上几期我们讲过目标检测 One-Stage 的代表 YOLOv3 本来这一期是打算写 SSD(One-Stage 的另一个代表) 的,发现 SSD 其中涉及的知识是从 R-CNN(Two-Stage)来的,故此。这一期我们就来理理 R-CNN 系列的部分知识点,同样,我们会分为 理论、体验和代码实战 三期来进行讲解,今天就是理论部分。
在开始 R-CNN 系列之前,我们先引入几个概念,有助于后面的理解
选择性搜索( selective search )
作者:J. R. R. Uijlings 2012 提出的
在 Two-Stage 的目标检测中,一般是分为两个步骤,1) 先选取有可能存在目标的候选框,2) 然后对候选框进行预测,判断是否是对应的类别。所以选择性搜索干的就是第一步:选取候选框。当然候选框的选取也有很多算法,比如滑窗等,建议读者去看相应的资料。如下图,选择性搜索就是在输入图中找出可能存在目标的候选框,具体步骤如下:

首先通过将图像进行过分割得到若干等区域组成区域的集合 S,这是一个初始化的集合;然后利用颜色、纹理、尺寸和空间交叠等特征,计算区域集里每个相邻区域的相似度; 找出相似度最高的两个区域,将其合并为新集并从区域集合中删除原来的两个子集。重复以上的迭代过程,直到最开始的集合 S 为空,得到了图像的分割结果,得到候选的区域边界,也就是初始框。
下图就是上述过程的可视化,难怪有大佬会说,学目标检测,应该先学分割,哈哈哈~

RoI Pooling
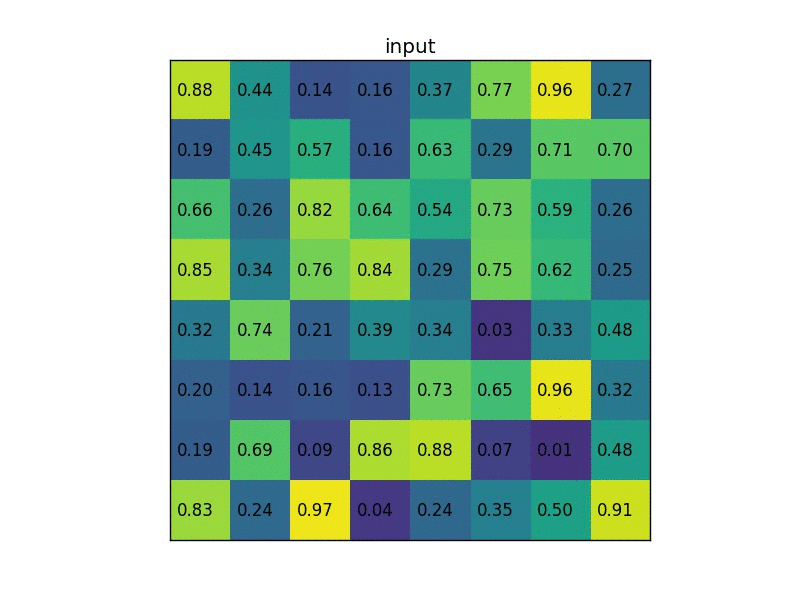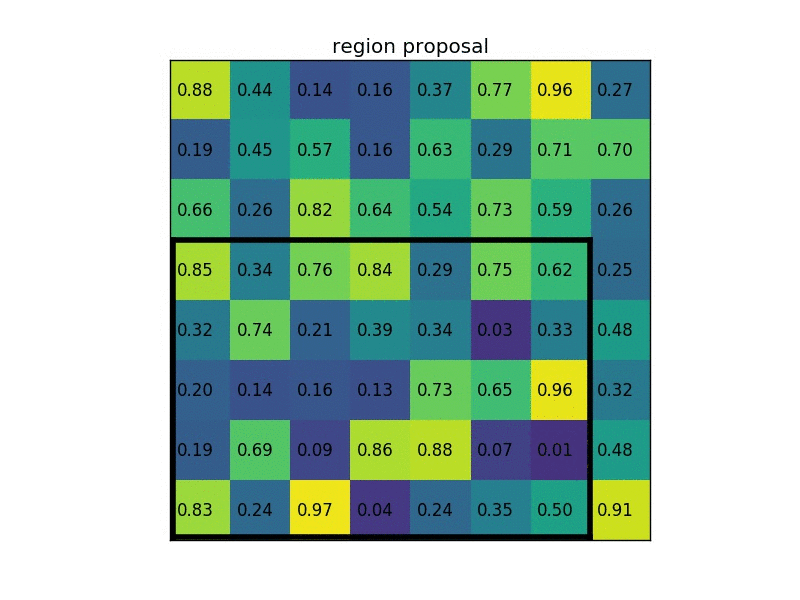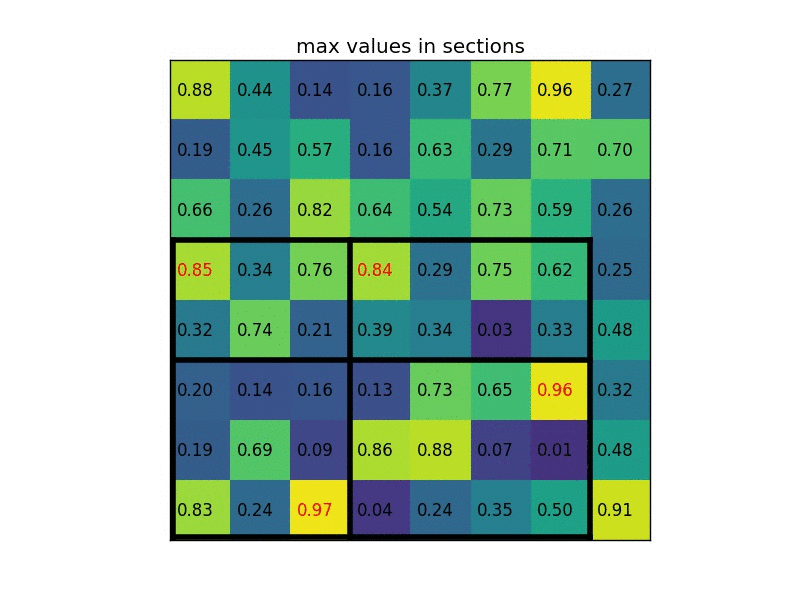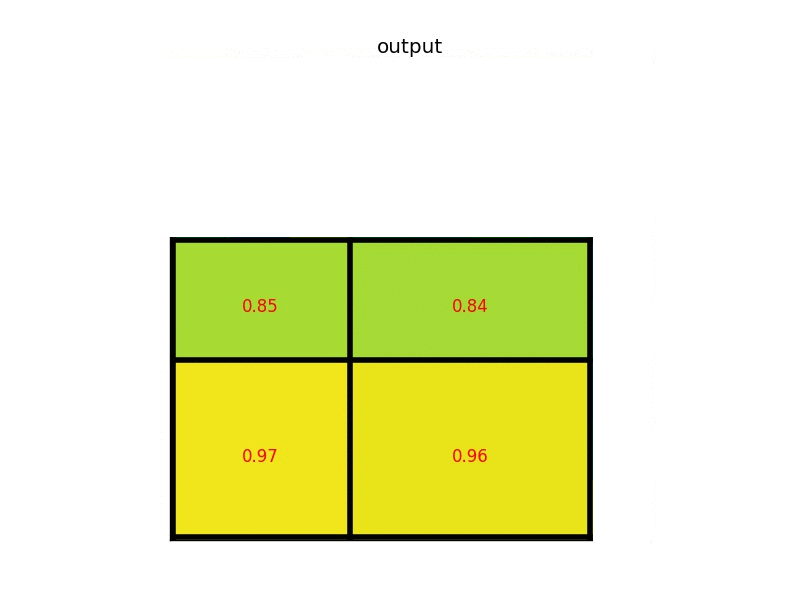
RoI Pooling 全称就是 Region of Interesting Pooling,具体操作如下:
- 原始图片经过特征提取后得到 feature maps,将原图上的 RoI (比如上面选择性搜索得到的候选框)映射到 feature maps 上
- 将映射后的区域划分为相同大小的 sections(sections 数量与输出的维度相同)
- 对不同的 section 做 max pooling 操作
