用Spark Streaming+Kafka实现订单数和GMV的实时更新
前言
在双十一这样的节日,很多电商都会在大屏幕上显示实时的订单总量和GMV总额。由于订单数量巨大,不可能每隔一秒就到数据库里进行一次SQL的数据统计,这时候就需要用到流式计算。本文将介绍一个简单的Demo,讲解如何通过Spark Stream消费来自Kafka中订单信息,然后计算订单的数量和金额。
总体流程
一个完整的流程大概如下图所示。
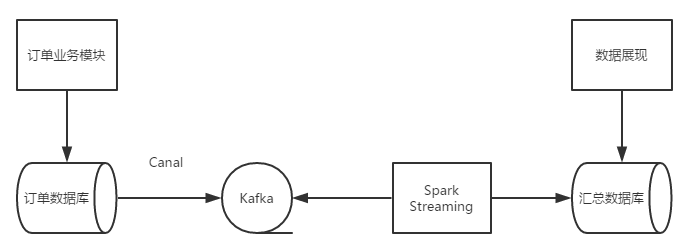
用户下单之后,一笔订单信息会被订单模块写入到关系数据库中,通过监听binlog的变化(可以通过Canal实现),可以解析出数据库的变化,并把刚才刚才新产生的记录写入到kafka的消息队列中。Spark Streaming作为kafka的的一个消费端从卡夫卡中读取订单数据,汇总计算订单的总量和金额的总和,写入到一个特定的汇总数据库中,数据展现层代码从汇总数据库中读取汇总数据进行实施的订单量和GMV总量的展示。
在这个例子中,为了简单起见,会直接写一个Kafka的Producer程序直接往kafka中发送订单信息,同时也把写入汇总数据库的动作用System.out.println来代替(进而也就没有 数据展现层的代码了)
代码实现
首先实现一个Order类来表示一笔订单,在这个Demo中,Order类非常简单,就是两个字段(name,price),分别表示订单中商品的名称和价格。
public class Order {
private String name;
private Float price;
public Order() {
}
public Order(String name, Float price) {
this.name = name;
this.price = price;
}
######省略getter,setter和toString
}
然后是一个向kafka队列中发送订单信息的Producer。这个类也非常简单,只不过是把订单对象转换成Json格式的字符串然后发往Kafka。
public class Producer {
public static void main(String[] args) throws IOException {
// set up the producer
KafkaProducer
ObjectMapper mapper = new ObjectMapper();
try {
InputStream props = Resources.getResource("producer.props").openStream();
Properties properties = new Properties();
properties.load(props);
producer = new KafkaProducer
} catch (Exception e) {
e.printStackTrace();
System.exit(-1);
}
try {
for (int i = 0; i < 100; i++) {
// send lots of messages
Order order = new Order("name" + i, Float.valueOf("" + i));
producer.send(new ProducerRecord
System.out.println("message send " + i);
Thread.sleep(2000);
}
} catch (Throwable throwable) {
System.out.printf("%s", throwable.getStackTrace());
} finally {
producer.close();
}
}
}
然后Spark Streaming作为kafka的Consumer从队列中消费数据,然后对每一个DDR进行转换和统计。代码中进行了详细的注释,应该比较清楚。
public class OrderStreaming {
private static AtomicLong orderCount = new AtomicLong(0);
private static AtomicDouble totalPrice = new AtomicDouble(0);
public static void main(String[] args) {
SparkConf config = new SparkConf()
.setAppName("A spark streaming demo with Kafka resource");
JavaStreamingContext context = new JavaStreamingContext(config, new Duration(5 * 1000));
// context.checkpoint("/tmp/order-analyzer-streaming");
//使用1个进程来处理topic
Map
topicMap.put("spark-test", 1);
//创建来自Kafka数据源的DStream
JavaPairReceiverInputDStream
"ddw-test-3:2181,ddw-test-4:2181,ddw-test-5:2181", //ZooKeeper的地址
"spark-streaming-order", //Consumer的Group ID
topicMap);
//第一次map,将JSON字符串映射为Order对象
final ObjectMapper mapper = new ObjectMapper();
JavaDStream
@Override
public Order call(Tuple2
Order order = mapper.readValue(t2._2, Order.class);
return order;
}
}).cache();
//对DStream中的每一个RDD进行操作
orderDStream.foreachRDD(new VoidFunction
@Override
public void call(JavaRDD
long count = orderJavaRDD.count();
if (count > 0) {
//累加订单总数
orderCount.addAndGet(count);
//对RDD中的每一个订单,首先进行一次Map操作,产生一个包含了每笔订单的价格的新的RDD
//然后对新的RDD进行一次Reduce操作,计算出这个RDD中所有订单的价格众合
Float sumPrice = orderJavaRDD.map(new Function
@Override
public Float call(Order order) throws Exception {
return order.getPrice();
}
}).reduce(new Function2
@Override
public Float call(Float a, Float b) throws Exception {
return a + b;
}
});
//然后把本次RDD中所有订单的价格总和累加到之前所有订单的价格总和中。
totalPrice.getAndAdd(sumPrice);
//数据订单总数和价格总和,生产环境中可以写入数据库
System.out.println("Total order count : " + orderCount.get() + " with total price : " + totalPrice.get());
}
}
});
context.start(); // Start the computation
context.awaitTermination(); // Wait for the computation to terminate
}
}
运行程序
安装有Spark的环境中运行 spark-submit --class "com.wjm.streaming.kafka.OrderStreaming" --master local[4] ./spark-1.0-SNAPSHOT.jar
然后在启动producer类,然后我们可以在控制台中看到 Total order count : 33 with total price : 1671.0 这样的输出。