【读】关系抽取—(5)RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information
大趋势是历史的背景板,看清并且跟随;
小趋势是环境的新变量,发现并且利用。
这是一篇Relation Extraction相关的paper,出自于EMNLP 2018论文, Improving Distantly-Supervised Neural Relation Extraction using Side Information。
目录
Abstract
1 Introduction
2 Related Work
3 Background: Graph Convolution Networks (GCN)
3.1 GCN on Labeled Directed Graph
3.2 Integrating Edge Importance
4 RESIDE Overview
5 RESIDE Details
5.1 Syntactic Sentence Encoding
5.2 Side Information Acquisition
5.3 Instance Set Aggregation
6 Experimental Setup
6.1 Datasets
6.2 Baselines
6.3 Evaluation Criteria
7 Results
7.1 Performance Comparison
7.2 Ablation Results
7.3 Effect of Relation Alias Side Information
8 Conclusion
Acknowledgements
LINK
Abstract
远程监视关系提取(RE)方法通过将知识库中的关系实例与非结构化文本自动对齐来训练提取器。除了关系实例之外,KBs还经常包含其他相关的侧信息,例如关系别名(例如,公司关系创始人的别名)。RE模型通常忽略这些现成的边信息。在本文中,我们提出了一种远程监控神经关系提取方法,它利用KBs中的附加边信息来改进关系提取。它使用实体类型和关系别名信息在预测关系时施加软约束。Reside使用图形卷积网络(GCN)从文本中对语法信息进行编码,并在有限的边信息可用时提高性能。通过对基准数据集的大量实验,我们证明了Reside的有效性。我们已经使Reside的源代码可用,以鼓励可复制的研究。
1 Introduction
大型知识库(KBs)的构建,如Freebase (Bollacker et al., 2008)和Wikidata (Vrande ci c and Kr otzsch, 2014),已被证明在许多自然语言处理(NLP)任务中有用,如问答、web搜索等。关系提取(RE)试图通过从纯文本中提取实体对之间的语义关系来填补这一空白。在指定实体对之后,可以将此任务建模为一个简单的分类问题。在形式上,给定一个来自KB的实体对(e1,e2)和一个带注释的实体句(或实例),我们的目标是从一个预定义的关系集合中预测关系r,它存在于e1和e2之间。如果没有关系存在,我们简单地将其标记为NA。
大多数监督关系提取方法都需要大量标记的训练数据,这是一种昂贵的构造方法。远程监控(DS) (Mintz et al., 2009)有助于自动构建此数据集,假设如果两个实体在KB中有关系,那么所有提到这些实体的句子都表示相同的关系。虽然这种方法可以很好地生成大量的训练实例,但DS假设并不适用于所有情况。Riedel等人(2010);Hoffmann等(2011);Surdeanu等人(2012)提出了基于多实例的学习来放松这一假设。然而,他们使用NLP工具来提取特性,这些特性可能会有噪声。
最近,神经模型在RE. Zeng等人(2014,2015)上展示了很好的性能,使用卷积神经网络(tional neural network, CNN)来学习实例的表示。(Lin等人,2016;Jat等人,2018年)。依赖分析中的句法信息被Mintz等人使用(2009;他等人,2018),用于捕获令牌之间的长期依赖关系。最近提出的图卷积网络(GCN) (Defferrard et al., 2016)已经被有效地用于编码这些信息(Marcheggiani和Titov, 2017;Bastings等人,2017)。然而,上述模型仅依赖于远程监控的噪声实例。