这样我们就可以从不同大小的方框得到固定大小的相应 的 feature maps。值得一提的是,输出的 feature maps 的大小不取决于 RoI 和卷积 feature maps 大小。RoI pooling 最大的好处就在于极大地提高了处理速度。 具体处理的方式如下动图所示:以左上角坐标为 (1,1) ,假设原图上的目标映射到 feature maps 是 (1, 4) ->(7, 8) 将这一块区域经过划分成不同的 section 做 max pooling 。
下面就是 R-CNN 系列的相关知识了
R-CNN:Region-based Convolutional Neural Networks
设计理念
R-CNN 的设计流程如下:
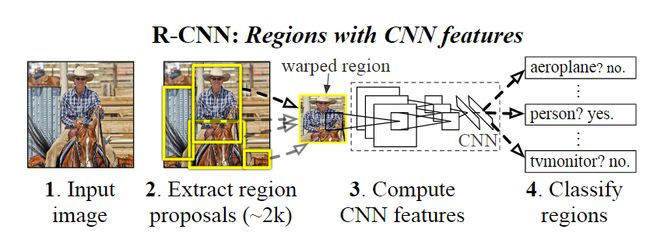
- 通过 selective search 算法在输入原图中找出大约 2000 个框框(因为传统的算法这一步产生了非常多的框,由于很多是无效的,所以导致计算资源浪费)
- 对找出的框框进行缩放操作(因为 CNN 网络包含有全连接层,输出的特征图尺寸需要一样(论文中是 227×227),同时在论文中进行缩放之前会将边框扩大 p=16 个像素),用预训练模型(在 Imagenet 训练的模型)进行特征提取操作(得到 4096 维度的特征),提取的特征保存在磁盘中用于下一步骤。
- 用 20 个(类别数目) SVM (二分类)对每个框框进行类别判别,计算出得分
- 对每个类别的边框做 NMS(非极大值抑制)操作,得到一些分数较高的框
- 分别用 20 个回归器对上述 20 个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的 bounding box。
关键设计点
- 目标区域提案缩放
由于特征提取存在全连接层,故要将目标区域缩放到指定大小,在论文中,使用到了两种缩放方案:
各向异性缩放:比较粗暴的方法:直接 resize 到所需大小
各向同性缩放:(1) 向外扩充至正方形 (2) 用固定的背景颜色填充

- 回归框的设计
以下图检测猫为例,蓝色的框是 selective search 提取出的 region proposal 经过评分以后得到的边框,红色的框是 ground truth。当图中红色的框被分类器识别为猫,但是由于蓝色框的定位不准 (IoU<0.5),相当于没有正确检测出猫。所以为了使定位更准确,即使得 region proposal 更接近于 ground truth,我们可以对蓝色的框进行微调,微调就需要使用 bounding box regression,具体思路如下:

