Android------Binder servicemanager篇
提示:源码android7.1
要分析binder架构,首先我们要分析的就是servicemanager了,这里servicemanager指的是native层的,java层的只是一层壳而已,servicemanager是整个binder机制的守护进程,它是server和cilent之间沟通的桥梁。servicemanager,server,cilent三者运行在不同的进程,servicemanager在充当守护进程的同时,它也在充当server,为什么这样说了,当server进程注册service到servicemanager时,server是客户端,servicemanager是服务端,当client从servicemanager中获取服务时,client是客户端,servicemanager是服务端,当建立好关系后,client就可以和server通信了。至于servicemanager是怎样称为守护进程的我会在下面的内容中讲解到。
这里我先将本文的内容梳理一下:
1,首先讲解一下servicemanager的启动过程
2,提一下我们的应用程序是如何去获取servicemanager的
3,提一下server进程注册service和client进程获取service的过程
4,讲解一下java层的serviemanager
由于对于驱动的不熟悉,所以我这里的驱动分析不会很详细,见谅。
1》servicemanager的启动过程
找到servicemanger的目录frameworks/native/cmds/servicemanager
看他的编译脚本Android.mk,有如下LOCAL_MODULE := servicemanager LOCAL_INIT_RC := servicemanager.rc
所以我们知道它编译生成的是servicemanger的执行文件,servicemanger是由init进程通过解析servicemanager.rc而创建的(当然如果是android6.0会解析init.rc创建)
servicemanger的入口函数是frameworks/native/cmds/servicemanager/service_manager.c的main函数
int main()
{
struct binder_state *bs;
bs = binder_open(128*1024);
if (!bs) {
ALOGE("failed to open binder driver\n");
return -1;
}
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\n", strerror(errno));
return -1;
}
selinux_enabled = is_selinux_enabled();
sehandle = selinux_android_service_context_handle();
selinux_status_open(true);
if (selinux_enabled > 0) {
if (sehandle == NULL) {
ALOGE("SELinux: Failed to acquire sehandle. Aborting.\n");
abort();
}
if (getcon(&service_manager_context) != 0) {
ALOGE("SELinux: Failed to acquire service_manager context. Aborting.\n");
abort();
}
}
union selinux_callback cb;
cb.func_audit = audit_callback;
selinux_set_callback(SELINUX_CB_AUDIT, cb);
cb.func_log = selinux_log_callback;
selinux_set_callback(SELINUX_CB_LOG, cb);
binder_loop(bs, svcmgr_handler);
return 0;
}
该函数有三个功能:
1,打开binder设备文件,申请内存空间,对应binder_open函数
2,告诉驱动成文上下文管理者,对应binder_become_context_manager函数
3,陷入无限循环,等待client的请求(这里的client包括通讯的客户端和服务端),对应binder_loop函数
先来看下结构体binder_state,该结构体在frameworks/native/cmds/servicemanager/binder.c中
struct binder_state
{
int fd;
void *mapped;
size_t mapsize;
};fd是文件描述符,即表示打开的/dev/binder设备文件描述符;mapped是把设备文件/dev/binder映射到进程空间的起始地址;mapsize是内存映射空间的大小
函数首先执行的binder设备文件的打开操作:
bs = binder_open(128*1024);struct binder_state *binder_open(size_t mapsize)
{
struct binder_state *bs;
struct binder_version vers;
bs = malloc(sizeof(*bs));
if (!bs) {
errno = ENOMEM;
return NULL;
}
bs->fd = open("/dev/binder", O_RDWR | O_CLOEXEC);
if (bs->fd < 0) {
fprintf(stderr,"binder: cannot open device (%s)\n",
strerror(errno));
goto fail_open;
}