相关的边信息可以有效的改善RE。例如,在这句话中,微软是由比尔盖茨创立的。比尔盖茨(个人)和微软(组织)的类型信息可以帮助预测公司的正确关系创始人。这是因为每个关系都约束其目标实体的类型。同样,关系短语“was started by”提取使用开放信息提取(Open Information Extraction, Open IE)方法可能是有用的,因为关系创建公司的别名,例如,建立,共同创建,等等,都是可用的。用于DS的KBs很容易提供这种信息,而目前的模型还没有完全利用这些信息。
在本文中,我们提出了一种新的远程监督关系提取方法,它通过基于神经网络的体系结构利用知识库的额外监督。Reside有原则地使用来自KBs的实体类型和关系别名信息,在预测关系时施加软约束。它利用从图卷积网络(GCN)中获得的编码句法信息,以及嵌入的边信息来改进神经关系提取。我们的贡献可以总结如下
- 我们提出了一种新的神经方法Reside,它利用来自知识库的额外监督,以一种原则性的方式来改善远程监督RE。
- Reside使用图形卷积网络(GCN)来建模语法信息,并已证明即使在有限的边信息情况下也具有竞争力。
- 通过对基准数据集的广泛实验,我们证明了Reside在最先进的基线上的有效性。
本文使用的驻留源代码和数据集可以在http://github.com/malllabiisc/RESIDE.上找到。
2 Related Work
Distant supervision:关系提取是一个句子中两个实体间关系的识别。在监督范式中,任务被认为是一个多类分类问题,但缺少大的标记训练数据。为了解决这一限制,(Mintz et al.,2009)提出了创建大型数据集的远程监控(DS)假设,通过将文本与给定知识库(KB)进行启发式对齐。由于这个假设并不总是正确的,一些句子可能会被错误地贴上标签。为了减轻这种缺陷,Riedel等人(2010)放宽了对多实例单标签学习的远程监控。随后,为了处理实体间的重叠关系(Hoffmann et al.,2011;Surdeanu等人,2012)提出多实例多标签学习范式。
Neural Relation Extraction:上述方法的性能很大程度上依赖于手工工程特性的质量。Zeng等人(2014)提出了一种基于端到端CNN的方法,可以自动捕获相关的词汇和句子级别特征。该方法通过分段最大池(Zeng et al.,2015)进一步改进。Lin等人(2016);Nagarajan等人(2017)使用Attention(Bahdanau等人,2014)从多个有效句子中学习。我们也利用注意力来学习句子和bag的表示。
基于依赖树的特性被发现与关系提取相关(Mintz et al.,2009)。他等人(2018)使用它们通过一个基于tree-gru的递归模型获得有希望的结果。在驻留中,我们使用了最近提出的图卷积网络(Defferrard et al.,2016;(Kipf and Welling, 2017),已被发现对句法信息建模相当有效(Marcheggiani和Titov, 2017;Nguyen和Grishman, 2018;Vashishth等人,2018a)。
Side Information in RE:RE (Ji et al.,2017)使用了KB提供的实体描述(Ji et al.,2017),但并非所有实体都可以使用这些信息。Ling andWeld(2012)使用了实体的类型信息;Liu等人(2014)作为模型中的特征。Yaghoobzadeh等人(2017)也试图通过他们的联合实体类型和关系提取模型来降低DS中的噪声。然而,像Freebase这样的KBs很容易提供可直接利用的可靠类型信息。在我们的工作中,我们有原则地使用了从知识库中获得的实体类型和关系别名信息。我们还使用了无监督开放信息提取(Open IE)方法(Mausam et al.,2012;在不需要任何预定义的本体的情况下,自动发现可能的关系,作为5.2节中定义的侧信息使用。
