题记
Elasticsearch当清理缓存( echo 3 > /proc/sys/vm/drop_caches )的时候,出现
如下集群健康值:red,红色预警状态,同时部分分片都成为灰色。 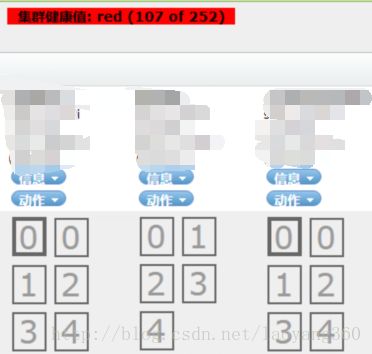
查看Elasticsearch启动日志会发现如下:
集群服务超时连接的情况。
bserver: timeout notification from cluster service. timeout setting [1m], time since start [1m]- 1
该问题排查耗时很长,问题已经解决。
特将问题排查及解决方案详尽的整理出来。
1、集群状态解读
head插件会以不同的颜色显示。
1)、绿色——最健康的状态,代表所有的主分片和副本分片都可用;
2)、黄色——所有的主分片可用,但是部分副本分片不可用;
3)、红色——部分主分片不可用。(此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好。)
参考官网:http://t.cn/RltLEpN(部分中文集群健康状态博文资料翻译的不够精确,以官网为准)
如果集群状态为红色, Head插件显示:集群健康值red 。则说明:至少一个主分片分配失败。
这将导致一些数据以及索引的某些部分不再可用。
尽管如此, ElasticSearch还是允许我们执行查询,至于是通知用户查询结果可能不完整还是挂起查询,则由应用构建者来决定。
2、什么是unassigned 分片?
一句话解释:未分配的分片。
启动ES的时候,通过Head插件不停刷新,你会发现集群分片会呈现紫色、灰色、最终绿色的状态。
3、为什么会出现 unassigned 分片?
如果不能分配分片,例如,您已经为集群中的节点数过分分配了副本分片的数量,则分片将保持UNASSIGNED状态。
其错误码为:ALLOCATION_FAILED。
你可以通过如下指令,查看集群中不同节点、不同索引的状态。
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason- 1
4、出现unassigned 分片后的症状?
head插件查看会:Elasticsearch启动N长时候后,某一个或几个分片仍持续为灰色。
5、unassigned 分片问题可能的原因?
1)INDEX_CREATED:由于创建索引的API导致未分配。
2)CLUSTER_RECOVERED :由于完全集群恢复导致未分配。
3)INDEX_REOPENED :由于打开open或关闭close一个索引导致未分配。 4)DANGLING_INDEX_IMPORTED :由于导入dangling索引的结果导致未分配。 5)NEW_INDEX_RESTORED :由于恢复到新索引导致未分配。 6)EXISTING_INDEX_RESTORED :由于恢复到已关闭的索引导致未分配。 7)REPLICA_ADDED:由于显式添加副本分片导致未分配。 8)ALLOCATION_FAILED :由于分片分配失败导致未分配。 9)NODE_LEFT :由于承载该分片的节点离开集群导致未分配。 10)REINITIALIZED :由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。 11)REROUTE_CANCELLED :作为显式取消重新路由命令的结果取消分配。 12)REALLOCATED_REPLICA :确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。6、集群状态红色如何排查?
症状:集群健康值红色;
日志:集群服务连接超时;
可能原因:集群中部分节点的主分片未分配。
接下来的解决方案主要围绕:使主分片unsigned 分片完成再分配展开。
7、如何Fixed unassigned 分片问题?
方案一:极端情况——这个分片数据已经不可用,直接删除该分片。
ES中没有直接删除分片的接口,除非整个节点数据已不再使用,删除节点。
curl -XDELETE ‘localhost:9200/index_name/’
方案二:集群中节点数量>=集群中所有索引的最大副本数量 +1。
N> = R + 1
其中:
N——集群中节点的数目;
R——集群中所有索引的最大副本数目。
知识点:当节点加入和离开集群时,主节点会自动重新分配分片,以确保分片的多个副本不会分配给同一个节点。换句话说,主节点不会将主分片分配给与其副本相同的节点,也不会将同一分片的两个副本分配给同一个节点。
如果没有足够的节点相应地分配分片,则分片可能会处于未分配状态。
由于我的集群就一个节点,即N=1;所以R=0,才能满足公式。
问题就转嫁为:
1)添加节点处理,即N增大;
2)删除副本分片,即R置为0。
R置为0的方式,可以通过如下命令行实现:
root@tyg:/# curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '
{"acknowledged":true}- 1
- 2
方案三:allocate重新分配分片。
如果方案二仍然未解决,可以考虑重新分配分片。
可能的原因:
1)节点在重新启动时可能遇到问题。正常情况下,当一个节点恢复与群集的连接时,它会将有关其分片的信息转发给主节点,然后主节点将这分片从“未分配”转换为“已分配/已启动”。
2)当由于某种原因(例如节点的存储已被损坏)导致该进程失败时,分片可能保持未分配状态。
在这种情况下,您必须决定如何继续:尝试让原始节点恢复并重新加入集群(并且不要强制分配主分片);
或者强制使用Reroute API分配分片并重新索引缺少的数据原始数据源或备份。
如果您决定分配未分配的主分片,请确保将“allow_primary”:“true”标志添加到请求中。
ES5.X使用脚本如下:
NODE="YOUR NODE NAME"
IFS=$'\n'
for line in $(curl -s 'localhost:9200/_cat/shards' | fgrep UNASSIGNED); do INDEX=$(echo $line | (awk '{print $1}')) SHARD=$(echo $line | (awk '{print $2}')) curl -XPOST 'localhost:9200/_cluster/reroute' -d '{ "commands": [ { " allocate_replica ": { "index": "'$INDEX'", "shard": '$SHARD', "node": "'$NODE'", "allow_primary": true } } ] }' done
—————————————————————————————