if ((ioctl(bs->fd, BINDER_VERSION, &vers) == -1) ||
(vers.protocol_version != BINDER_CURRENT_PROTOCOL_VERSION)) {
fprintf(stderr,
"binder: kernel driver version (%d) differs from user space version (%d)\n",
vers.protocol_version, BINDER_CURRENT_PROTOCOL_VERSION);
goto fail_open;
}
bs->mapsize = mapsize;
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
if (bs->mapped == MAP_FAILED) {
fprintf(stderr,"binder: cannot map device (%s)\n",
strerror(errno));
goto fail_map;
}
return bs;
fail_map:
close(bs->fd);
fail_open:
free(bs);
return NULL;
}open函数对应了kernel/drivers/staging/android/binder.c的binder_open函数,为什么了,答案是在kernel/drivers/staging/android/binder.c中,
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};file_operations应该是linux中的一个结构体,而这里binder驱动将这些文件操作函数全对应了另外的函数,这里我们接着分析binder驱动的binder_open函数
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
binder_debug(BINDER_DEBUG_OPEN_CLOSE, "binder_open: %d:%d\n",
current->group_leader->pid, current->pid);
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current);
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__);
if (binder_debugfs_dir_entry_proc) {
char strbuf[11];
snprintf(strbuf, sizeof(strbuf), "%u", proc->pid);
proc->debugfs_entry = debugfs_create_file(strbuf, S_IRUGO,
binder_debugfs_dir_entry_proc, proc, &binder_proc_fops);
}
return 0;
}
该函数首先定义了一个结构体指针binder_proc *proc,并把当前进程信息保存在proc中,接着把将file文件指针的private_data变量指向proc,这样,在执行文件操作时,就可以通过这个file指针来获取进程信息了,同时这个进程信息还会保存在全局链表binder_procs中。
我们接着分析frameworks/native/cmds/servicemager/binder.c中binder_open函数的mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);mmap的原型是
void* mmap ( void * addr , size_t len , int prot , int flags , int fd , off_t offset );它是对打开的设备文件进行内存映射操作,对应的binder驱动的binder_mmap函数:
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
binder_debug(BINDER_DEBUG_OPEN_CLOSE,
"binder_mmap: %d %lx-%lx (%ld K) vma %lx pagep %lx\n",
proc->pid, vma->vm_start, vma->vm_end,
(vma->vm_end - vma->vm_start) / SZ_1K, vma->vm_flags,
(unsigned long)pgprot_val(vma->vm_page_prot));
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr;
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
#ifdef CONFIG_CPU_CACHE_VIPT
if (cache_is_vipt_aliasing()) {
while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer))) {
pr_info("binder_mmap: %d %lx-%lx maps %pK bad alignment\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer);
vma->vm_start += PAGE_SIZE;
}
}
#endif
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %pK\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
err_alloc_small_buf_failed:
kfree(proc->pages);
proc->pages = NULL;