3 Background: Graph Convolution Networks (GCN)
在本节中,我们将简要概述图卷积网络(GCN),它适用于具有有向边和标记边的图(Marcheggiani和Titov, 2017)。
3.1 GCN on Labeled Directed Graph
对于有向图,![]()
![]() 和
和![]() 分别表示顶点和边的集合,从节点u到带有标签luv的节点v的边表示为(u,v,luv)。由于有向边缘中的信息并不一定沿着其方向传播,因此(Marcheggiani和Titov, 2017)我们定义了一个更新的边缘集
分别表示顶点和边的集合,从节点u到带有标签luv的节点v的边表示为(u,v,luv)。由于有向边缘中的信息并不一定沿着其方向传播,因此(Marcheggiani和Titov, 2017)我们定义了一个更新的边缘集![]() ,其中包含了逆边
,其中包含了逆边![]() 和selfloops
和selfloops ![]() 与原始边缘集
与原始边缘集![]() 一起,其中T是表示自循环的特殊符号。对于
一起,其中T是表示自循环的特殊符号。对于![]() 中的每个节点v,我们有一个初始表示
中的每个节点v,我们有一个初始表示![]() 。在使用GCN时,我们只考虑它的近邻(Kipf和Welling, 2017),就得到了一个更新的d维隐藏表示
。在使用GCN时,我们只考虑它的近邻(Kipf和Welling, 2017),就得到了一个更新的d维隐藏表示![]() 。这可以表述为:
。这可以表述为:

3.2 Integrating Edge Importance
在自动构造的图中,有些边可能是错误的,因此需要丢弃。GCN中的边控(Bastings et al., 2017;Marcheggiani和Titov, 2017)让我们通过抑制噪声边缘来缓解这个问题。这是通过为图中的每条边分配一个相关分数来实现的。第k层,边![]() 被计算为:
被计算为:

4 RESIDE Overview
在多实例学习范式中,我们得到一组句子(或实例){s1,s2,...,sn},对于给定的实体对,任务是预测它们之间的关系。Reside由三个组件组成,用于学习给定包的表示形式,它被提供给softmax分类器。我们简要介绍了Reside的组件。每个组件将在后面的部分中详细描述。Reside的总体体系结构如图1所示。

1. Syntactic Sentence Encoding:Reside在连接的位置和单词嵌入上使用Bi-GRU来编码每个令牌的本地上下文。为了捕获远程依赖,使用依赖树上的GCN,并将其编码附加到每个令牌的表示中。最后,对令牌的关注用于压制不相关的令牌,并获得对整个句子的嵌入。更多细节见5.1节。
2. Side Information Acquisition:在这个模块中,我们使用了来自KBs的额外监督,并使用开放的IE方法来获取相关的边信息。模型稍后将使用这些信息,如5.2节所述。
3. Instance Set Aggregation:在本部分中,将句法编码器的句子表示与上一步得到的匹配关系嵌入连接起来。然后,使用注意重于句子,学习整个包的表示。然后,在将实体类型嵌入到softmax分类器中进行关系预测之前,将其与实体类型连接起来。更多细节请参阅5.3部分。
5 RESIDE Details
在本节中,我们提供了RESIDE组件的详细描述。
5.1 Syntactic Sentence Encoding
袋子里每个句子都有m个代币{w1,w2,...,wm},我们首先通过k维GloVe embedding来表示每个令牌(Pennington et al.,2014)。为了合并令牌相对于目标实体的相对位置,我们使用p维位置嵌入,如Zeng et al.,2014)。将组合令牌嵌入到一起,得到句子表示![]() 。然后,使用Bi-GRU (Cho et al.,2014)除以H,得到新的句子表示