假设下面红色的框 P 是经过评分以后得到的某个类别的边框,蓝色的框是 ground truth ,为了使红色的框去拟合蓝色的框,我们需要找到一种映射关系,就是 平移和缩放,公式如下
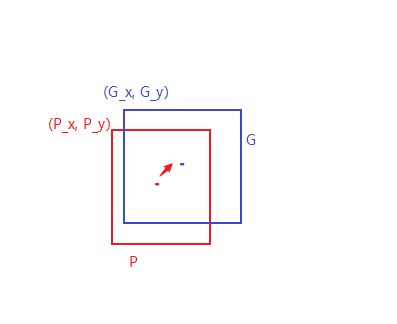

其中


在测试时,根据变换关系进行转换,这里为什么宽高缩放需要进行对数变换可以看文后的考题解答

R-CNN 优缺点
- 优点
- 使用 selective search 方法大大提高候选区域的筛选速度(对比传统算法)。
- 用在 ImageNet 数据集上进行学习的参数对神经网络进行预处理,解决了在目标检测训练过程中标注数据不足的问题。
- 使用 CNN 对 region proposals(候选框) 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
- 通过线性回归模型对边框进行校准,减少图像中的背景空白,得到更精确的定位
- 缺点
- R-CNN 存在冗余计算, 因为 R-CNN 的方法是先生成候选区域,再对区域进行卷积,其中候选区域会有一定程度的重叠,造成后续 CNN 提取特征时出现重复运算,同时,由于 R-CNN 是将提取的特征存储下来,然后用 SVM 进行分类,所以需要大的存储空间
- 由于使用的是 CNN 进行特征提取,所以需要对候选框进行缩放操作,但实际情况是 selective search 方法选取的框有各种尺寸,所以会造成目标变形
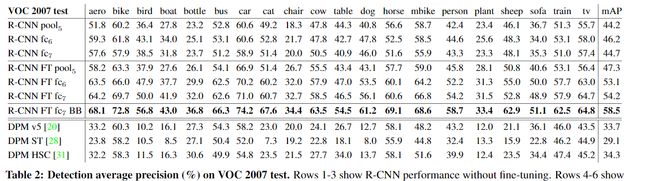
效果
最终 R-CNN 的 mAP 是 58.5%
SPP
SPP 是空间金字塔池化层(Spatial Pyramid Pooling,SPP)的简称。
paper https://arxiv.org/pdf/1406.4729.pdf
设计理念
上一节我们知道,R-CNN 有个缺陷:R-CNN 特征提取的 CNN 网络存在全连接层,所以输入的大小必须经过 crop(裁剪)或者warp (缩放),也就是下图的第一个流程,SPP 的设计理念是在在提取特征的过程中,在卷积层和全连接层之间加了一层空间金字塔池化层(Spatial Pyramid Pooling) 这一层的作用就是将输入图片经过卷积层提取以后得到的不同尺寸的特征图操作成一样的尺寸,保证全连接层的有效输入,如下图的第二个流程。

