_libraries/http.js 8、参考前面
再看回前面的代码,http.createServer中的回调函数中的request注册了两个事件,前面提到过node的一个特点是事件驱动 的,所以这种事件绑定你会到处看到(想想jQuery的事件绑定?例如$(‘a’).click(fn))。关于node的事件我们在后面再细说。 request对象的data事件会在接收客户端post上来的数据时候触发,而end事件则会在最后触发。所以我们在data事件里面处理接收到的数据 (例如post过来的form表单数据),在end事件里面通过handlerRequest 函数来统一处理所有的请求并分发给相应的controller action处理。 handlerRequest的代码如下:
var route = require('./route'); var handlerRequest = function(req, res){ //通过route来获取controller和action信息 var actionInfo = route.getActionInfo(req.url, req.method); //如果route中有匹配的action,则分发给对应的action if(actionInfo.action){ //假设controller都放到当前目录的controllers目录里面,还记得require是怎么搜索module的么? var controller = require('./controllers/'+actionInfo.controller); // ./controllers/blog if(controller[actionInfo.action]){ var ct = new controllerContext(req, res); //动态调用,动态语言就是方便啊 //通过apply将controller的上下文对象传递给action controller[actionInfo.action].apply(ct, actionInfo.args); }else{ handler500(req, res, 'Error: controller "' + actionInfo.controller + '" without action "' + actionInfo.action + '"') } }else{ //如果route没有匹配到,则当作静态文件处理 staticFileServer(req, res); } };
这里导入来一个route模块,route根据请求的url等信息去获取获取controller和action的信息,如果获取到,则通过动态调用调用action方法,如果没有匹配的action信息,则作为静态文件处理。 下面是route模块的代码:
var parseURL = require('url').parse; //根据http请求的method来分别保存route规则 var routes = {get:[], post:[], head:[], put:[], delete:[]}; /** * 注册route规则 * 示例: * route.map({ * method:'post', * url: /\/blog\/post\/(\d+)\/?$/i, * controller: 'blog', * action: 'showBlogPost' * }) */ exports.map = function(dict){ if(dict && dict.url && dict.controller){ var method = dict.method ? dict.method.toLowerCase() : 'get'; routes[method].push({ u: dict.url, //url匹配正则 c: dict.controller, a: dict.action || 'index' }); } }; exports.getActionInfo = function(url, method){ var r = {controller:null, action:null, args:null}, method = method ? method.toLowerCase() : 'get', // url: /blog/index?page=1 ,则pathname为: /blog/index pathname = parseURL(url).pathname; var m_routes = routes[method]; for(var i in m_routes){ //正则匹配 r.args = m_routes[i].u.exec(pathname); if(r.args){ r.controller = m_routes[i].c; r.action = m_routes[i].a; r.args.shift(); //第一个值为匹配到的整个url,去掉 break; } } //如果匹配到route,r大概是 {controller:'blog', action:'index', args:['1']} return r; };
map方法用于注册路由规则,我们新建一个config.js的文件,来配置route规则:
//config.js var route = require('./route'); route.map({ method:'get', url: /\/blog\/?$/i, controller: 'blog', action: 'index' });
如果请求的url有匹配的route规则,则会返回controller和action信息。例如上面的route配置,当访问 /blog 这个url的时候,则会调用 ./controllers/blog.js 模块里面的index函数。 当调用action的时候,会传递controllerContext给acation:
var ct = new controllerContext(req, res); //动态调用,动态语言就是方便啊 //通过apply将controller的上下文对象传递给action controller[actionInfo.action].apply(ct, actionInfo.args);