。然后,使用Bi-GRU (Cho et al.,2014)除以H,得到新的句子表示![]() ,其中dgru是隐藏的状态维数。Bi-GRUs被发现在多个任务中对令牌上下文的编码非常有效(Sutskever et al.,2014;Graves等人,2013)。
,其中dgru是隐藏的状态维数。Bi-GRUs被发现在多个任务中对令牌上下文的编码非常有效(Sutskever et al.,2014;Graves等人,2013)。
虽然Bi-GRU能够捕获本地上下文,但它无法捕获可以通过依赖关系边缘捕获的远程依赖关系。前期工作(Mintz et al., 2009;He et al.,2018)利用句法依赖树的特征来改进关系提取。基于他们的工作,我们使用句法图卷积网络来编码这些信息。对于给定的句子,我们使用Stanford CoreNLP (Manning et al.,2014)生成它的依赖树。然后我们在依赖关系图上运行GCN,使用公式2更新嵌入,以Hgru作为输入。由于依赖关系图有55个不同的边缘标签,将所有这些标签组合在一起显著地使模型参数化。因此,以下(Marcheggiani和Titov, 2017;Nguyen和Grishman, 2018;Vashishth等人,2018a)。根据边缘{forward(→),back(←),selfloop (T)}的方向,我们只使用三个边缘标签。我们为一条边(u,v,luv)如下:

在这里,g^k_iu表示式1中定义的边进门,Liu表示上述定义的边标。在整个实验中,我们使用ReLU作为激活函数f。将GCN的句法图编码添加到Bi-GRU输出中,得到最终令牌表示,h^concat_i![]() 。由于并非所有令牌都与RE任务同等相关,因此我们使用注意计算每个令牌的相关性程度(Jat et al., 2018)。对于句子中的令牌wi,注意权αi计算为:
。由于并非所有令牌都与RE任务同等相关,因此我们使用注意计算每个令牌的相关性程度(Jat et al., 2018)。对于句子中的令牌wi,注意权αi计算为:
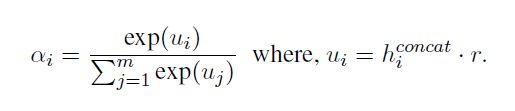
其中r为随机查询向量,ui为分配给每个令牌的关联分数。注意值图{αi}是通过{ui}采用softmax来计算的。一个句子s的表示形式,作为其标记的加权和给出s=![]()

5.2 Side Information Acquisition
通过发现相关的侧信息,可以提高多个任务的性能(Ling and Weld, 2012;Vashishth等人,2018b)。在基于远程监控的关系提取中,由于实体来自知识库,因此可以利用它们的知识来改进关系提取。此外,几种非监督关系提取方法(Open IE) (Angeli et al., 2015;Mausam et al., 2012)允许提取目标实体之间的关系短语,不需要任何预定义的本体,可以用来获取相关的侧信息。在驻留中,我们使用开放的IE方法和来自KB的额外监督来改进神经关系提取。
Relation Alias Side Information
Reside使用Stanford Open IE (Angeli et al.,2015)提取目标实体之间的关系短语,我们用p表示,如图2所示,对于句子Matt Coffin, executive of lowermybills, a company...,Open IE方法提取“executive of”之间的Matt Coffin和lowermybills。此外,我们通过在依赖关系路径中从目标实体包含hop distance的令牌来扩展P。依赖解析的这些特性过去曾被Mintz等人利用(2009;他等人,2018年)。P中提取的短语与关系别名的匹配程度可以为判断该关系与句子的相关性提供重要线索。像Wikidata这样的KBs提供了这样的关系别名,可以很容易地加以利用。在驻留中,我们使用改写数据库(PPDB)进一步扩展关系别名集(Pavlick et al., 2015)。我们注意到,即使在关系别名不可用的情况下,仅提供关系的名称也会带来竞争性能。我们将在第7.3节进一步探讨这一点。