SPP 的理念不仅可以用在目标检测上面,同时也能用在图像分类上面,当然我们这里只讲目标检测方面的应用,不过设计理念是相通的,具体思路可以看原始论文。下面我们就来讲讲 SPP 的运算过程是怎么样的
SPP 其实就是一系列最大池化操作,那么池化操作就必须有两个参数,窗口的大小 win 和步长 stride,那么这两个是怎么计算的呢?我们需要说明几个变量的含义:
- 金字塔层级的 bins 大小:n×n 。如下图所示的三个正方形(n×n=4×4 蓝色、n×n=2×2 绿色和 n×n=1×1 的灰色正方形)
- conv5 提取的 feature maps 的大小是 a×a(下图那块黑色的东东,a 代表是可以任意值)
我们就以 a×a=13×13 为例来计算 win 的大小和 stride 的大小。win = a/n 向上取整,stride=a/n 向下取整,如 n=4 时 win = 13/4=3.25 向上取整就是 4,stride=13/4=3.25 向下取整就是 3。当 n=2 和 n=1 时计算也是类似。当不同 level 的池化计算结束后,就将其展开成一个向量,如这里的 4×4=16、2×2=4、1×1=1 并将其合并成一个长向量,得到的是一个 21 维度的向量,然后输入后续的全连接层。

在论文中还有张表,不过这里和上面有点不同的是这里第一个 pool 大小是 3×3 的,不过这是不影响的,这其中也可以说明的是,我们可以自行设计 pool 的 level 个数以及 pool 的大小,这其中存在很多人为设计的因素。

效果
SPP 用在分类的精度比较如下所示:

SPP 用在目标检测上的精度比较如下所示:
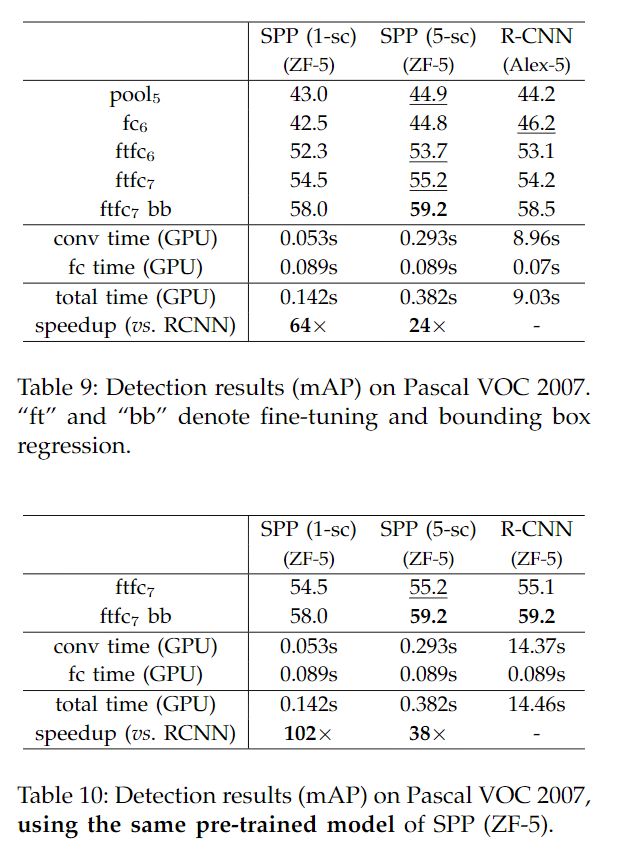
综上可以看出 SPP 的使用虽然在目标检测取得了和 R-CNN 差不多的效果,但是,对于模型来说,使其可以接受更多尺度的输入,其速度也比较 R-CNN 快 24-102 倍
优缺点
- 创新点:计算整幅图像的 the shared feature map,然后根据 object proposal 在 shared feature map上映射到对应的 feature vector(就是不用重复计算feature map了)。