这里会通过apply将controllerContext作为action的this,并传递args作为action的参数来调用action。 ontrollerContext封装了一些action会用到的方法:
//controller的上下文对象 var controllerContext = function(req, res){ this.req = req; this.res = res; this.handler404 = handler404; this.handler500 = handler500; }; controllerContext.prototype.render = function(viewName, context){ viewEngine.render(this.req, this.res, viewName, context); }; controllerContext.prototype.renderJson = function(json){ viewEngine.renderJson(this.req, this.res, json); };
在action中处理完逻辑获取获取到用户需要的数据后,就要呈现给用户。这就需要viewEngine来处理了。ViewEngine的代码如下:
var viewEngine = { render: function(req, res, viewName, context){ var filename = path.join(__dirname, 'views', viewName); try{ var output = Shotenjin.renderView(filename, context); }catch(err){ handler500(req, res, err); return; } res.writeHead(200, {'Content-Type': 'text/html'}); res.end(output); }, renderJson: function(res, json){ //TODO: } };
这里viewEngine主要负责模板解析。node有很多的可用的模块,模板解析模块也有一大堆,不过这里我们是要“玩”,所以模板解析系统我们这里使用jstenjin来稍作修改:
//shotenjin.js 增加的代码 //模板缓存,缓存解析后的模板 Shotenjin.templateCatch = {}; //读取模板内容 //在模板中引用模板使用: {# ../layout.html #} Shotenjin.getTemplateStr = function(filename){ //console.log('get template:' + filename); var t = ''; //这里使用的是同步读取 if(path.existsSync(filename)){ t = fs.readFileSync(filename, 'utf-8'); }else{ throw 'View: ' + filename + ' not exists'; } t = t.replace(/\{#[\s]*([\.\/\w\-]+)[\s]*#\}/ig, function(m, g1) { var fp = path.join(filename, g1.trim()) return Shotenjin.getTemplateStr(fp); }); return t; }; Shotenjin.renderView = function(viewPath, context) { var template = Shotenjin.templateCatch[viewPath]; if(!template){ var template_str = Shotenjin.getTemplateStr(viewPath); var template = new Shotenjin.Template(); template.convert(template_str); //添加到缓存中 Shotenjin.templateCatch[viewPath] = template; } var output = template.render(context); return output; }; global.Shotenjin = Shotenjin;
增加的代码主要是读取模板的内容,并解析模板中类似 {# ../layout.html #} 的标签,递归读取所有的模板内容,然后调用jstenjin的方法来解析模板。 这里读取文件内容使用的是fs.readFileSync,这是同步阻塞读取文件内容的,和我们平时使用的大多编程语言一样,而fs.readFile的 非阻塞异步读。 这里的shotenjin.js原来是给客户端web浏览器javascript解析模板用的,现在拿到node.js来用,完全不用修改就正常工作。 Google V8真威武。 现在基本的东西都完成了,但是对于静态文件,例如js、css等我们需要一个静态文件服务器:
var staticFileServer = function(req, res, filePath){ if(!filePath){ filePath = path.join(__dirname, config.staticFileDir, url.parse(req.url).pathname); } path.exists(filePath, function(exists) { if(!exists) { handler404(req, res); return; } fs.readFile(filePath, "binary", function(err, file) { if(err) { handler500(req, res, err); return; } var ext = path.extname(filePath); ext = ext ? ext.slice(1) : 'html'; res.writeHead(200, {'Content-Type': contentTypes[ext] || 'text/html'}); res.write(file, "binary"); res.end(); }); }); }; var contentTypes = { "aiff": "audio/x-aiff", "arj": "application/x-arj-compressed" //省略 }