为了将P与PPDB扩展关系别名setR匹配,我们使用GloVe embeddings嵌入在d维空间中(Pennington et al.,2014)。使用嵌入词来投射短语有助于进一步扩展这些集合,因为语义相似的词在嵌入空间中更接近(Mikolov et al., 2013;彭宁顿等人,2014)。然后,对于每一个短语p∈P,我们计算它与所有关系别名在R上的余弦距离,取与最近关系别名对应的关系作为句子的匹配关系。我们在余弦距离上使用一个阈值来去除噪声别名。在驻留中,我们为每个关系定义一个k维嵌入,我们将其称为匹配关系嵌入(h^rel)。对于给定的句子,h^rel与其表征物s连接,由句法句法编码器(5.1节)得到,如图1所示。对于带有|P| > 1的句子,我们可能会得到多个匹配关系。在这种情况下,我们取他们嵌入的平均值。我们假设这有助于提高性能,并发现它是真实的,如第7节所示。
Entity Type Side Information
目标实体的类型信息在关系提取方面有很好的效果(Ling and Weld, 2012;Yaghoobzadeh等人,2017)。每个关系对实体的类型都有一定的限制,实体可以是它的主语和宾语。例如,人/出生地的关系只能发生在人和地点之间。远程监管的句子是基于KBs中的实体,在KBs中类型信息很容易获得。
在驻留中,我们对Freebase中的实体使用FIGER (Ling andWeld, 2012)定义的类型。对于每种类型,我们定义一个kt维的嵌入,我们将其称为实体类型嵌入(h^type)。对于实体在不同上下文中具有多个类型的情况,例如,巴黎可能具有类型government和location,我们取每种类型的嵌入的平均值。在使用目标实体的实体类型进行关系分类之前,我们将目标实体的实体类型嵌入到最终的包表示中。为了避免过度参数化,我们使用38个粗类型,而不是所有细粒度的112个实体类型,形成FIGER类型的第一层次结构。
5.3 Instance Set Aggregation
为了使用所有有效的句子,如下(Lin等人,2016;Jat et al.,2018),我们使用注意重于句子来获得整个bag的表示。我们没有直接使用Section 5.1中的句子表示si,而是将每个句子的嵌入与Section 5.2中的匹配关系嵌入h^rel_i连接起来。第i个句子的注意分值为:

这里q表示一个随机查询向量。包表示法B是句子的加权和,然后连接的实体类型映射进行主体(h^type_sub)和客体(h^type_obj)根据5.2节获得^ B。


6 Experimental Setup
6.1 Datasets
在实验中,我们对Riedel和谷歌远程监控(GIDS)数据集的模型进行了评估。数据集的统计数据汇总在表1中。下面我们详细描述了每一种方法。
1.Riedel: 数据集是由(里德尔et al .,2010)通过调整加热吸用与纽约时报(NYT)语料库的关系,句子从2005年- 2006年用于创建训练集和测试集的2007年。实体提到注释使用斯坦福尼珥(芬克尔et al .,2005)和与毒品有关。该数据集被Hoffmann等人广泛用于RE (Hoffmann et al.,2011;Surdeanu等人,2012年)和最近(Lin等人,2016年;冯et al。He等人,2018年)。
2.GIDS:Jat等人(2018)通过为每个实体对扩展谷歌关系提取微粒2,创建了谷歌远程监控(GIDS)数据集。数据集保证了至少一个多实例学习的假设是成立的。这使得自动评估更加可靠,因此无需人工验证。
6.2 Baselines
为了评估RESIDE,我们比较以下基线:
- Mintz:(Mintz et al., 2009)提出的用于远程监管范式的多类logistic回归模型。
- MultiR:Hoffmann等人2011年提出的多实例学习的概率图形模型
- MIMLRE:一个图形模型,它联合建模多个实例和多个标签。更多细节见(Surdeanu et al., 2012)。
- PCNN:一个基于CNN的关系提取模型(Zeng et al., 2015),使用分段最大池来表示句子。
- PCNN+ATT:一种基于CNN的分段最大汇聚模型(Lin et al., 2016),用于获得句子表示法后的关注重于句子。