- 缺点:和 R-CNN 一样,训练是多阶段(multiple-stage pipeline)的,速度还是不够"快",特征还要保存到本地磁盘中。
Fast R-CNN
paper: https://arxiv.org/abs/1504.08083
Fast R-CNN 是基于 R-CNN 和 SPPnets 进行的改进。有些理念是相似的,这里就不在赘述。
设计理念
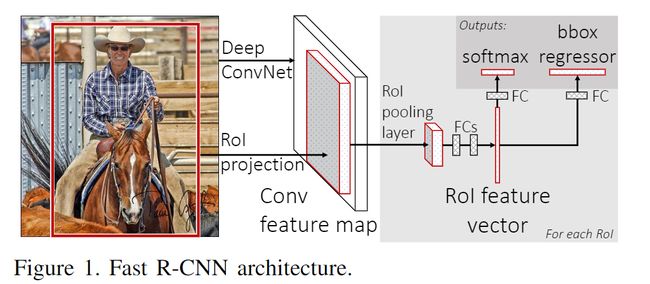
从上面我们知道 R-CNN 有计算冗余的缺陷,我们能不能只需一步就将特征提取出来,而不是根据候选框来提取特征,并且不需要进行特征的保存,Fast R-CNN 就是为这样而设计的(借鉴了 SPP 的思想)
- 对图片输入进行特征提取,得到特征图(整个提取的过程就这一步)
- 也是根据 selective search 算法提取候选框,然后得到的候选框映射到上面提取的特征图上(这里面涉及的知识点也很多,即映射的关系计算,需要再深入理解)
- 由于每个候选框的大小不一样,使用 RoI Pooling操作,得到固定的维度特征,通过两个全连接层,分别使用 softmax 和回归模型进行检测
创新点
- 实现了一次卷积处处可用,类似于积分图的思想,从而大大降低了计算量。
- 用 RoI pooling 层替换最后一层的 max pooling 层,同时引入建议框数据,提取相应建议框特征
- 同时它的训练和测试不再分多步,不再需要额外的硬盘来存储中间层的特征,梯度也能够通过 RoI Pooling 层直接传播。Fast R-CNN 还使用 SVD 分解全连接层的参数矩阵,压缩为两个规模小很多的全连接层。
效果
- 在 VOC07, 2010, and 2012 三个数据集达到了当时最好的 mAP
- 比 R-CNN, SPPnet 更快的训练和测试速度
- 微调 VGG16 的卷积层提升 mAP
Faster R-CNN
paper: https://arxiv.org/abs/1506.01497
设计理念
R-CNN,SPPNet,Fast R-CNN 都没有解决一个问题,就是 selective search 方法低效率的滑动窗口选择问题,它仍然生成了大量无效区域,多了造成算力的浪费,少了则导致漏检。