err_alloc_pages_failed:
mutex_lock(&binder_mmap_lock);
vfree(proc->buffer);
proc->buffer = NULL;
err_get_vm_area_failed:
err_already_mapped:
mutex_unlock(&binder_mmap_lock);
err_bad_arg:
pr_err("binder_mmap: %d %lx-%lx %s failed %d\n",
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}函数首先通过filp->private_data得到在打开设备文件/dev/binder时创建的struct binder_proc结构。内存映射信息放在vma参数中,注意,这里的vma的数据类型是struct vm_area_struct,它表示的是一块连续的虚拟地址空间区域,在函数变量声明的地方,我们还看到有一个类似的结构体struct vm_struct,这个数据结构也是表示一块连续的虚拟地址空间区域,那么,这两者的区别是什么呢?在Linux中,struct vm_area_struct表示的虚拟地址是给进程使用的,而struct vm_struct表示的虚拟地址是给内核使用的,它们对应的物理页面都可以是不连续的。struct vm_area_struct表示的地址空间范围是0~3G,而struct vm_struct表示的地址空间范围是(3G + 896M + 8M) ~ 4G。struct vm_struct表示的地址空间范围为什么不是3G~4G呢?原来,3G ~ (3G + 896M)范围的地址是用来映射连续的物理页面的,这个范围的虚拟地址和对应的实际物理地址有着简单的对应关系,即对应0~896M的物理地址空间,而(3G + 896M) ~ (3G + 896M + 8M)是安全保护区域(例如,所有指向这8M地址空间的指针都是非法的),因此struct vm_struct使用(3G + 896M + 8M) ~ 4G地址空间来映射非连续的物理页面。
这里为什么会同时使用进程虚拟地址空间和内核虚拟地址空间来映射同一个物理页面呢?这就是Binder进程间通信机制的精髓所在了,同一个物理页面,一方映射到进程虚拟地址空间,一方面映射到内核虚拟地址空间,这样,进程和内核之间就可以减少一次内存拷贝了,提到了进程间通信效率。举个例子如,Client要将一块内存数据传递给Server,一般的做法是,Client将这块数据从它的进程空间拷贝到内核空间中,然后内核再将这个数据从内核空间拷贝到Server的进程空间,这样,Server就可以访问这个数据了。但是在这种方法中,执行了两次内存拷贝操作,而采用我们上面提到的方法,只需要把Client进程空间的数据拷贝一次到内核空间,然后Server与内核共享这个数据就可以了,整个过程只需要执行一次内存拷贝,提高了效率。
binder_open函数的分析就到此为止,接着分析frameworks/base/cmds/servicemanager/service_manager.c文件中的main函数的binder_become_context_manager函数:
int binder_become_context_manager(struct binder_state *bs)
{
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
}static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
......
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
switch (cmd) {case BINDER_SET_CONTEXT_MGR:
//这里保证binder_context_mgr_node只创建了
if (binder_context_mgr_node != NULL) {
pr_err("BINDER_SET_CONTEXT_MGR already set\n");
ret = -EBUSY;
goto err;
}
ret = security_binder_set_context_mgr(proc->tsk);
if (ret < 0)
goto err;
if (uid_valid(binder_context_mgr_uid)) {
if (!uid_eq(binder_context_mgr_uid, current->cred->euid)) {
pr_err("BINDER_SET_CONTEXT_MGR bad uid %d != %d\n",
from_kuid(&init_user_ns, current->cred->euid),
from_kuid(&init_user_ns, binder_context_mgr_uid));
ret = -EPERM;
goto err;
}
} else
binder_context_mgr_uid = current->cred->euid;
//对应着servicemanager的实体
binder_context_mgr_node = binder_new_node(proc, 0, 0);
if (binder_context_mgr_node == NULL) {
ret = -ENOMEM;
goto err;
}
binder_context_mgr_node->local_weak_refs++;
binder_context_mgr_node->local_strong_refs++;
binder_context_mgr_node->has_strong_ref = 1;
binder_context_mgr_node->has_weak_ref = 1;
break;
}
......