- BGWA:基于Bi-GRU的词和句级注意的关系提取模型(Jat et al., 2018)。
- RESIDE:本文提出的方法,请参阅第5节以了解更多细节。
6.3 Evaluation Criteria
根据前期工作(Lin等人,2016;Feng et al)我们使用held-out的评估方案对模型进行评估。这是通过比较从测试文章中发现的关系和Freebase中的关系来完成的。在我们的实验中,我们使用精度召回曲线和top-N精度(P@N)度量来评估模型的性能。
7 Results
在本节中,我们试图回答以下问题:
Q1:对于远程监督RE,RESIDE是否比现有方法更有效?(7.1)
Q2:去除不同组件对RESIDE性能的影响是什么?(7.2)
Q3:在没有关系别名信息的情况下,性能会受到怎样的影响?(7.3)
7.1 Performance Comparison
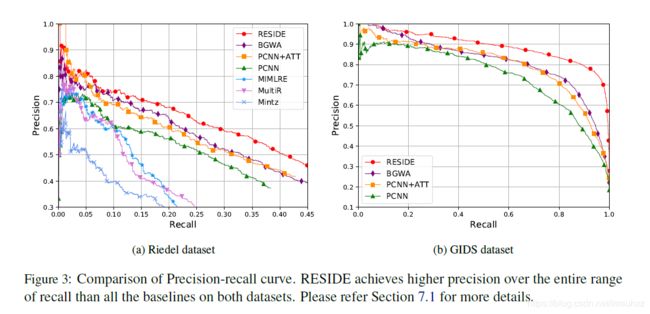
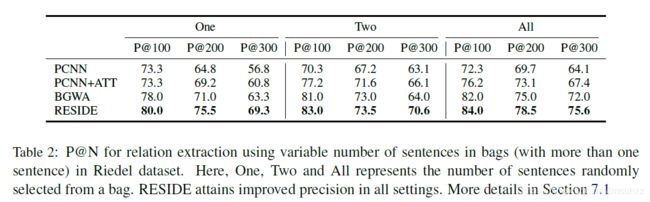
为了评估我们提出的方法的有效性,RESIDE,我们将它与第6.2节中所述的基线进行比较。我们只使用GIDS数据集上的神经基线。Riedel和gid的精度召回曲线如图3所示。总的来说,我们发现RESIDE在两个数据集中的整个召回范围内都达到了更高的精度。所有的非神经基线都不能很好地工作,因为它们所使用的特性大多来自NLP工具,这可能是错误的。RESIDE性能优于PCNN+ATT和BGWA,这表明合并侧信息有助于提高模型的性能。BGWA和PCNN+ATT相对于PCNN的更高性能表明,注意力有助于远距离监督RE。(Liu et al., 2017),我们也用不同的句子数来评估我们的方法。表2总结的结果表明,与神经基线相比,RESIDE在所有测试设置中的精度都有所提高,这说明我们的模型是有效的。
7.2 Ablation Results
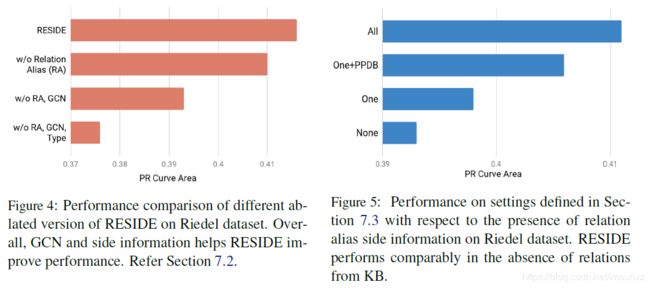
在本节中,我们分析了RESIDE的各种组件对其性能的影响。为此,我们使用累积删除的组件来评估模型的不同版本。实验结果如图4所示。我们观察到,当从RESIDE中删除不同的组件时,模型的性能会急剧下降。结果表明,GCNs对句法信息的编码是有效的。从侧面信息的改进可以看出,它是对文本提取特征的补充,从而验证了本文的中心论点,即诱导侧面信息导致改进的关系提取。
7.3 Effect of Relation Alias Side Information
在本节中,我们将测试模型在关联别名信息不容易获得的情况下的性能。为此,我们在四个不同的设置上评估模型的性能:
- None:关系别名不可用。
- One:关系的名称用作别名。
- One+PPDB:使用释义数据库(PPDB)扩展关系名。
- All:来自知识库的关系别名
总体结果如图5所示。我们发现,当知识库本身提供别名时,模型的性能最好。总的来说,我们发现即使可用的关系别名信息非常有限,RESIDE也能提供竞争性能。我们注意到,随着更多别名信息的可用性的提高,性能会进一步提高。
8 Conclusion
本文提出了一种基于RESIDE的神经网络模型,该模型从知识库出发,有原则地利用实体类型、关系别名等相关边信息,改进了远程监督关系提取。运用图卷积网络对句子的句法信息进行编码,对有限的边信息具有鲁棒性。通过对基准数据集的广泛实验,我们证明了RESIDE在最先进的基线上的有效性。我们已经公开了驻留的源代码,以促进可复制的研究。
Acknowledgements
我们感谢匿名评论者提出的建设性意见。这项工作得到了人力资源发展部(印度政府)、CAIR (DRDO)和谷歌的赞助。
LINK
RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information
github-EMNLP 2018: RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information