Faster R-CNN 采用与 Fast R-CNN 相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成 ROI 时效率更高
Faster R-CNN 是深度学习中的 two-stage 方法的奠基性工作,提出的 RPN 网络取代 Selective Search 算法后使得检测任务可以由神经网络端到端地完成。
下面就看看 RPN 的原理是怎么样的:
以一张任意大小的图片作为输入,输出一批矩形区域的提名,每一个区域都会对应目标的分数和位置信息。实际上就是在最终的卷积特征层上,在每个点利用滑窗生成 k 个不同的矩形框来提取区域,k 一般取为 9。
K 个不同的矩形框被称为 anchor,具有不同尺度和比例。用分类器来判断 anchor 覆盖的图像是前景还是背景。对于每一个 anchor,还需要使用一个回归模型来回归框的精细位置。
Faster R-CNN 的主要步骤如下:
- 特征提取:与 Fast R-CNN 相同,Faster R-CNN 把整张图片输入神经网络中,利用 CNN 处理图片得到 feature map;
- 区域提名:在上一步骤得到的 feature map 上学习 proposal 的提取;
- 分类与回归:对每个 Anchor Box 对应的区域进行二分类,判断这个区域内是否有物体,然后对候选框位置和大小进行微调,分类。
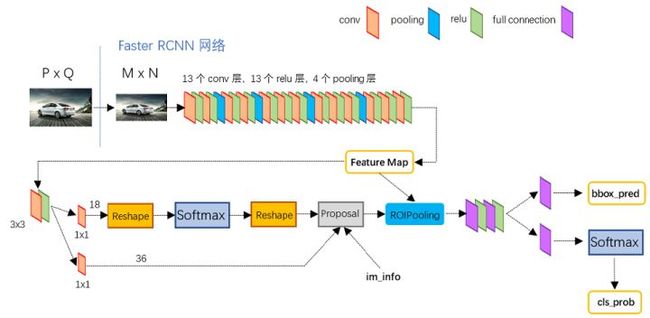
Faster R-CNN 中 RPN 的结构如下:

Faster R-CNN 架构
创新
- 与 selective search 方法相比,RPN 网络将候选区域的选择从图像中移到了 feature map 中,因为 feature map 的大小远远小于原始的图像,此时的滑动窗口的计算量呈数量级的降低。
- 并且 RPNs 和 RoI Pooling 还共用了基础的网络,更是大大地减少了参数量和预测时间。
- 由于是在特征空间进行候选框生成,可以学到更加高层语义的抽象特征,生成的候选区域的可靠程度也得到了大大提高。
考题
(1) rcnn 框架中需要几个 svm 模型?几个边框回归模型?
有多少个类别就需要多少个 svm 模型,多少个回归模型
(2) rcnn 框架中边框回归为什么要做对数变换?使用时有哪些注意事项?
缩放的大小必须大于 0,约束到对数空间方便训练优化
(3) rcnn 框架中 nms 是每一类单独进行还是所有框一起进行?