}其实在应用层的每个binder实体都对应着binder驱动层的一个binder_node节点,然而binder_context_mgr_node比较特殊,它没有对应的binder实体,在整个系统中,它是一个很特殊的存在,任何系统都可以通过句柄0来跨进程访问它。
binder_become_context_manager的分析到此为止,我们接着分析frameworks/native/cmds/service_manager.c的main函数,下一步我们就该分析binder_loop(bs,svcmgr_handler)函数了。
binder_looper函数在frameworks/native/cmds/binder.c中,如下所示:
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
struct binder_write_read bwr;
uint32_t readbuf[32];
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
if (res == 0) {
ALOGE("binder_loop: unexpected reply?!\n");
break;
}
if (res < 0) {
ALOGE("binder_loop: io error %d %s\n", res, strerror(errno));
break;
}
}
}注意它的第二个参数func是函数指针binder_handler,这个函数指针指向了svcmgr_handler函数,这个参数会传递给binder_parse,
struct binder_write_read bwr定义了一个binder_write_read结构体,这个结构体是在kernel/drivers/staging/android/upi/binder.h中声明的,如下:
struct binder_write_read {
binder_size_t write_size; /* bytes to write */
binder_size_t write_consumed; /* bytes consumed by driver */
binder_uintptr_t write_buffer;
binder_size_t read_size; /* bytes to read */
binder_size_t read_consumed; /* bytes consumed by driver */
binder_uintptr_t read_buffer;
};这里会先通过binder_write函数发出BINDER_ENTER_LOOPER命令,用来告诉binder驱动要进入循环状态了。在binder驱动中,凡是用到跨进程通信机制的线程,都会对应一个binder_thread节点,这里的BINDER_ENTER_LOOPER命令会导致该线程的looper状态发生变化
thread->looper=BINDER_THREAD_STATE_ENTERED
其实用户空间和驱动程序之间交互大多数是通过BINDER_WIRTE_READ命令的
比如binder_write(bs, readbuf, sizeof(uint32_t))方法中
int binder_write(struct binder_state *bs, void *data, size_t len)
{
struct binder_write_read bwr;
int res;
bwr.write_size = len;
bwr.write_consumed = 0;
bwr.write_buffer = (uintptr_t) data;
bwr.read_size = 0;
bwr.read_consumed = 0;
bwr.read_buffer = 0;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder_write: ioctl failed (%s)\n",
strerror(errno));
}
return res;
}这时bwr只有write_buffer有数据,通过ioctl我们找到binder驱动的binder_ioctl,对应了case BINDER_WRITE_READ,接着就调用了binder_thread_write函数。
接下来进入for循环,执行ioctl函数,这时bwr只有read_buf有数据,在binder驱动中就会调用binder_thread_read函数
然后就该轮到我们的binder_parse函数了,该函数负责从binder驱动读取传来的数据,
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
int r = 1;
uintptr_t end = ptr + (uintptr_t) size;
while (ptr < end) {
uint32_t cmd = *(uint32_t *) ptr;
ptr += sizeof(uint32_t);
#if TRACE
fprintf(stderr,"%s:\n", cmd_name(cmd));
#endif
switch(cmd) {
case BR_NOOP:
break;
case BR_TRANSACTION_COMPLETE:
break;
case BR_INCREFS:
case BR_ACQUIRE:
case BR_RELEASE:
case BR_DECREFS:
#if TRACE
fprintf(stderr," %p, %p\n", (void *)ptr, (void *)(ptr + sizeof(void *)));
#endif
ptr += sizeof(struct binder_ptr_cookie);
break;
case BR_TRANSACTION: {
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: txn too small!\n");
return -1;
}
binder_dump_txn(txn);
if (func) {
unsigned rdata[256/4];
struct binder_io msg;
struct binder_io reply;
int res;
bio_init(&reply, rdata, sizeof(rdata), 4);
bio_init_from_txn(&msg, txn);
res = func(bs, txn, &msg, &reply);
if (txn->flags & TF_ONE_WAY) {
binder_free_buffer(bs, txn->data.ptr.buffer);
} else {
binder_send_reply(bs, &reply, txn->data.ptr.buffer, res);
}
}
