Spark-steamming性能变慢的问题分析-内存分析
Spark-steamming性能变慢的问题分析
知识背景:需要从spark的DAG优化、内存、CPU、序列化、shuffle磁盘读写、GC回收情况请角度考虑相应的问题。
1.在集群中spark内存现状:
[外链图片转存失败(img-bL8CCXXb-1566547586815)(C:\Users\user\AppData\Roaming\Typora\typora-user-images\1565329563298.png)]

注释:(当前spark-streaming中存在问题)
-
内存GC耗费时间太长,超过总处理时间的10%,约为15~20%;
-
当前的并发能力不足:1min,100条数据,勉强;
2.ML性能变慢的原因分析?
2.1初步优化方向与思路:
1.查看;老年代GC次数约占到新生代的10%左右,所以,适当增加年轻代的空间,减少向old gen中加入新对象;
2.优化自身程序中的业务代码,对象问题:
3.如果是内存溢出的问题OOM,可以查看相应的内存溢出的日志信息,也可以将GCdump到本地分析内存溢出的原因;
2.2内存日志查看
(1)执行过程中,年轻代和老年代内存GC情况:
[Full GC (Ergonomics) [PSYoungGen: 464384K->0K(928768K)] [ParOldGen: 2581709K->1739569K(2786816K)] 3046093K->1739569K(3715584K), [Metaspace: 69820K->69820K(1114112K)], 0.5739871 secs] [Times: user=2.94 sys=0.00, real=0.57 secs]
[GC (Allocation Failure) [PSYoungGen: 464384K->217120K(928768K)] 2203953K->1956690K(3715584K), 0.1097106 secs] [Times: user=0.81 sys=0.00, real=0.11 secs]
可以看到有事Old Gen(2.58G->1.7G (总量2.7G))满了引发的fullGC.(执行中这种情况很多)
(2)执行过程中,年轻代和老年代内存GC情况:
Full GC (System.gc()) [PSYoungGen: 13905K->0K(530432K)] [ParOldGen: 80141K->78773K(2786816K)] 94047K->78773K(3317248K), [Metaspace: 71631K->69838K(1114112K)], 0.2263314 secs] [Times: user=1.19 sys=0.00, real=0.23 secs]
执行退出时候,GC回收个情况
Heap
PSYoungGen total 928768K, used 103394K [0x000000076af80000, 0x00000007c0000000, 0x00000007c0000000)
eden space 464384K, 20% used [0x000000076af80000,0x0000000770ad8ab0,0x0000000787500000)
from space 464384K, 2% used [0x00000007a3a80000,0x00000007a44200e8,0x00000007c0000000)
to space 464384K, 0% used [0x0000000787500000,0x0000000787500000,0x00000007a3a80000)
ParOldGen total 2786816K, used 2247582K [0x00000006c0e00000, 0x000000076af80000, 0x000000076af80000)
object space 2786816K, 80% used [0x00000006c0e00000,0x000000074a0e7980,0x000000076af80000)
Metaspace used 70090K, capacity 71570K, committed 73472K, reserved 1114112K
class space used 8776K, capacity 9090K, committed 9472K, reserved 1048576K
代码中,老年代占比很大。
root@whzbslave17:/usr/lib/jvm/jdk1.8.0_172/jre/bin# ./java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=2093272448 -XX:MaxHeapSize=32210157568 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
这是生产环境从虚拟机上查询到JVM信息:
-
java默认堆大小为2G,最大堆大小为32G;
-
垃圾回收器回收使用ParallelGC(年轻代使用parallel Scavenge复制算法,老年代采用parallel Sweep标记-整理算法)

2.3 内存工具查看情况
使用jconsole进行内存分析工具查看得知:
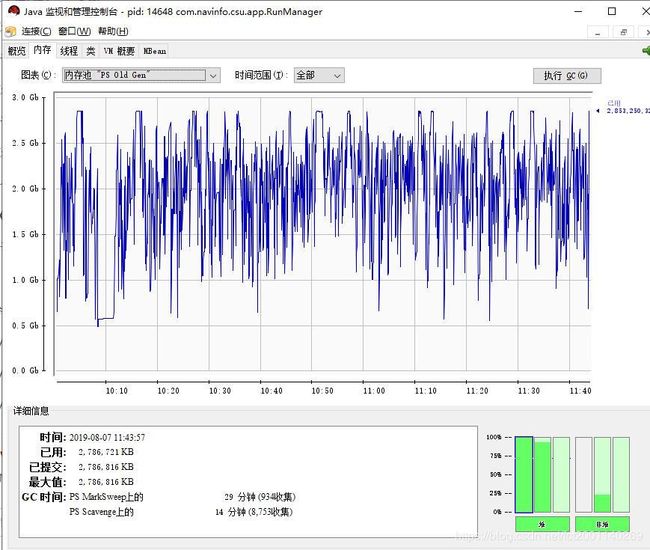
由图可知:大部分的fullGC引起是由于老年代Old Gen超过了触发阈值(约为2.55G左右),而进行了fullGC,而不发送kafka数据(即spark-streaming不接受数据之后),如下图,Old Gen恢复到正常水平(占用内存只有75M).