对每一类单独进行 NMS 操作
(4) rcnn 框架中正负样本如何定义的?为什么 finetune cnn 和训练 svm 时不同?
rcnn 中候选区与 ground truth 的 iou 大于等于 0.5 为正样本,小于 0.5 为负样本。svm 中全部包含了目标体为正样本,iou 小于 0.3 为负样本。finetune 时的正负样本定义是为了增加样本数量,因为 cnn 对小样本容易过拟合,所以需要大量样本训练。svm 是为了提高精度。
(5) rcnn 框架中如何进行难负样本挖掘的?
训练 SVM 时,负样本远远大于正样本,因此,对每个候选区,只有和 ground truth 的 IoU 小于 0.3 的时候,才为负样本。
(6) Fast rcnn 与 SPPnet 的异同点?
- 相同
- 都是使用选择性搜索来得到候选框
- 都只是在原图上提取一次特征
- 不同
- SPPnet 使用的是金字塔结构来解决全连接层输入问题,Fast R-CNN 使用的是 RoI Pooling 解决全连接层输入问题
- SPPnet 还是需要分步骤训练,且需要额外的空间
(7) fast rcnn 框架中正负样本如何定义?
Fast-rcnn 中当候选区与一个 gt 的 iou 大于 0.5 时为正样本,与所有的 gt 的 iou 小于 0.5 时为负样本。
(8) faster rcnn 中 rpn 中使用了多少个回归器?
Faster rcnn 中使用了 9 个回归器,不同尺度长宽比的 ancher 分别对应一个回归器。
(9) faster rcnn 中 rpn 中使用了怎样的正负样本策略?
Faster rcnn 中 iou 大于 0.7 或者与一个 gt 的 iou 最大的 anchor 为正样本,iou 小于 0.3 的 anchor 为负样本。
(10) faster rcnn 中 rpn 和 fast rcnn 是如何训练的?
三种策略,参考 https://zhuanlan.zhihu.com/p/24916624 和论文和代码
纸上得来终觉浅,绝知此事要 coding ~~~~~
参考
- https://zhuanlan.zhihu.com/p/31426458 一文读懂 Faster RCNN 建议看看,大佬写得非常好,强烈推荐
- https://zhuanlan.zhihu.com/p/24916624 Faster R-CNN
- https://zhuanlan.zhihu.com/p/32404424 从编程实现角度学习 Faster R-CNN(附极简实现)
- https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/ 选择性搜索参考 [1]
- https://blog.csdn.net/yuanlulu/article/details/82157071 选择性搜索参考 [2]
- https://blog.deepsense.ai/region-of-interest-pooling-explained/ RoI Pooling 参考 [1]
- https://zhuanlan.zhihu.com/p/73654026 RoI Pooling 参考 [2]
- https://zhuanlan.zhihu.com/p/27485018 SPP 参考
- https://zhuanlan.zhihu.com/p/60794316 回归框设计参考
- https://blog.csdn.net/zijin0802034/article/details/77685438 边框回归参考
- https://mp.weixin.qq.com/s/6DuOc2tJg-vgSMiqKRqnlA 有三 AI:一文道尽 R-CNN 系列目标检测
- https://mp.weixin.qq.com/s/Bnibfng4Sv6qbMk5BEFwnQ 有三 AI:万字长文详解 Faster RCNN 源代码
- [http://noahsnail.com/2018/01/03/2018-01-03-Faster%20R-CNN%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E8%8B%B1%E6%96%87%E5%AF%B9%E7%85%A7/](http://noahsnail.com/2018/01/03/2018-01-03-Faster R-CNN论文翻译——中英文对照/) Faster R-CNN 论文翻译
- https://zhuanlan.zhihu.com/p/69250914?utm_source=wechat_session&utm_medium=social&utm_oi=1010668791688228864 目标检测 ——Faster RCNN 简介与代码注释
- https://github.com/scutan90/DeepLearning-500-questions/
几个代码仓库:
- https://github.com/chenyuntc/simple-faster-rcnn-pytorch
- https://github.com/ruotianluo/pytorch-faster-rcnn
- https://github.com/ShaoqingRen/faster_rcnn
- https://github.com/jwyang/faster-rcnn.pytorch
- https://github.com/open-mmlab/mmdetection