ptr += sizeof(*txn);
break;
}
case BR_REPLY: {
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: reply too small!\n");
return -1;
}
binder_dump_txn(txn);
if (bio) {
bio_init_from_txn(bio, txn);
bio = 0;
} else {
/* todo FREE BUFFER */
}
ptr += sizeof(*txn);
r = 0;
break;
}
case BR_DEAD_BINDER: {
struct binder_death *death = (struct binder_death *)(uintptr_t) *(binder_uintptr_t *)ptr;
ptr += sizeof(binder_uintptr_t);
death->func(bs, death->ptr);
break;
}
case BR_FAILED_REPLY:
r = -1;
break;
case BR_DEAD_REPLY:
r = -1;
break;
default:
ALOGE("parse: OOPS %d\n", cmd);
return -1;
}
}
return r;
}总结一下servicemanager的启动过程:打开binder驱动文件,建立内存映射,成为上下文的管理者,且整个系统只有这样一个管理者,最后进入循环状态,等待client端的请求。
整个过程中,binder驱动起到了至关重要的作用,至此,servicemanager就在Android进程间通讯这块担负起了守护进程的职责。
2》获取servicemanager的过程,获取的过程这里只稍微提一下,具体的分析我想放在《Binder native层架构浅析》中去分析,
作为一个binder服务的提供者,servicemanager需要通过某种方式让使用者得到它的引用对象,Android这里的设计很巧妙,也很简单。Binder引用对象的核心数据是一个实体对象的引用号,它是在驱动内部分配的一个值,binder框架硬性的规定了”0“代表binder,这样用户就可以使用参数”0“直接构造出servicemanager的引用对象,开始使用servicemanager查询服务。
3》提一下addService和getService的过程,在servicemanager进程中有一个全局性的struct svcinfo *svclist变量,这个变量记录着所有添加进系统的“service代理”信息,这些信息被组织成一条单项链表,有人称它们为“服务向量表”
struct svcinfo
{
struct svcinfo *next;
uint32_t handle;
struct binder_death death;
int allow_isolated;
size_t len;
uint16_t name[0];
};如果某个服务进程调用servicemanager的接口,向其注册service,这个注册的动作最后就会走到我们上面提到过的svcmgr_handler函数 case SVC_MGR_ADD_SERVICE
如果某个客户端进程调用servicemanager的接口,想起获取service,这个获取的动作最后就会走到svcmgr_handler函数case SVC_MGR_CHECK_SERVICE
具体的注册和获取的过程可以在《Binder实例分析》中去了解。
4》java层的servicemanager
看一下servicemanager.java的getIServiceManager方法:
private static IServiceManager getIServiceManager() {
if (sServiceManager != null) {
return sServiceManager;
}
// Find the service manager
sServiceManager = ServiceManagerNative.asInterface(BinderInternal.getContextObject());
return sServiceManager;
}来看下继承关系图
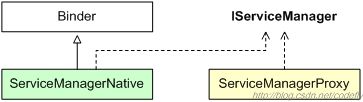
其实熟悉aidl的朋友可以知道,这个servicemanagernative就相当于我们使用aidl时自动生成的stub类
servicemanagernative是一个抽象类,它并没有实现类,它存在的意义似乎只有一个,那就是提供一个静态成员函数asInterface
static public IServiceManager asInterface(IBinder obj)
{
if (obj == null) {
return null;
}
IServiceManager in =
(IServiceManager)obj.queryLocalInterface(descriptor);
if (in != null) {
return in;
}
return new ServiceManagerProxy(obj);
}用户要拿到servicemanager就要拿到他的代理接口,而servicemanagerproxy就是IServicemanager的代理接口,
new ServiceManagerProxy(obj)这里传入的obj就是句柄为0的BpBinder对象,因为queryLocalInterface方法会调用native方法,最后会得到一个BpBInder(0).
这样servicemanagerproxy中的IBinder mRemote对象就保存了一个BpBInder(0).
获得了servicemanaer的代理接口后,就可以调用addService和getService来注册service和获取service的代理接口了。
这里还有一点要提一下,上面我说过servicemanagernative的用处并不大,而且没有实现类,这里透露出一点信息,是不是说明c++层也对应的缺少servicemanager的实体了,的确是这样,servicemanager在c++层被独立为一个单独的进程,而不是常见的binder实体。
参考文献:《深入解析Android5.0系统》;《Android开发艺术探索》;《深入理解Android卷1》;《深入理解Android卷3》;红茶一杯话binder------点击打开链接;gityuan的binder系列------点击打开链接;罗升阳的binder系列------点击打开链接;Andriod Binder机制------点击打开链接;Android深入浅出之binder机制------点击打开链接;理解Android的binder机制-----点击打开链接;轻松理解Androidbinder------点击打开链接;binder service入门------点击打开链接