简单来说就是读取文件内容并写入到response中返回给客户端。 现在该有的都有了,我们写一个action:
// ./controllers/blog.js exports.index = function(){ this.render('blog/index.html', {msg:'Hello World'}); };
blog/index.html的内容为:
{# ../../header.html #}
n2Mvc Demo
#{msg}
{# ../../footer.html #}
接着,就是写一个脚本来启动我们的n2Mvc了:
// run.js var n2MvcServer = require('./server'); n2MvcServer.runServer();
ok,运行我们的启动脚本: 在浏览器访问看看: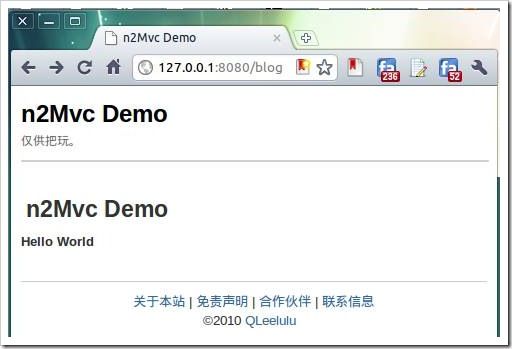
嗯嗯,一切正常。 好,接下来我们再写一个获取新浪微博最新微博的页面。首先,我们在config.js中增加一个route配置:
route.map({ method:'get', url: /\/tweets\/?$/i, controller: 'blog', action: 'tweets' });
然后开始写我们的cnotroller action:
var http = require('http'), events = require("events"); var tsina_client = http.createClient(80, "api.t.sina.com.cn"); var tweets_emitter = new events.EventEmitter(); // action: tweets exports.tweets = function(blogType){ var _t = this; var listener = tweets_emitter.once("tweets", function(tweets) { _t.render('blog/tweets.html', {tweets: tweets}); }); get_tweets(); }; function get_tweets() { var request = tsina_client.request("GET", "/statuses/public_timeline.json?source=3243248798", {"host": "api.t.sina.com.cn"}); request.addListener("response", function(response) { var body = ""; response.addListener("data", function(data) { body += data; }); response.addListener("end", function() { var tweets = JSON.parse(body); if(tweets.length > 0) { console.log('get tweets \n'); tweets_emitter.emit("tweets", tweets); } }); }); request.end(); }
这里使用http.createClient来发送请求获取新浪微博的最新微博,然后注册相应事件的监听。这里详细说下node的事件系 统:EventEmitter。 EventEmitter可以通过require(‘events’). EventEmitter来访问,创建一个 EventEmitter的实例emitter后,就可以通过这个emitter来注册、删除、发出事件了。 例如上面的代码中,先创建来一个EventEmitter的实例:
var tweets_emitter = new events.EventEmitter();
然后用once注册一个一次性的事件监听:
var listener = tweets_emitter.once("tweets", function(tweets) { _t.render('blog/tweets_data.html', {tweets: tweets}); });
once注册的事件在事件被触发一次后,就会自动移除。 最后,通过emit来发出事件:
tweets_emitter.emit("tweets", tweets);
这样,整个事件的流程都清晰了。 下面写一下显示tweets的模板:
万事大吉,运行并访问:

附一个简单的和Django的对比测试
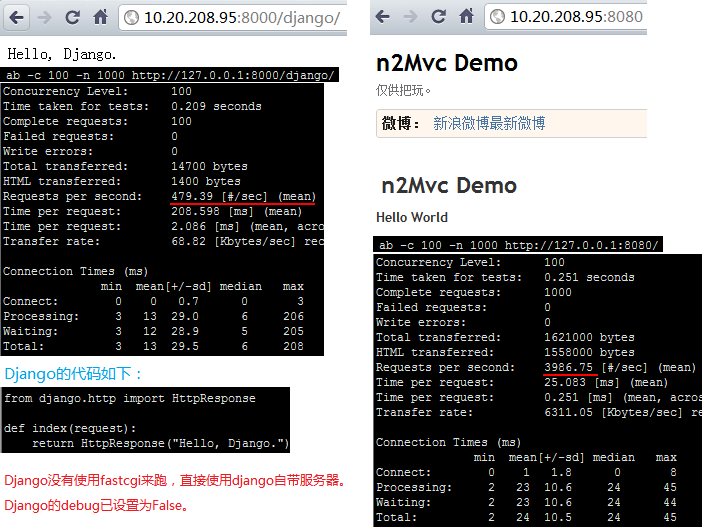
后记
本文写的mvc框架完全是为了尝试node.js,其实node已经有很多的 Modules可以用,也有比较成熟的web框架Express。如果你要实现一个模块之前,可以先到node的modules页面查找下有没有你需要的模块先。 本文示例源代码:learnNode.zip
一些资源:
node.js的文档: http://nodejs.org/api.html
How To Node: http://howtonode.org
learning-serverside-javascript-with-node-js: http://net.tutsplus.com/tutorials/javascript-ajax/learning-serverside-javascript-with-node-js/ (中文翻译版: http://www.osseye.com/?p=456 )