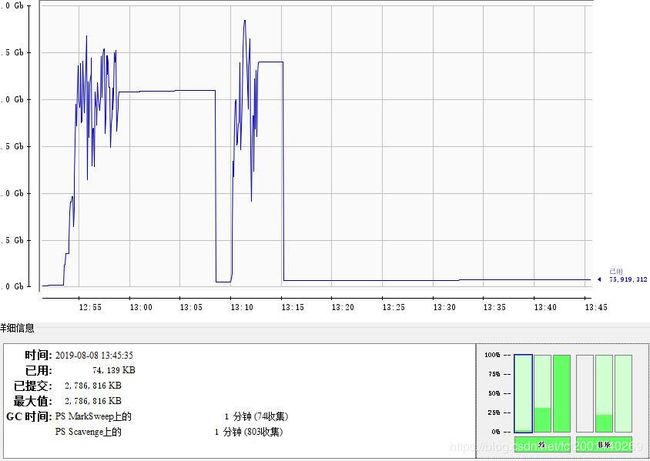
现象描述,fullGC的原因是Old Gen中频繁装满,不停回收,回收次数约占总GC时间的10%;回收时间约战总GC时间的2/3(其实,很多时候FullGC是可以避免或减少的);
引用网上作者的观点:
Full GC本身是好的,可以清除老年代的垃圾,但是如果Full GC发生的频率高了,就会影响性能,同时意味着系统内存分配机制出现问题。
因为Full GC本身执行时间较长(甚至超过1秒),而且除非采用G1 GC,否则其它的GC方式都会或多或少挂起所有线程执行(Stop-the-world),如果Full GC频繁发生,系统被挂起的次数就会增加,响应时间就会变慢。
同时,Full GC频繁发生,意味着你的内存分配机制存在问题,也许是内存泄露,有大量内存垃圾不断在老年代产生;也许是你的大对象(缓存)过多;也有可能是你的参数设置不好,minor GC清理不掉内存,导致每次minor GC都会触发Full GC;还有可能是你的老年代大小参数设置错误,老年代过小等等原因
那么进入老年代的原因是什么呢?
参考一段网上的评述:
主要有下面三种方式:大对象,长期存活的对象,动态对象年龄判定
-
1:大对象直接进入老年代。比如很长的字符串,或者很大的数组等,参数-XX:PretenureSizeThreshold=3145728设置,超过这个参数设置的值就直接进入老年代
-
2:长期存活的对象进入老年代。在堆中分配内存的对象,其内存布局的对象头中(Header)包含了 GC 分代年 龄标记信息。如果对象在 eden 区出生,那么它的 GC 分代年龄会初始值为 1,每熬过一次 Minor GC 而不被回收,这个值就会增 加 1 岁。当它的年龄到达一定的数值时,就会晋升到老年代中,可以通过参数-XX:MaxTenuringThreshold设置年龄阀值(默认是 15 岁)
-
3:当 Survivor 空间中相同年龄所有对象的大小总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,而不需要达到默认的分代年龄。
3.结论与建议
背景知识:从Redis读取的业务基础数据,一个Object1对象中包含Object1
结论与建议:
- 1.内存中的OOM问题多数情况下是从kafka拉取过快,导致spark内部的数据积压,从而导致内存溢出, 可以初步判定不是内存泄漏的问题;通过查看元空间中的内存大小约为67M左右,也排除了加载的类导致的FullGC问题;
- 2.重点关注应用程序中存在的大对象:例如大数组、大字符串等,这种需要连续内存空间的强引用对象在eden Gen或者s0,s1中没有办法分配时候,直接进入老年代Old Gen,导致频繁fullGC. 考虑到程序中大对象多大的问题,因此应该重点对应用内部的业务逻辑进行优化;